












公司 Tony 老师这两天请假,找来了他的好朋友 Kevin 顶班,这两个人的风格真是相差十万八千里。
Tony 性格缓慢,手法轻柔。到底有多轻呢?洗头发的时候我都怀疑他是不是怕把我头发弄湿。
Kevin 则完全不同,嗓音洪亮,风风火火。说是洗头发,但我感觉他就是在扇我脑袋。眼前水花四溅,雾气缭绕,仿佛都能看见彩虹。
理发的小感受,夸张了点儿。
经过上一篇的学习,对 Go 应该已经越来越有感觉了,今天来点更高级的内容:复杂数据类型。
本篇主要介绍数组和切片 slice,开整~
数组
数组有两个特点:
- 固定长度
- 元素类型相同
正是因为其长度固定,所以相比于切片,在开发过程中用的是比较少的。但数组是切片的基础,理解了数组,再学习切片就容易多了。
声明和初始化
声明一个长度是 3,元素类型是 int 的数组。通过索引来访问数组元素,索引从 0 到数组长度减 1,内置函数 len 可以获取数组长度。
- var a [3]int
- // 输出数组第一个元素
- fmt.Println(a[0]) // 0
- // 输出数组长度
- fmt.Println(len(a)) // 3
数组初始值为元素类型零值,也可以用数组字面量初始化数组。
- // 数组字面量初始化
- var b [3]int = [3]int{1, 2, 3}
- var c [3]int = [3]int{1, 2}
- fmt.Println(b) // [1 2 3]
- fmt.Println(c[2]) // 0
如果没有显示指定数组长度,而是用 ...,那么数组长度由实际的元素数量决定。
- // 使用 ...
- d := [...]int{1, 2, 3, 4, 5}
- fmt.Printf("%T\n", d) // [5]int
还可以指定索引位置来初始化,如果没有指定数组长度,则长度由索引来决定。
- // 指定索引位置初始化
- e := [4]int{5, 2: 10}
- f := [...]int{2, 4: 6}
- fmt.Println(e) // [5 0 10 0]
- fmt.Println(f) // [2 0 0 0 6]
多维数组
多维数组的声明和初始化同理,这里以二维数组来举例说明,有一点需要注意,多维数组仅第一维允许使用 ...。
- // 二维数组
- var g [4][2]int
- h := [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
- // 声明并初始化外层数组中索引为 1 和 3 的元素
- i := [4][2]int{1: {20, 21}, 3: {40, 41}}
- // 声明并初始化外层数组和内层数组的单个元素
- j := [...][2]int{1: {0: 20}, 3: {1: 41}}
- fmt.Println(g, h, i, j)
使用数组
只要数组元素是可比较的,那么数组就是可比较的,而且数组长度也是数组类型的一部分。
所以 [3]int 和 [4]int 是两种不同的类型。
- // 数组比较
- a1 := [2]int{1, 2}
- a2 := [...]int{1, 2}
- a3 := [2]int{1, 3}
- // a4 := [3]int{1, 2}
- fmt.Println(a1 == a2, a1 == a3, a2 == a3) // true false false
- // fmt.Println(a1 == a4) // invalid operation: a1 == a4 (mismatched types [2]int and [3]int)
数组遍历:
- // 数组遍历
- for i, n := range e {
- fmt.Println(i, n)
- }
值类型
Go 数组是值类型,赋值和传参都会复制整个数组。
从输出结果可以看出来,内容都是相同的,但地址不同。
- package main
- import "fmt"
- func main() {
- // 数组复制
- x := [2]int{10, 20}
- y := x
- fmt.Printf("x: %p, %v\n", &x, x) // x: 0xc00012e020, [10 20]
- fmt.Printf("y: %p, %v\n", &y, y) // y: 0xc00012e030, [10 20]
- test(x)
- }
- func test(a [2]int) {
- fmt.Printf("a: %p, %v\n", &a, a) // a: 0xc00012e060, [10 20]
- }
再来看看函数传参的情况:
- package main
- import "fmt"
- func main() {
- x := [2]int{10, 20}
- // 传参
- modify(x)
- fmt.Println("main: ", x) // main: [10 20]
- }
- func modify(a [2]int) {
- a[0] = 30
- fmt.Println("modify: ", a) // modify: [30 20]
- }
同样从结果可以看到,modify 中数组内容修改后,main 中数组内容并没有变化。
那么,有没有可能在函数内修改,而影响到函数外呢?答案是可以的,接下来要说的切片就可以做到。
切片 slice
切片是一种引用类型,它有三个属性:指针,长度和容量。
- 指针:指向 slice 可以访问到的第一个元素。
- 长度:slice 中元素个数。
- 容量:slice 起始元素到底层数组最后一个元素间的元素个数。
