













本文转载自微信公众号「数仓宝贝库」,作者王恺 等。转载本文请联系数仓宝贝库公众号。
Seaborn是一种开源的数据可视化工具,它在Matplotlib的基础上进行了更高级的API封装,因此可以进行更复杂的图形设计和输出。Seaborn是Matplotlib的重要补充,可以自主设置在Matplotlib中被默认的各种参数,而且它能高度兼容NumPy与Pandas数据结构以及Scipy与statsmodels等统计模式。Seaborn已集成在Anaconda中,无须再次安装。
01关系图
关系图能够直观地展示数据变量之间的关系以及这些关系如何依赖于其他变量,Seaborn中常用的绘制数据关系图的函数是relplot(),其语法格式如下:
seaborn.relplot(*[, x, y, hue, size, style, data, kind, …])
- 1.
参数说明如下:
- data是输入的数据集,数据类型可以是pandas.DataFrame对象、numpy.ndarray数组、映射或序列类型等。
- x和y是参数data中的键或向量,指定关系图中x轴和y轴的变量。
- hue也是data中的键或向量,根据hue变量对数据进行分组,并在图中使用不同颜色的元素加以区分。
- size也是data中的键或向量,根据size变量控制图中点的大小或线条的粗细。
- style也是data中的键或向量,根据style变量对数据进行分组,并在图中使用不同类型的元素加以区分,比如点线、虚线等。
- kind指定要绘制的关系图类型,可选"scatter"(散点图)和"line"(线形图),默认值为"scatter"。
relplot函数提供了几种可视化数据变量之间关系的方法,通过kind参数选择要使用的方法,并通过hue、size和style等参数来显示数据的不同子集。常见的关系图有两种,即散点图和线形图,因此Seaborn还提供了scatterplot和lineplot函数,它们的语法格式如下:
seaborn.scatterplot(*[, x, y, hue, style, size, …])
seaborn.lineplot((*[, x, y, hue, style, size, …]))
- 1.
- 2.
- 3.
scatterplot用于绘制散点图,相当于seaborn.relplot(kind="scatter");lineplot用于绘制线形图,相当于seaborn.relplot(kind="line");其他参数及含义与relplot函数相同。当其中一个变量是连续变量时,更适合使用线形图表示变量之间的关系。
下面通过代码清单1演示如何用Seaborn绘制关系图。
代码清单1 Seaborn绘制关系图的示例
1 import matplotlib.pyplot as plt
2 import seaborn as sns
3 tips= sns.load_dataset("tips")
4 print(tips.head())
5 sns.relplot(x='total_bill', y='tip', data=tips, hue='smoker', style='sex', size='size')
6 plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
程序执行结束后,输出的结果如下:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
<seaborn.axisgrid.FacetGrid at 0x16dea2711f0>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
程序绘制的关系图如图1所示。
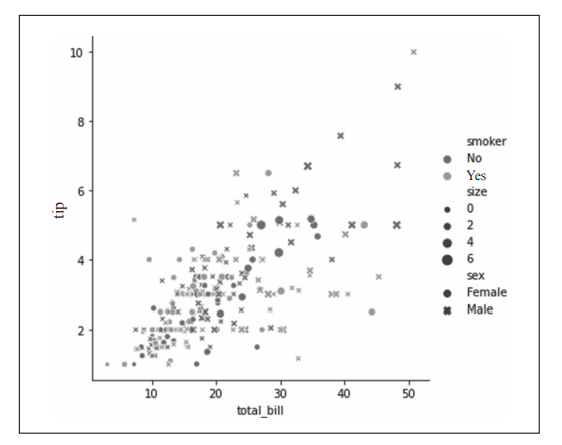
图1 Seaborn绘制散点关系图示例
下面对代码清单1中的代码做简要说明。
- 第2行代码导入seaborn模块并将其重命名为sns。
- 第3行代码通过sns.load_dataset()函数连网加载Seaborn开发者提供的在线样本数据集“tips.csv”,返回值tips是一个DataFrame对象。
- 第4行代码打印tips数据的前5行,以观察数据结构。
- 第5行代码通过sns.relplot()函数绘制total_bill与tip变量的关系图,如图1所示。x坐标为'total_bill'变量,y坐标为'tip'变量;hue='smoker'指定以'smoker'变量对数据点进行分类并以不同颜色显示,不吸烟者对应的数据点是蓝色的,吸烟者对应的数据点为橙色;style='sex'指定以'sex'变量对数据点进行分类并以不同样式显示,女性对应的数据点形状是圆点,而男性对应的数据点形状则是“×”;size='size'指定以'size'变量对数据点进行分类并以不同大小显示。从图6-6中可以进一步分析出不同分类中total_bill与tip的关系。
Tips
sns.load_dataset()函数是连网加载在线数据集,还可以在https://github.com/mwaskom/ seaborn-data网站中将数据集下载到本地使用。
02分布图
分布图可以直观地显示一个或多个变量在某个维度上的分布情况。Seaborn提供了几种常用的绘制分布图的函数,包括displot()、histplot()、rdeplot()、rugplot()、distplot()和jointplot()等。
1. displot()函数
displot()函数提供了几种可视化数据单变量或双变量分布的方法,语法格式如下:
seaborn.displot([data, x, y, hue, row, col, …])
- 1.
