本文转载自微信公众号「董泽润的技术笔记」,作者董泽润 。转载本文请联系董泽润的技术笔记公众号。
换换口味今天不写纯技术文章,分享一个 high level 的话题。假如公司或部门的微服务频繁出现故障,Boss 让你去负责稳定性建设,俗称救火队长,你会怎么做???
这个问题可以当做面试题,考验候选者是否有全局的视野,以及对整个技术栈的掌握情况。同时需要多维度思考,产品,工程师,服务,基础机构等等。
整体来讲和上图的灭火原理是一样,灭明火、定期检查设备、防火演练。稳定性建设也分为三步:短期故障处理、中期构建稳定性、长期演练压测。
短期故障处理
1.灭明火
火烧眉毛了,正在发生的问题要及时处理,至少要先 mitigate 减轻影响面。不能影响核心的订单创建流程,稍慢一点都没关系,能降级的优先降级,保证核心链路
如果是因为上线导致的故障,要及时回滚,在线找原因不可取。
2.功能冻结
由于这是特殊时期,从产品角度考虑:冻结 freeze 一切开发功能上线,除了 bug fix 以及非常重要的变更,需要 boss 审批。同时每次上线至少征得 leader 及稳定性负责人的审批
3.它山之石
复盘所有短期内的故障,我们叫做 postmortem 验尸报告。把故障发生的原因,处理过程,后续 Todo Actions 全部总结分析一遍,并且跟踪后续的落实情况
最重要的是推广到其它服务,比如基本上每个公司都出过域名过期、没有限流接口被打爆,真的非常夸张
4.服务
对于服务来讲,短期需要检查所有内容:
- 设置合理的超时时间,比如好多用 python requests 库不设超时
- 每个接口设置合理的限流,保护自己
- 调用第三方设置熔断 circuit breaker, 保护别人
- 检查重试逻辑,你要做的是重试,不是 flood 下游
- 增加报警,很多时候有报警就能提前发现问题
毫不夸张的说,做到以上步骤,能杜绝 90% 的故障。尤其是 ratelimiter/circuit breaker, 就能很好的避免大部份的级联故障
中期构建稳定性
中期能做的事情情非常多,由于不紧急,需要慢慢来最考验细节
1.产品优化
这一点是很多 enginner 不具备的素质,需要产品经理一起来梳理业务流程。很多时候,一个业务形态上的优化,远远超过工程师做的很多努力,而恰恰这个产品功能可能是最脏的
广义来看,我们又是自己服务的产品经理。比如原来双写的逻辑,是否可以用第三方同步工具来完成?这样就能做到服务的 clean
2.服务架构优化
随着功能的不断迭代,原有的架构设计己经不再适用。简单的说,服务于 10w 订单的架构,再怎么加机器,也无法适用 1000w 订单的场景,有幸接触了走过这一步的滴滴分单架构
对于具体服务能做的非常多:
- 比如 ut 覆盖率要到一定指标,就算有全链路压测,也不代表代码所有逻辑分支都是正确的。
- 另外一个重要的就是服务要划分等级,比如 p0, p1, p2 等等,当出故障时要优先保证 critical 服务的 QOS,舍弃低等级服务
- 服务也要做好 fallback 逻辑,比如 eta 请求地图服务,假如地图服务不可用,那么要用路面距离做 fallback 等等
- 可观察测性 observerbility,dashboard 是否足够,metrics 指标是否全面
- 排查隐患,墨菲定律无处不在,你能想像到会出故障的点,比如 SPOF, 只要时间足够长,一定会爆
3.上线流程
这里涉及到公司的 CI/CD, 工具是否好用,健壮,稳定。上线要有 canary 灰度,全量上线也要有分组,给工程师留足够的观察期,而不是一把梭哈。同时定期使用 rollback, 确保回滚功能可用(都是泪,别问我为什么)
可以想像下,一个服务有 100 台机器,灰度没问题,就代表真的没问题嘛?不可能的,所以全量上线也要分组,把控制权交给工程师
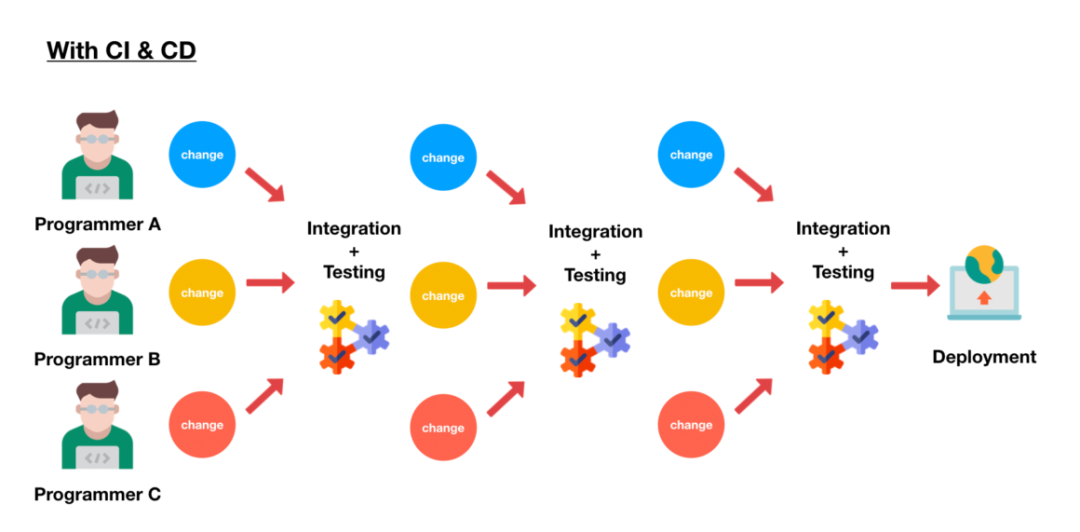
对于 enginner 来讲,要培养风险意识,上线要观察日志,查看 dashboard. 要全面观察服务的健康状态,cpu, latency 正常服务没问题了嘛?肯定不是的,同时要注意新功能是否会 flood 下游服务,做好评估
4.技术评审
很多公司都有技术委员会,别的不说,至少 58 有的。公司级别的一般负责晋升多一些,所以需要每个部门也有同样的人员
最重要的就是评审方案,是否设计的不够,过度设计,选型太过于激进。举个例子,100年前,mongodb 刚出的时候,公司就用 mongodb 替换掉了 mysql, 那时的 mongodb db 级别锁,没有事务...
