本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗 。转载本文请联系小姐姐味道公众号。
分布式系统,通过数据冗余,来保证数据的安全。要写一个分布式系统,一道绕不过去的坎,那就是数据同步。
同步,这两个字,折磨死了很多人。
是同步,还是异步?是push,还是pull?谁是master,谁是slave?下线会怎样,上线了又会怎样?中心化,or对等节点?
这些问题,无一不拷打者分布式系统的设计者。
下面,我们将看一下主流的几个存储服务,是如何解决数据同步问题的。
MySQL如何做主从同步?
mysql的主服务器叫做master,从服务器叫做slave。
主服务器将变更记录在binlog中,slave将通过独立的线程拷贝这些记录,然后重放。
binlog的格式分为statement、row、mixed三种。
- statement 将变更的sql语句写入到binlog中,在准确性方面会有一定影响
- row 将每一条记录的变化,写入到binlog中
- mixed 上面两种的结合。MySQL会判断什么时候有用statement,什么时候用row
由于是异步线程去拷贝,slave很容易会出现延迟。当master不幸宕机,将会造成延迟的数据丢失。
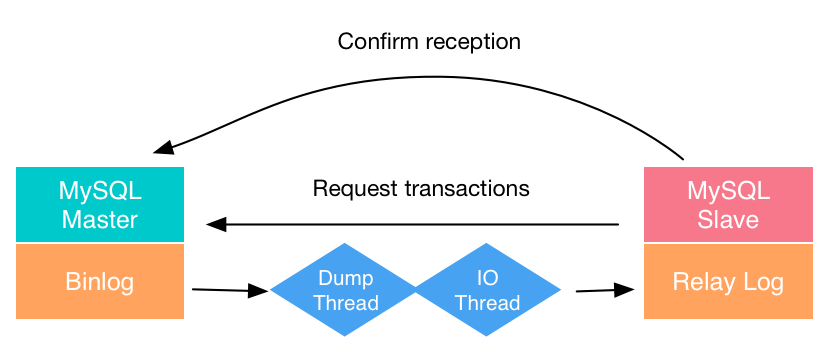
为了解决异步复制的问题,5.5版本之后,MySQL引入了半同步复制(semi sync)的概念。半同步处于异步和全量同步之间,master执行完事务之后,并不直接返回,而是要等待至少一个slave写入成功才返回。由于需要与至少一个slave进行交互,性能相比较异步复制肯定是有不少折损的。
全复制模式当然是要等待所有的slave节点复制完成,这种安全性最高,但是效率也最低。从概念上来讲,只有一个slave的半复制就是全复制。
5.7之后,mysql实现了组复制(group replication)协议。它支持单主模式和多主模式,但在同一个group内,不允许同时存在。听起还好像很神奇,其实它还是通过paxos协议去实现的。
Kafka如何做的副本同步?