看到这样的解释是不是一脸懵呢?别慌,咱们来详细解释一下。
它的底层结构是这样的:
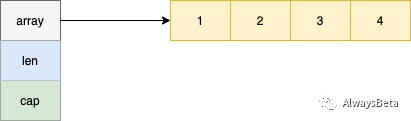
再来看一个例子,看看到底各部分都是什么意思。
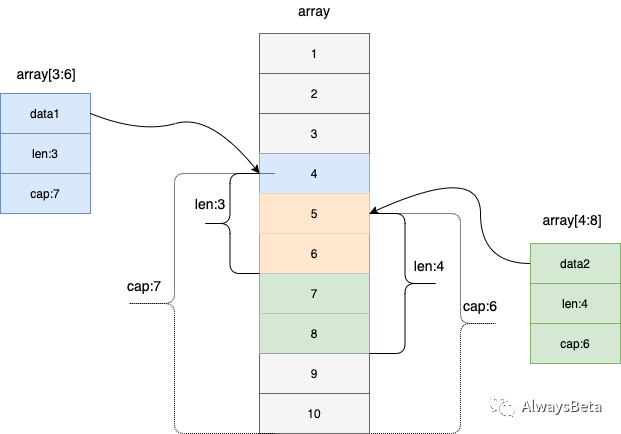
底层是一个包含 10 个整型元素的数组,data1 指向数组第 4 个元素,长度是 3,容量取到数组最后一个元素,是 7。data2 指向数组第 5 个元素,长度是 4,容量是 6。
创建切片
创建切片有两种方式:
第一种方式是基于数组创建:
- // 基于数组创建切片
- var array = [...]int{1, 2, 3, 4, 5, 6, 7, 8}
- s1 := array[3:6]
- s2 := array[:5]
- s3 := array[4:]
- s4 := array[:]
- fmt.Printf("s1: %v\n", s1) // s1: [4 5 6]
- fmt.Printf("s2: %v\n", s2) // s2: [1 2 3 4 5]
- fmt.Printf("s3: %v\n", s3) // s3: [5 6 7 8]
- fmt.Printf("s4: %v\n", s4) // s4: [1 2 3 4 5 6 7 8]
第二种方式是使用内置函数 make 来创建:
- // 使用 make 创建切片
- // len: 10, cap: 10
- a := make([]int, 10)
- // len: 10, cap: 15
- b := make([]int, 10, 15)
- fmt.Printf("a: %v, len: %d, cap: %d\n", a, len(a), cap(a))
- fmt.Printf("b: %v, len: %d, cap: %d\n", b, len(b), cap(b))
使用切片
遍历
和遍历数组方法相同。
- // 切片遍历
- for i, n := range s1 {
- fmt.Println(i, n)
- }
比较
不能使用 == 来测试两个 slice 是否有相同元素,但 slice 可以和 nil 比。slice
类型的零值是 nil,表示没有对应的底层数组,而且长度和容量都是零。
但也要注意,长度和容量都是零的,其值也并不一定是 nil。
- // 比较
- var s []int
- fmt.Println(len(s) == 0, s == nil) // true true
- s = nil
- fmt.Println(len(s) == 0, s == nil) // true true
- s = []int(nil)
- fmt.Println(len(s) == 0, s == nil) // true true
- s = []int{}
- fmt.Println(len(s) == 0, s == nil) // true false
所以,判断 slice 是否为空,要用内置函数 len,而不是判断其是否为 nil。
追加元素
使用内置函数 append。
- // 追加
- s5 := append(s4, 9)
- fmt.Printf("s5: %v\n", s5) // s5: [1 2 3 4 5 6 7 8 9]
- s6 := append(s4, 10, 11)
- fmt.Printf("s6: %v\n", s6) // s5: [1 2 3 4 5 6 7 8 10 11]
追加另一个切片,需要在另一个切片后面跟三个点。
- // 追加另一个切片
- s7 := []int{12, 13}
- s7 = append(s7, s6...)
- fmt.Printf("s7: %v\n", s7) // s7: [12 13 1 2 3 4 5 6 7 8 10 11]
复制
- // 复制
- s8 := []int{1, 2, 3, 4, 5}
- s9 := []int{5, 4, 3}
- s10 := []int{6}
- copy(s8, s9)
- fmt.Printf("s8: %v\n", s8) // s8: [5 4 3 4 5]
- copy(s10, s9)
- fmt.Printf("s10: %v\n", s10) // s10: [5]
引用类型
上文介绍数组时说过,数组属于值类型,所以在传参时会复制整个数组内容,如果数组很大的话,是很影响性能的。而传递切片只会复制切片本身,并不影响底层数组,是很高效的。
- package main
- import "fmt"
- func main() {
- s9 := []int{5, 4, 3}
- // 传参
- modify(s9)
- fmt.Println("main: ", s9) // main: [30 4 3]
- }
- func modify(a []int) {
- a[0] = 30
- fmt.Println("modify: ", a) // modify: [30 4 3]
- }
在 modify 中修改的值会影响到 main 中。
总结
本文学习了复合数据类型的前两种:数组和切片。分别介绍了它们的创建,常用操作,以及函数间的传递。
数组长度固定,是切片的基础;切片长度可变,多一个容量属性,其指针指向的底层结构就是数组。
在函数传参过程中,数组如果很大的话,很影响效率,而切片则解决了这个问题,效率更高。
在日常开发中,使用切片的频率会更高一些。
本文转载自微信公众号「AlwaysBeta」,可以通过以下二维码关注。转载本文请联系AlwaysBeta公众号。






