主要参数说明如下:
- data是输入的数据集,数据类型可以是pandas.DataFrame对象、numpy.ndarray数组、映射或序列类型等。
- x和y是参数data中的键或向量,指定分布图中x轴和y轴的变量。
- hue是data中的键或向量,根据hue变量对数据进行分组,并在图中使用不同颜色的元素加以区分。
- row和col是data中的键或向量,根据row或col变量提取数据子集,并将子集分布情况绘制在不同的面板上。
- kind指定要绘制的分布图类型,可选"hist"(直方图)、"kde"(核密度估计)、 "ecdf"(经验累积分布函数),默认值为"hist"。
displot函数通过kind参数选择要使用的绘制数据分布情况的方法,并通过hue、row、col等参数来处理不同的数据子集。Seaborn还提供了三个更具体的绘制分布图的函数histplot()、kdeplot()和ecdfplot(),语法格式如下:
seaborn.histplot([data, x, y, hue, weights, stat, …])
seaborn.kdeplot([x, y, shade, vertical, kernel, bw, …])
seaborn.ecdfplot([data, x, y, hue, weights, stat, …])
- 1.
- 2.
- 3.
- 4.
- 5.
- histplot()函数主要用于绘制单变量单特征数据的直方图,相当于seaborn.displot (kind= "hist")。
- kdeplot()函数使用核密度估计绘制单变量或双变量分布,相当于seaborn.displot (kind= "kde")。
- ecdfplot()函数使用经验累积分布函数绘制单变量的分布,相当于seaborn.displot (kind= "ecdf")。
2. rugplot()函数
rugplot()函数的功能是绘制轴须图(毛毯分布图),即通过边缘轴须线的方式显示单个观测点的位置,以补充其他分布图,其语法格式如下:
seaborn.rugplot([x, height=0.025, axis, ax, data, y, hue, …])
- 1.
主要参数说明如下:
x和y分别是x轴和y轴的观测值向量。
- height设置每个观测点对应的轴须细线的高度,默认值为0.025。
- axis指定轴须图绘制的坐标轴,默认为x轴。
- ax指定将图像绘制在已有的axes对象中。
- hue指定区分颜色的分类变量。
3. distplot()函数
distplot()函数整合了Matplotlib的hist()函数与Seaborn的kdeplot()函数的功能,并增加了rugplot()函数绘制轴须图的功能,因此它是一个功能非常强大且灵活实用的绘制分布图函数,其语法格式如下:
seaborn.distplot([a, bins, hist, kde, rug, fit, …])
- 1.