kafka由于是一个消息队列,所以不需要考虑随机删除和随机更新的问题,它只关注写入问题即可。从结构上来说,kafka的同步单元是非常分散的:kafka有多个topic,每个topic又分为多个partition,副本就是基于partiton去做的。
主分区叫做leader,1-n个副本叫做follower。生产者在发送消息的时候,需要先找到该分区的leader,然后将数据发送给它。follower只是作为一个备份存在,以便在主分区发生问题时能够顶上去。
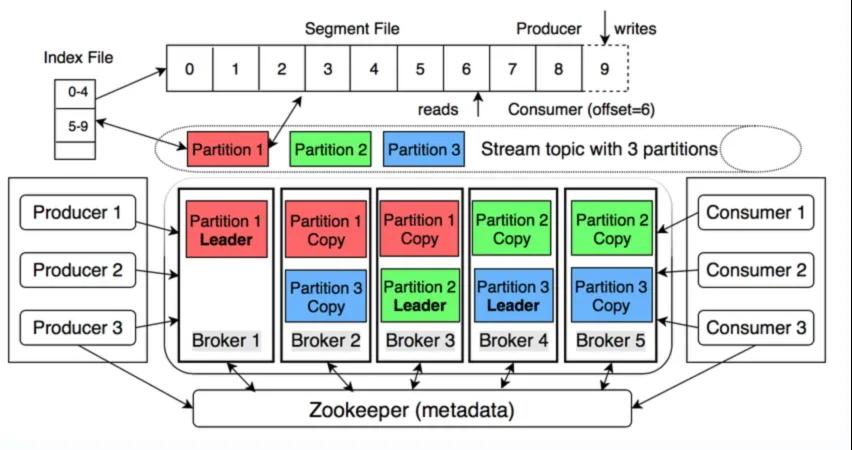
kafka的主从同步,叫做ISR(In Sync Replica)机制。
那什么时候消息算是发送成功呢?这还要看ack的发送级别。
- 0 表示异步发送,消息发送完毕就算是成功了
- 1 leader主副本写入完成,就算是发送成功了
- -1 leader发送完成,并且ISR中的副本都需要回复ack
0和1的情况下,kafka都有丢失消息的可能。在-1的情况下,也需要保证至少有一个follower commit成功才能保证消息安全。如果follower都不能追赶上leader,则会被移除出 ISR列表。没错,是直接移除。当ISR为空,则kafka的分区和单机是没有区别的,所以kafka提供了min.insync.replicas参数规定了最小ISR。
- 当ISR不满足的时候怎么办?kafka当然是不会丢失消息了,因为此时生产者的提交是失败的,消息根本进不了系统里来
- 当所有副本都不可用怎么办?此时,该partition将永不可用
副本之间的数据复制,是通过follower pull的方式,也就是拉取的方式去获取的。
Redis的主从复制
redis是内存kv数据库,速度上远超其他数据库,理论上主从同步更容易。但在高流量和高QPS下,主从复制依然会发生问题。
redis的slave连接上之后,首先会进行一次全量同步。它会发送psync命令到master,然后master执行bgsave生成一个rdb文件。全量同步就是复制这个rdb快照文件到slave。
那在全量复制中间出现的数据怎么办呢?肯定是要缓存起来的。master会开启一个buffer,然后记录全量复制过程中产生的新数据,在全量同步完成之后再补齐增量数据。
slave断线之后也不需要每次都执行全量同步,为了配合增量,还引入了复制偏移量(offset)、复制积压缓冲区(replication backlog buffer)和运行 ID (run_id)三个概念。可以看出它都是为了标识slave,以及它的复制位置和缓冲区用的。
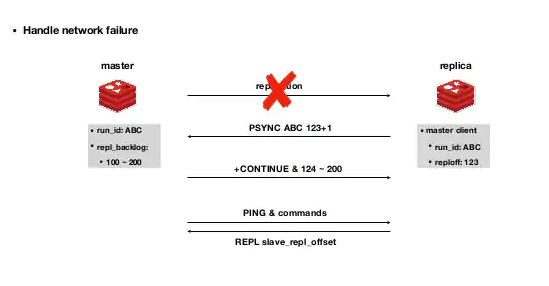
之后的同步,就可以一直使用psync去复制。依然是异步复制。
可以看出redis的主从复制一致性大量依赖内存,级别是非常弱的。但是它快。快能解决很多问题,所以应用场景是不同的。
ElasticSearch主从复制
es是基于lucene的搜索引擎,数据节点会包含多个索引(index)。每个索引包含多个分片(shard),每个分片又包含多个replica(副本)。
从上面的描述来看,这些概念是与kafka高度雷同的,es的复制单元是分片。
es的数据依然是先写master,它同样维护了一个同步中的slave列表(InSyncAllocationIds),处于yellow和red状态的副本当然是不在这个列表中的。