长期演练压测
关于长期要做的工作也非常多,由于涉及所有开发部门,基础架构,以及运维团队,所以需要专职 team 长期负责,定期复盘总结
1.全链路压测
目前来看 alibaba 是做的最好的,我接触过最多的是在滴滴,涉及的细节特别多。通过压测能提前发现很多业务的瓶颈
压测工具的开发也是个大工程,我记得当时说要演练每次工具都出故障,大家干等几小时
滴滴以前的做法,是在太平洋小岛 mock 假的打车需求,各个服务都需要做相应的改造,包括 mysql 要创建影子表 shadow table, 服务针对压测请求要做区分等等
前几天曹大分享了文章,为什么有的公司不写 UT 线上也比较稳定,一个原因就在于入口处有全链路压测
2.冒烟 chaos
冒烟测试,混沌测试目的就是在线上搞破坏,找到弹性不好的服务及模块。比如磁盘 IO 不稳定,机器突然宕机,时间突然回卷等等
之前 pingcap 分享过 chaos 注入结束后,服务 QPS 没有回到正常水平的问题。感兴趣的可以去看看
3.服务 runbook 定期演练
这一点我体会非常深,就像消防员定期检查装备,然后测试灭火一样。服务要针对特定的问题,定制好 runbook, 毕竟维护服务的工程师是流动的,今天是 owner, 明天就移交给 tom 了
我们的服务依赖 etcd, 大家也知道机器挂掉概率虽然低,但是预期之中的。所以我们编写了 runbook, 滚动升级 etcd, 移除添加故障节点等等,非常好用,新手按照流程走就可以
4.人员素质
长期建设里最重要的就是人员素质建设,有的人上线完成后,不看日志,不检查 grafana, 我们不是 blame 这个人,可能工程 sense 就是差了一点
人员素质建设,方方面面太多的,软素质硬素质。最直观的就是代码能力,防御编程应该深入每个 enginner 的骨髓
5.Infra建设
跳出 engineer 的视野,从公司的角度来看,一个 idc 或是云厂商是不够的。国内提的最多的是两地三中心, 多活设计。其实这个很难,大部份公司的都是假多活,主机房挂了全部完蛋
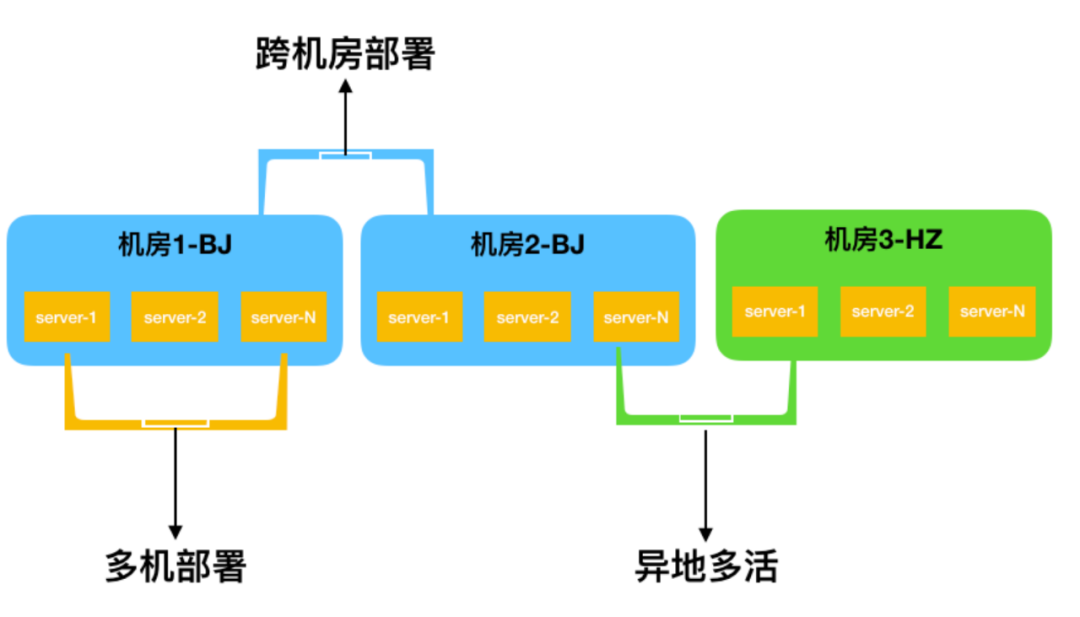
但是水灾,火灾这个事谁能保证就不发生呢?至少数据要做到多地备份,服务可以挂,数据没了公司一定会倒闭。当年天津港的事印象特别深,微信 IDC 的负责人做的非常漂亮,这事不能多说,感兴趣的可以去搜
小结
稳定性建设话题非常大,需要视野看得远一些,但也不能太虚,要有可执行性,每一步都要细化到文档,总结成流程与制度。