主要参数说明如下:
- a是待观察分析的单个变量,数据类型可以是Series对象、一维数组或列表。
- bins指定直方图显示矩形条的数量,默认值为None,此时会根据Freedman-Diaconis准则自动计算合适的条纹个数。
- hist指定是否绘制直方图,布尔类型,默认值为True。
- kde指定是否绘制高斯核密度估计曲线,布尔类型,默认值为True。
- rug指定是否在支持的数据轴上绘制对应轴须图,布尔类型,默认值为False。
- fit传入scipy.stats中的分布类型,用于在观察变量上抽取相关统计特征来强行拟合指定的分布,并绘制估计的概率密度函数(PDF),默认值为None,即不进行拟合。
下面通过代码清单2演示如何通过Seaborn绘制分布图。
代码清单2 Seaborn绘制分布图的示例
1 import seaborn as sns
2 import matplotlib.pyplot as plt
3 tips= sns.load_dataset("tips")
4 sns.set_theme(style="whitegrid")
5 sns.displot(data=tips, x="total_bill", col="time", row="sex", binwidth=3, height=3, facet_kws= dict(margin_titles=True))
6 plt.subplots()
7 sns.distplot(a=tips['total_bill'], rug=True, hist=False)
8 plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
程序执行结束后,输出的图像如图2和图3所示。
下面对代码清单2中的代码做简要说明。
- 第4行代码通过sns.set_theme()函数设置主题样式为whitegrid,即白色背景和网格线。
- 第5行代码通过sns.displot()函数绘制total_bills变量的分布图,默认绘图样式为直方图。col="time"指定以time变量对数据分组并绘制在不同列,如图2所示,time为Dinner的数据分布绘制在第一列,而time为Lunch的数据分布绘制在第二列;row="sex"指定以sex变量对数据再次分组并绘制不同行,如图2所示,sex为Female的数据分布绘制在第一行,而sex为Male的数据分布绘制在第二行。binwidth=3指定直方图矩形条的宽度为3;height=3指定每个子图面板的高度为3;facet_kws = dict(margin_titles=True)设置每行对应row变量标签绘制在最后一列的右侧。
- 第6行代码通过plt.subplots()函数新建一个Figure对象,用于绘制第二个图像。
- 第7行代码通过sns.distplot()函数绘制total_bill变量的高斯核密度估计曲线,rug=True表示要绘制对应的轴须图,hist=False表示不绘制直方图,kde默认值为True,即绘制高斯核密度估计曲线,如图3所示。
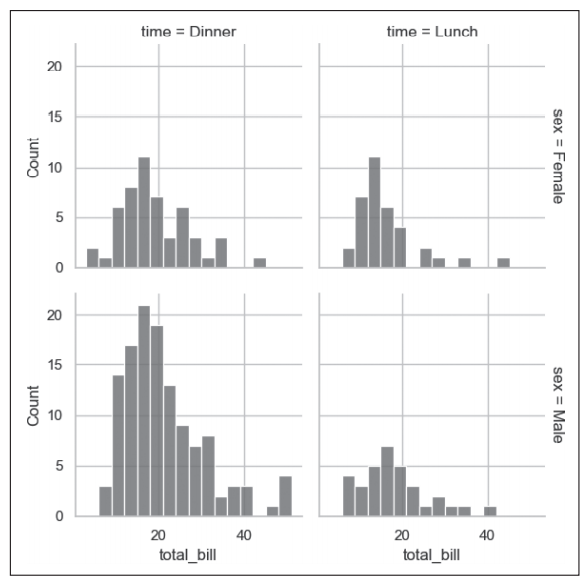
图2 seaborn.displot函数绘制分布图示例
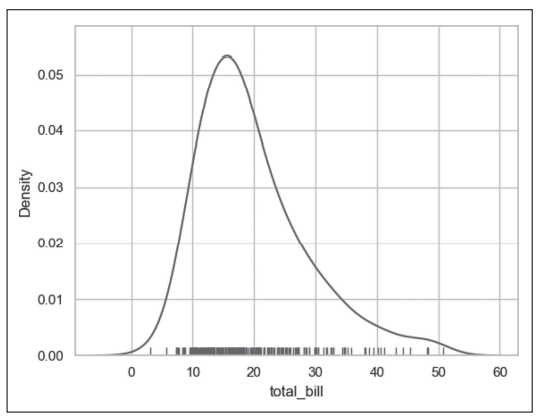
图3 seaborn.distplot函数绘制高斯核密度估计曲线示例
4. jointplot函数
seaborn.jointplot()函数提供了几种绘制两个变量的联合分布图的方法,其语法格式如下:
seaborn.jointplot(*[,x,y,data,kind,color,...])
