













当我们定义一个函数时,是返回结构体呢,还是返回指向结构体的指针呢?
对于这个问题,我想大部分人的回答,肯定都是返回指针,因为这样可以避免结构体的拷贝,使代码的效率更高,性能更好。
但真的是这样吗?
在回答这个问题之前,我们先写几个示例,来确定一些基本事实:
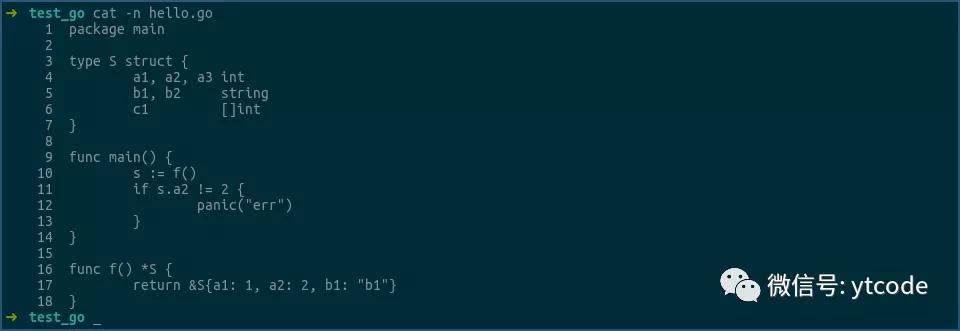
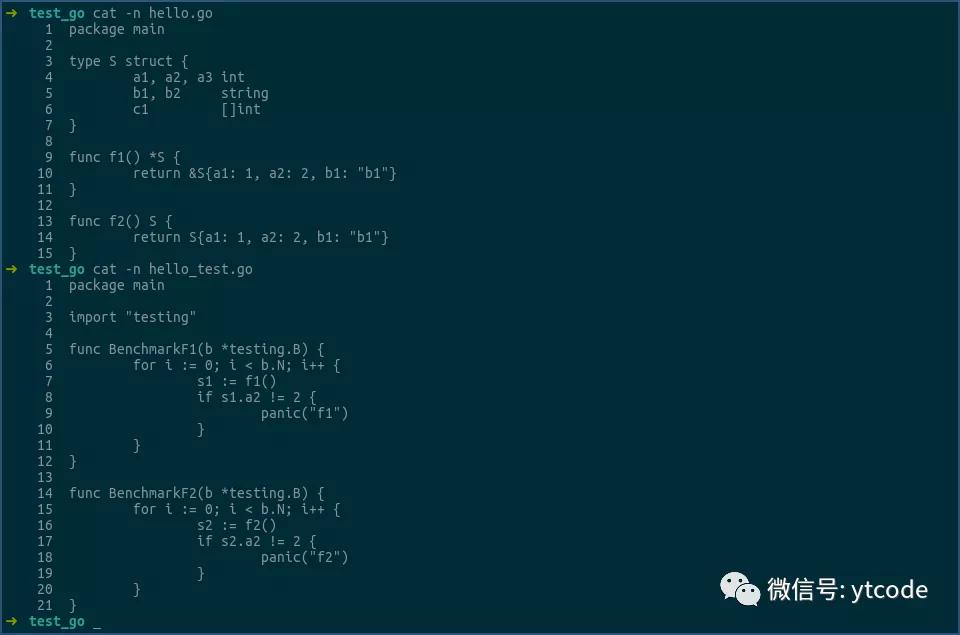
上图中,函数f返回的是结构体S的指针,即一个地址,这个可以通过其汇编来确认:
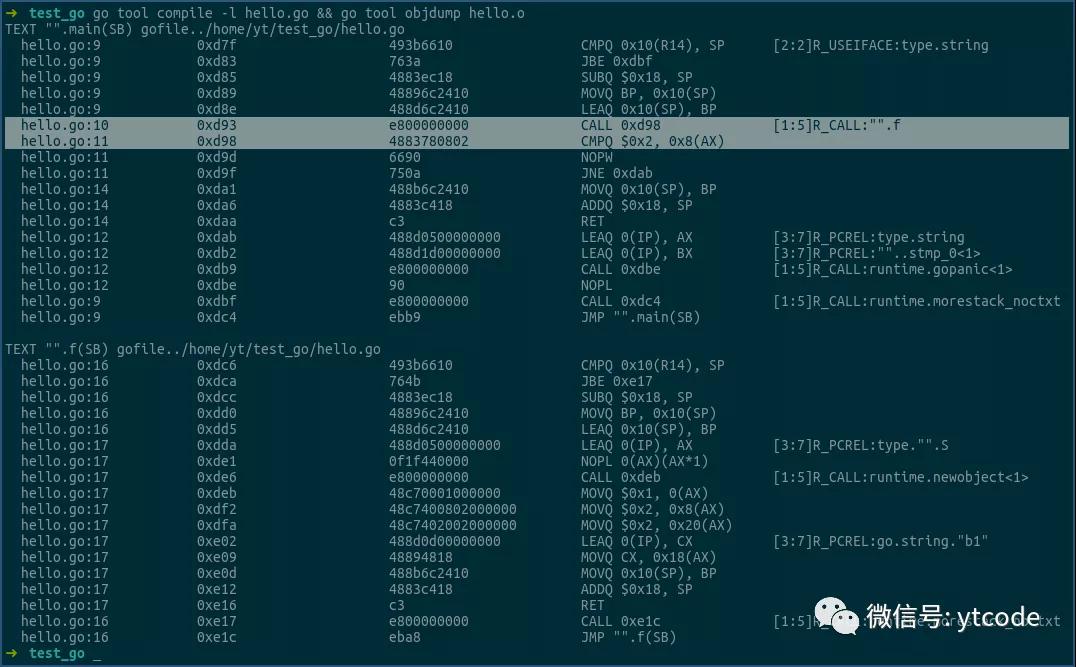
看上图中的选中行。
第一行是调用函数f,其结果,即结构体S的指针,或结构体S的地址,是放到ax寄存器中返回的。