master需要等待所有这些正常的副本写入完成后,才返回给客户端,所以一致性级别是比较高的,因为它的slave节点是要参与读操作的,它是一个近实时系统。
由于它是一个数据库,所以依然会有删除和更新操作。Translog相当于wal日志,保证了断电的数据安全,这和其他rdbms的套路是一致的。
Cassandra集群模式
cassandra是一个非常有名的CAP理论实践数据库,更多的像一个AP数据库,目前在db-engines.com依然有较高的排名。
数据存储是表的概念,一个表可以存储在多台机器上。它的分区,是通过partition key来设计的,数据分布非常依赖于hash函数。如果某个节点出现问题怎么办?那就需要一致性hash的支持。
cassandra非常有意思,它的复制(replicas)并不像其他的主备数据一样,它更像是多份master数据,这些数据都是同时向外提供服务的。当掉一个检点,并不需要主备切换。
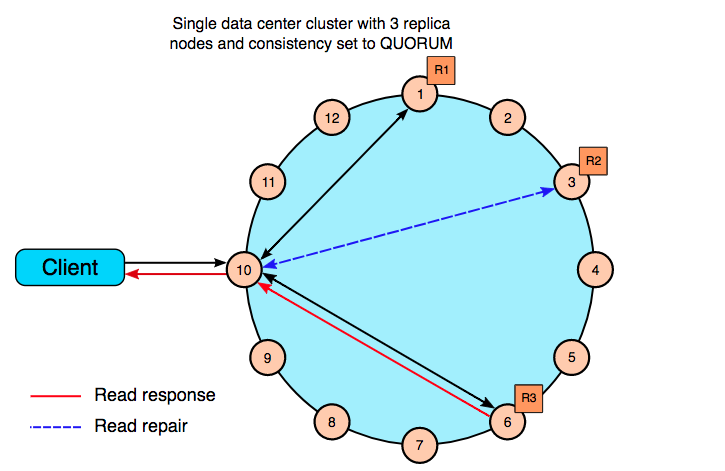
为什么可以做到这种程度呢?因为cassandra追求的是最终一致性。分布式系统由于副本的存在,不可避免的要异步或者同步复制。那到底复制到什么程度才算是合适的呢?Quorum的R+W就是一个权衡策略。
- quorum = (sum_of_replication_factors / 2) + 1
什么意思呢?考虑到你有5个抽屉,然后随机放入W个球,求需要多少次R,才能拿出一个球。假如你向里面放了1个球,你需要打开5次,才能每次都有正确的判断,此时R=5、W=1;当你放了2个球,则你只需要打开4次就可以了;假如你放入了5个球,那就只需要读一次。
当R+W>N的时候,属于强一致性;当R+W<=N的时候,属于最终一致性。
有意思的是,cassandra中的集群信息,即meta信息,使用gossip(push-pull-gossip)进行传递。
MongoDB主从复制
mongodb有三种数据冗余方式。一种是master-slave(不推荐使用),一种是replica set,一种是 sharding模式。
mongodb的副本集主从,就是标准的故障自动转移实现方式,不需要人工介入。master节点当掉之后,会通过选举从副本集中找出新的master节点,然后引导其他节点连接到这个master。
mongodb的选举算法,采用的是bully。
主节点的变更,会存放在特定的系统表中。slave会定时拉取这些变更,并应用。从这种描述中也可以看出,mongodb在同步延迟或者单节点出问题的时候,会有丢失数据的可能。
总结
分布式是为了解决单机的容量问题,但它引入了一个新的问题,那就是数据同步。
数据同步要关注一致性,故障恢复以及时效性。
主要有两种数据需要同步。
- 元数据信息
- 真正的数据
对于元数据信息,目前比较主流的做法,可以参考使用raft协议进行数据分发。到了真正的数据同步方面,raft协议的效率还是有些低的,所以会普遍采用异步复制的方式。
在这种情况下,异步复制列表,就成了关键的元数据信息,集群需要维护这些节点的状态。最坏的情况下,异步复制节点全部不可用,master会自己运行在非常不可信的环境下。
为了增加数据分配的灵活性,这些复制单元多会针对于sharding分片进行操作,由此带来的,就是meta信息的爆炸。
分布式系统这么多,但并没有一个能够统一的模式。有意思的是,即使是最低效的分布式系统,也有大批的追随者。不信?看看BTC的走势就知道了。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。