- 1.
主要参数说明如下:
- data是输入的数据集,数据类型可以是pandas.DataFrame对象、numpy.ndarray数组、映射或序列类型等。
- x和y是参数data中的键或向量,指定分布图中x轴和y轴的变量。联合分布图是双向绘制的,即两个变量分别以对方作为自变量绘制分布图。
- kind指定绘制主分布图的类型,可选择值为"scatter"(散点图)、"kde"(核密度估计曲线)、"hist"(直方图)、"hex"(六边形图)、"reg"(回归图)或"resid"(线性回归残差图),默认值为"scatter"。
- color指定图像中元素的颜色。
下面通过代码清单3演示如何通过jointplot函数绘制分布图。
代码清单3 jointplot函数绘制分布图的示例
1import seaborn as sns
2import matplotlib.pyplot as plt
3tips = sns.load_dataset("tips")
4sns.set(style="white") #设置风格样式
5sns.jointplot(x="total_bill", y="tip", data=tips)
6plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
程序执行结束后,输出的图像如图4所示。
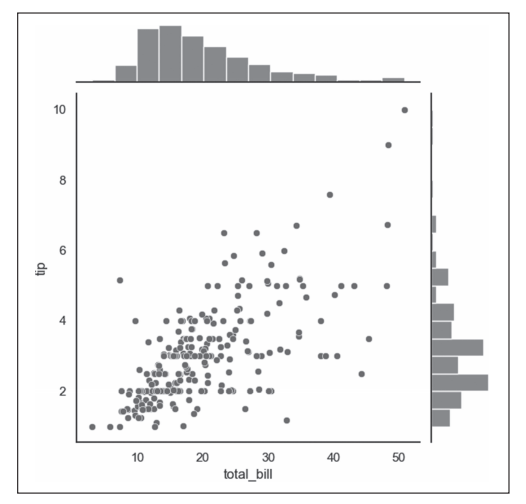
图4 jointplot函数绘制联合分布图示例
下面对代码清单3中的代码做简要说明。
- 第4行代码通过sns.set()函数设置主题样式为white,即白色背景无网格。
- 第5行代码通过sns.jointplot()函数绘制total_bill和tip变量的联合分布图,如图5所示。中间的主分布图默认为散点图,显示total_bill和tip变量之间的关系。主图上方对应绘制x轴变量total_bill的直方图,主图右侧则对应绘制y轴变量tip的直方图。
03分类图
分类图展示数据根据特定变量进行分类后的统计情况。常用的分类图包括分类散点图、箱形图、条形图等。Seaborn的catplot()函数提供了几种不同的分类可视化方法,以便显示数值变量与一个或多个分类变量之间的关系,常用语法格式如下:
seaborn.catplot(*[,x,y,hue,data,row,col,kind,...])
- 1.
参数说明如下:
- data是输入的数据集,数据类型只能是长格式的pandas.DataFrame对象,即每一列对应一个变量,每一行对应一个观察值。
- x和y是data数据集中的变量名,指定分类图中x轴和y轴的变量。
- hue也是data数据集中的变量名,根据hue变量对数据进行分组,并在图中使用不同颜色的元素加以区分。
- row和col也是data数据集中的变量名,作为分类变量提取数据子集,并将子集分布情况绘制在不同的面板上。
- kind指定要绘制的分类图类型,可选类型有"strip"(带状图)、"swarm"(分簇散点图)、"box"(箱形图)、"violin"(小提琴图)、"boxen"(增强箱形图)、"point"(点估计)、"bar"(条形图)或"count"(计数条形图),默认值为"strip"。
catplot()函数通过kind参数选择要使用的绘制数据分类的方法,并通过hue、row、col等参数来处理不同的数据子集。Seaborn还提供了三类更具体的绘制分类图的函数,包括分类散点图、分类分布图和分类预测图。
1.分类散点图函数
分类散点图函数包括stripplot()和swarmplot(),常用的语法格式如下:
seaborn.stripplot(*[, x, y, hue, data, order, …])
seaborn.swarmplot(*[, x, y, hue, data, order, …])
- 1.