第二行用0x8(ax),即ax中的地址加8的形式,来获得结构体S中a2字段的值,然后将该值和0x2相比,以进行后续逻辑。
由此可见,返回结构体指针的形式,确实是只传递了一个地址。
我们再来看下返回结构体的情况:
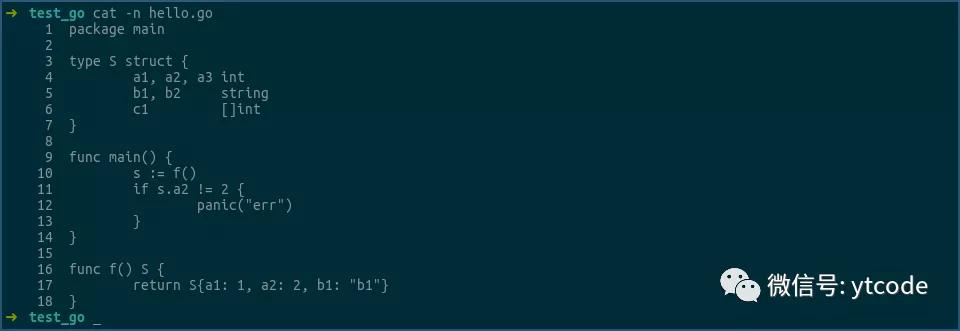
这次函数f返回的是S,而不是*S,看看这样写其汇编是什么样子:
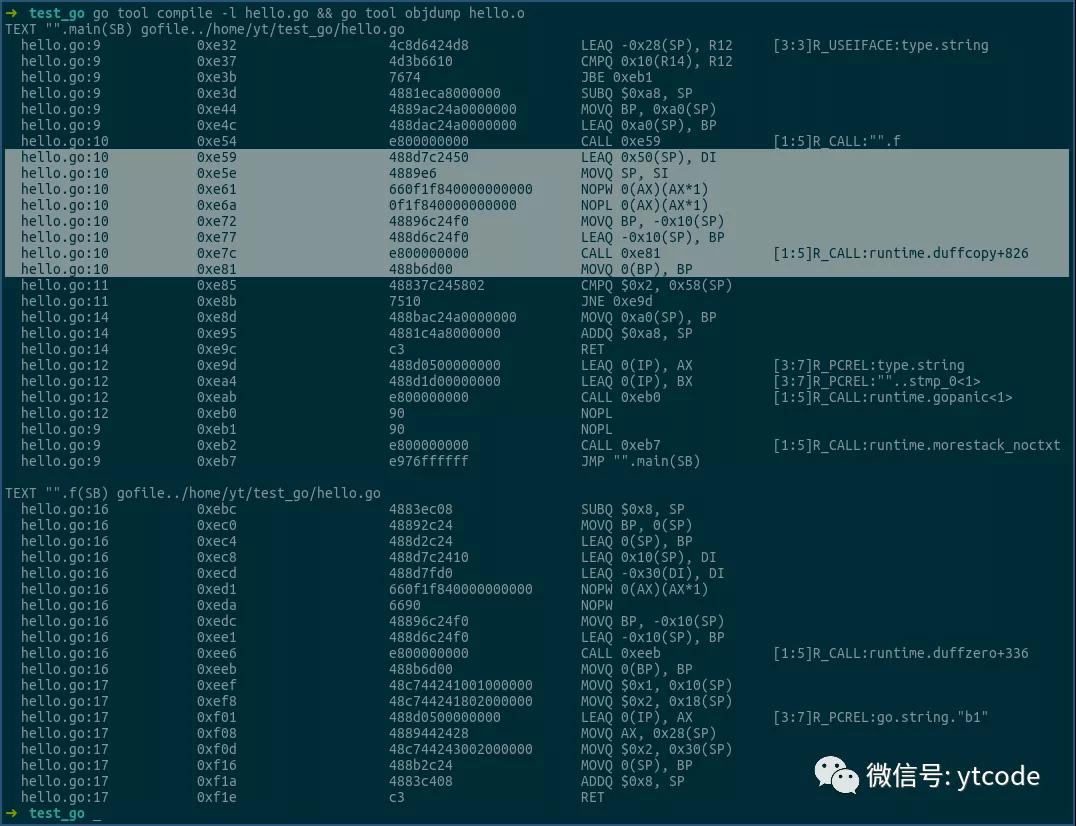
上图main函数的汇编中,通过调用函数f,初始化了main函数栈中,0x0(sp)到0x50(sp)的内存段,该内存段共有80个字节,正好对应于结构体S的大小。
在函数f返回后,sp寄存器存放的,正是函数f初始化的结构体S的地址。
接着,我们看上图中的选中行,该段逻辑通过runtime.duffcopy函数,将栈中内存段0x0(sp)到0x50(sp)的值,拷贝到了内存段0x50(sp)到0xa0(sp)的部分,即将函数f初始化的结构体S,从内存地址0x0(sp),拷贝到了0x50(sp)。
然后,通过0x58(sp),即sp中的地址加上0x58的形式,获得拷贝后的结构体S中,a2字段的值,最后将其和0x2比较,以进行后续逻辑。
由上可见,当函数返回结构体时,确实存在着一次结构体的拷贝操作。
对比以上两个示例我们看到,返回指针的确会更好些,因为这样节省了一次结构体的拷贝操作。
但这样性能就真的更好吗?
写个benchmark测试下:
执行看下结果:

这两个benchmark的时间几乎是相等的,其结果并不像我们预料的那样,返回指针的形式会更快些。
为什么呢?