- 2.
- 3.
seaborn.stripplot(*[,seaborn.swarmplot(*[,stripplot()相当于seaborn.catplot(kind= "strip"),可以显示测量变量在每个类别的分布情况,绘制的散点呈带状,数据较多时会有重叠的部分。
swarmplot()相当于seaborn.catplot(kind= "swarm"),它与stripplot()类似,但绘制的数据点不会重叠。
2.分类分布图函数
分类分布图函数包括boxplot()、violinplot()和boxenplot(),常用的语法格式如下:
seaborn.boxplot(*[, x, y, hue, data, order, …])
seaborn.violinplot(*[, x, y, hue, data, order, …])
seaborn.boxenplot(*[, x, y, hue, data, order, …])
- 1.
- 2.
- 3.
- 4.
- 5.
- boxplot()相当于seaborn.catplot(kind= "box"),用于绘制箱形图以显示与类别相关的分布情况,可以显示四分位数、中位数和极值。
- violinplot()相当于seaborn.catplot(kind= " violin "),结合了箱形图和核密度估计图。
- boxenplot()相当于seaborn.catplot(kind= "boxen"),用于为更大的数据集绘制增强箱形图。
3.分类预测图函数
分类预测图函数包括pointplot()、barplot()和countplot(),常用的语法格式如下:
seaborn.pointplot(*[, x, y, hue, data, order, …])
seaborn.barplot(*[, x, y, hue, data, order, …])
seaborn.countplot(*[, x, y, hue, data, order, …])
- 1.
- 2.
- 3.
- 4.
- 5.
- pointplot()相当于seaborn.catplot(kind= "point"),使用散点图符号显示点估计和置信区间。
- barplot()相当于seaborn.catplot(kind= "bar"),使用条形图显示点估计和置信区间。
- countplot()相当于seaborn.catplot(kind= "count"),使用条形图显示每个分类中的观察值计数。
下面通过代码清单4演示如何通过Seaborn绘制分类图。
代码清单4 Seaborn绘制分类图的示例
1 import seaborn as sns
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 tips = sns.load_dataset("tips")
5 sns.set_theme(style="whitegrid")
6 f = sns.catplot(data=tips, kind="bar",x="day", y="total_bill", hue="smoker")
7 f.despine(left=True)
8 f.set_axis_labels("day", "total_bill")
9 f.legend.set_title("smoker")
10 plt.subplots()
11 sns.boxplot(x="day", y="total_bill", data=tips)
12 plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