看下这两个benchmark对应的汇编:

它们居然都被优化成了空跑for循环了,难怪这两个测试耗时是一样的。
加上编译器指令//go:noinline,防止f1/f2函数被内联,进而被过度优化:

如上图的第9行和第14行。
再来看下测试程序的汇编,确保以上操作是有效的。
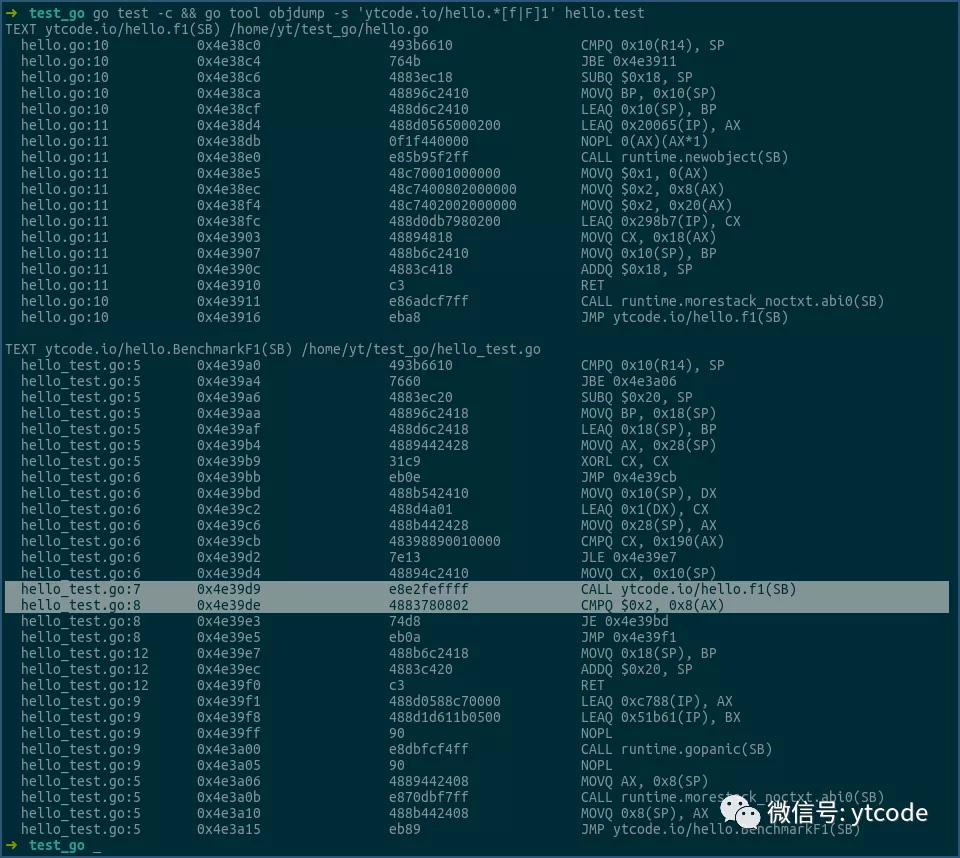
先看下函数f1及其对应的benchmark:
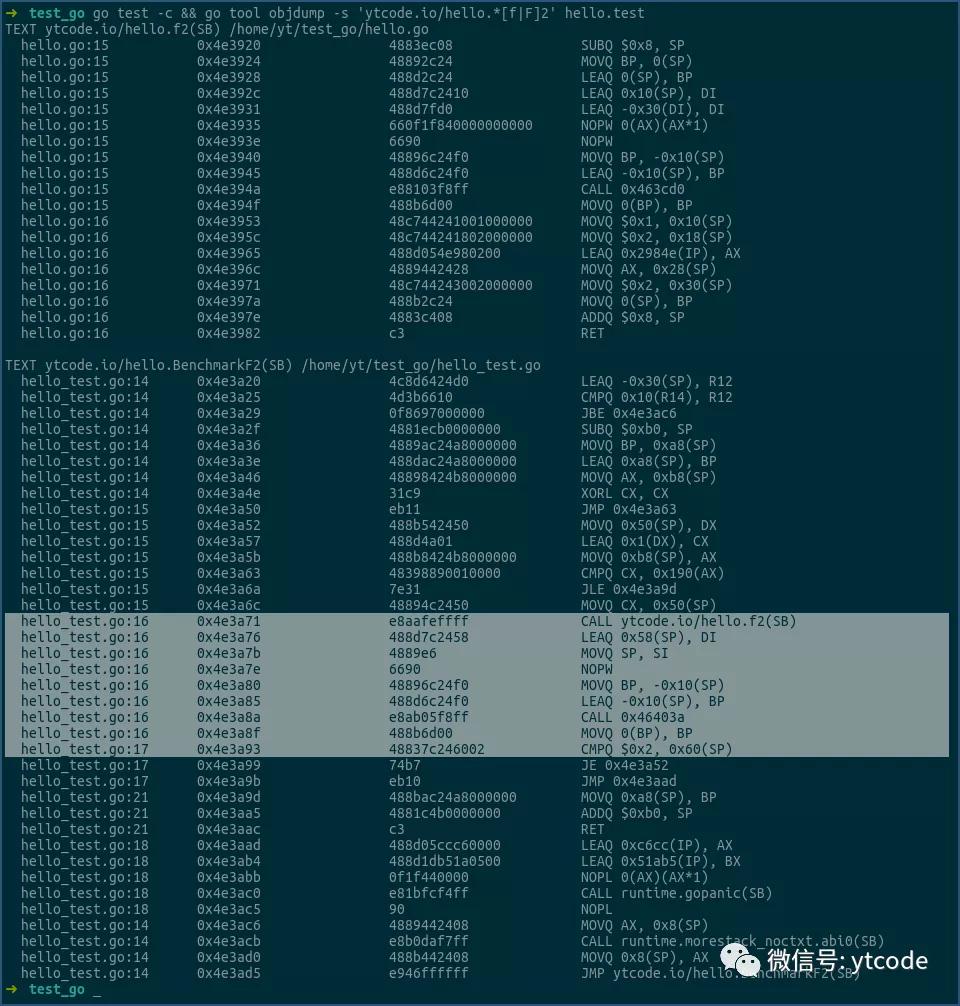
再看下函数f2及其对应的benchmark:
这次这两个都没有问题。
再来跑下benchmark:

这次结果显示,f2函数,即返回结构体形式,比f1函数,即返回指针的形式,居然快了将近5倍,意不意外?
这是为什么呢?
其实在上图中,就有一些线索。
看BenchmarkF1那行,其最后两列显示,每次调用f1函数,都会有一次堆内存分配操作,其分配内存的大小为80字节,正好对应于结构体S的大小,也就是说,f1函数中结构体S的内存,都是在堆上分配的。
而在BenchmarkF2中,就没有发生堆内存的分配操作,f2函数中的结构体S,都是在栈上分配的。
这个也可以通过上面展示的,f1/f2函数的汇编代码看到。
f1函数的汇编是通过runtime.newobject在堆上分配内存的,而f2函数则是直接就在栈上把内存分配好了,并没有调用runtime.newobject函数。
那为什么在堆上分配内存,会比在栈上分配内存慢这么多呢?
有两点原因,一是在堆上分配内存的函数runtime.newobject,其本身逻辑就比较复杂,二是堆上分配的内存,后期还要通过gc来对其进行内存回收,这些逻辑加起来,远比在栈上分配内存,外加一次拷贝操作要耗时的多。
有关go内存是在堆上分配的,还是在栈上分配的,这个是在编译过程中,通过逃逸分析来确定的,其主体思想是:
假设有变量v,及指向v的指针p,如果p的生命周期大于v的生命周期,则v的内存要在堆上分配。
其实逃逸分析的具体逻辑,远比上面说的复杂,如果有兴趣研究代码,可以从下面开始入手:
当然,我们也可以在编译时,通过加上-m参数,来让编译器告诉我们,一个变量到底是分配在堆上,还是在栈上:
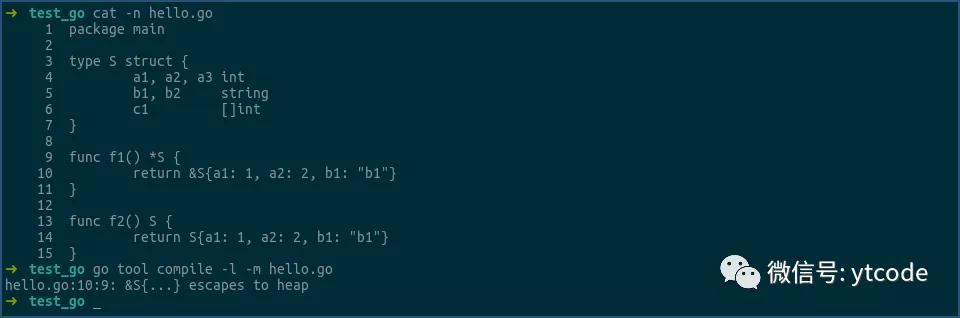
看上图,f1函数中的&S{...}逃逸到了堆上,即是在堆上分配的。
以上是对80字节大小的结构体,返回指针和返回值情况的比较,那如果结构体字节数更小或更大会怎么样呢?
经过测试,1MiB字节以下,返回结构体都更有优势。
那返回指针的方式是不是没用了呢?也不是,如果你最终的结构体,就是要存放到堆里,比如要存放到全局的map里,那返回指针优势就更大些,因为其省去了返回结构体时的拷贝操作。
就这些,希望对你有所帮助。
本文转载自微信公众号「卯时卯刻」,可以通过以下二维码关注。转载本文请联系卯时卯刻公众号。