程序执行结束后,输出的图像如图5和图6所示。
下面对代码清单4中的代码做简要说明。
- 第6行代码通过sns.catplot()函数针对数据集tips绘制分布图,kind="bar"指定绘制条形图;x="day"指定x坐标为day变量,即根据day变量对数据集进行分类;y="total_bill"指定y坐标为total_bill变量,即显示total_bill变量的统计情况;hue="smoker"指定以smoker变量对数据点进行分类并以不同颜色显示,如图5所示,smoker值为No的对应数据条是蓝色的,smoker值为Yes的对应数据条是棕色的。返回值f是FacetGrid对象。
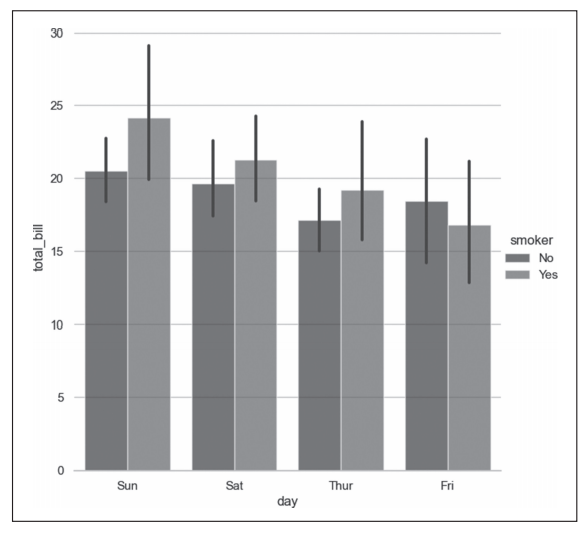
图5 seaborn.catplot()函数绘制分类图示例
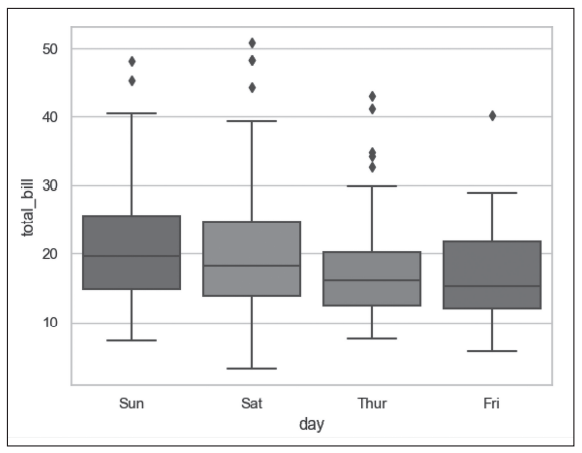
图6 seaborn.boxplot()函数绘制箱形图示例
- 第7行代码通过f.despine(left=True)设置移除f左侧的y轴轴线。
- 第8~9行代码分别设置x轴标签为day,y轴标签为total_bill,图例标题为smoker。
- 第10行代码通过plt.subplots()函数新建一个Figure对象。
- 第11行代码通过sns.boxplot()函数绘制箱形图,同样指定x坐标为day变量,指定y坐标为total_bill变量,结果如图6所示。
04回归图
回归图是使用统计模型估计两个变量间的关系。Seaborn提供了常用的绘制回归图的函数regplot()和lmplot()。regplot()函数的功能是绘制数据和线性回归模型拟合的曲线,常用的语法格式如下:
seaborn.regplot(*[, x, y, data, x_estimator, …])
- 1.
主要参数说明如下:
data是输入的数据集,数据类型是DataFrame对象,即每一列对应一个变量,每一行对应一个观察值。
x和y是输入变量,数据类型可以是字符串、Series对象或者向量数组等。如果是字符串,则与data中的列名相对应。如果是Pandas对象,则坐标轴被标记为Series名称。
lmplot()函数结合了regplot()和FacetGrid的功能,为绘制数据集的条件子集的回归模型提供接口,语法格式如下:
seaborn.lmplot(*[, x, y, data, hue, col, row, …])
- 1.
主要参数说明如下:
- data是输入的数据集,数据类型是DataFrame对象,即每一列对应一个变量,每一行对应一个观察值。
- x和y是输入变量,数据类型是字符串,与data中的列名相对应。
- hue、col和row是划分数据子集的变量,这些子集将绘制在网格中的不同面板上。
regplot()和lmplot()函数密切相关,两者主要的区别是:regplot接受各种类型的x和y参数,包括numpy arrays 、pandas.series 或者pandas.Dataframe对象;而lmplot()的x和y参数只接受字符串类型。
下面通过代码清单5演示如何通过Seaborn绘制回归图。
代码清单5 Seaborn绘制回归图的示例
1 import seaborn as sns
2 import matplotlib.pyplot as plt
3 tips = sns.load_dataset("tips")
4 sns.regplot(x="total_bill", y="tip", data=tips)
5 sns.lmplot(x="total_bill", y="tip", hue="smoker",col='sex', data=tips)
6 plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
程序执行结束后,输出的图像如图7和图8所示。
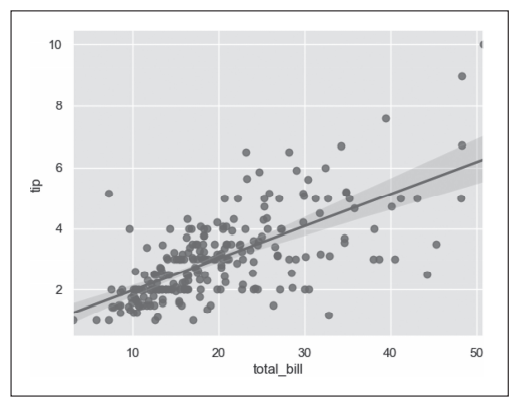
图7 seaborn.regplot()函数绘制回归图示例
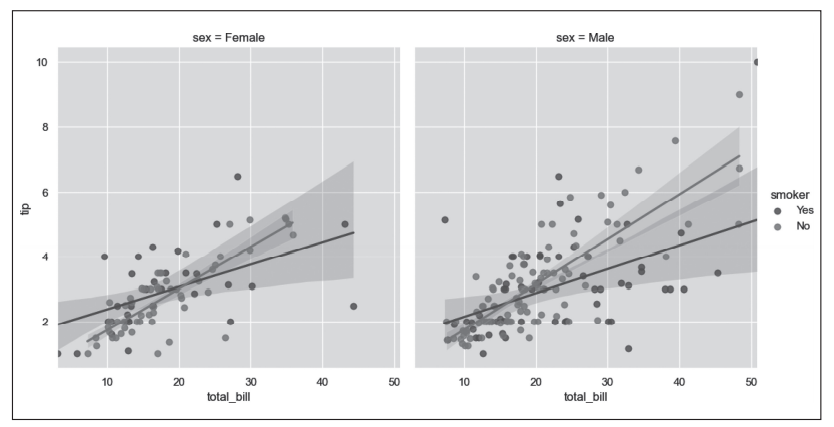
图8 seaborn.lmplot()函数绘制回归图示例
下面对代码清单5中的代码做简要说明。
- 第4行代码通过sns.regplot()函数绘制回归图,指定x坐标为total_bill变量,指定y坐标为tip变量,其他设置采用默认值,结果如图6-12所示,绘制出了total_bill和tip变量之间的线性拟合曲线,同时实际数据以散点的形式显示。
- 第5行代码通过sns.lmplot()函数在一个Facegrid对象中绘制total_bill和tip的回归曲线;hue="smoker"指定以smoker变量对数据点进行分类并以不同的颜色显示,如图8所示,smoker值为No的数据点和拟合直线是蓝色的,smoker值为Yes的数据点和拟合直线是橙色的;col='sex'指定以sex变量对数据再次分组并绘制在不同列,如图8所示,sex为Female的数据分布绘制在第一列,sex为Male的数据分布绘制在第二列。
05热力图
热力图是将不同的数据值用不同的标志加以标注的一种可视化分析手段,标注的手段一般包括颜色的深浅、点的疏密以及呈现比重的形式。在数据分析中,如果离散数据波动变化比较大,那么可以使用热力图来观察波动变化。
Seaborn提供的heatmap()函数可以为二维数据绘制由颜色编码矩阵组成的热力图,语法格式如下:
seaborn.heatmap(data, *[, vmin, vmax, cmap, center, …])
- 1.
主要参数说明如下:
- data是输入的二维矩形数据集,数据类型可以是DataFrame对象或二维ndarray数组等。
- vmin和vmax指定colormap的值,数据类型为float,默认值根据数据或其他关键参数来决定。
- cmap指定数据值到颜色空间的映射,数据类型可以是Matplotlib colormap名称或对象、颜色列表等。
- center指定在绘制发散数据时颜色映射的居中值,数据类型为float。
下面通过代码清单6演示如何通过Seaborn绘制热力图。
代码清单6 Seaborn绘制热力图的示例
1 import numpy as np
2 import seaborn as sns
3 import matplotlib.pyplot as plt
4 np.random.seed(0)
5 uniform_data = np.random.rand(10, 12)
6 sns.heatmap(uniform_data)
7 plt.show()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
程序执行结束后,输出的图像如图9所示。
图9 seaborn.heatmap()函数绘制热力图示例
下面对代码清单6中的代码做简要说明。
- 第4~5行代码通过numpy.random.rand函数随机生成了10×12的二维数组uniform_data。
- 第6行代码通过sns.heatmap()函数以热力图的形式展示uniform_data的数值变化。
本文摘编于《Python数据分析与应用》,经出版方授权发布。























