网络攻击是指通过网络或其他技术,利用系统存在的缺陷或采用暴力攻击手段,导致信息系统异常或危害其正常运行。随着网络技术和应用的发展,网络攻击的数量和严重程度都在不断增加。网络攻击识别在保障网络安全方面发挥着重要作用。通过训练深度学习模型,可以实现对攻击活动的检测,达到发现已知攻击类型的目的。基于深度学习模型的攻击识别研究目前已成为热点,有监督的深度学习模型通过海量的标注数据,可以对攻击行为更好的识别,但基于监督的学习模型需要有标签样本,尤其是深度学习模型,建立标注数据集也需要大量安全专家辅助,费时费力。虽有公开的安全数据集,但攻击的演变性很容易过时,此外,若将所有采集到的数据提交专家打标签,由于攻击数据占所有数据的比例很低,会浪费大量的资金和时间投入。
1、网络攻击分类
想对攻击进行准确识别,有必要了解网络攻击分类,中国国家标准化管理委员会发布的《GB/Z 20986——2007信息安全技术信息安全事件分类分级指南》是为信息安全事件分类提供指导的技术文件。根据其对网络攻击事件的分类,本文将网络攻击种类总结为拒绝服务攻击、后门攻击、漏洞利用、扫描窃听、网络钓鱼、干扰攻击和其它网络攻击等。以下将对这些攻击方式进行详细介绍。
1.1. 拒绝服务攻击
拒绝服务(Denial of Service,DoS)攻击是一种通过发送恶意数据包降低服务器和网络性能,阻止合法用户正常使用网络资源的攻击手段。其一种常见的变体为分布式拒绝服务(Distributed Denial of Service,DDoS)攻击,该攻击利用分布在不同位置的海量计算机同时向目标发送攻击,以期耗尽目标资源。相对于DoS攻击,由于其攻击者分布不同且规模巨大,网络管理者很难及时区分哪些是恶意攻击者以采取防护手段,因此具有更高的成功概率。随着计算资源的日益廉价,DDoS攻击规模也在持续增大。据Google公司报道,其在2017年9月受到2.5Tbps的超大规模DDoS攻击,是2016年破纪录的Mirai僵尸网络623Gbps规模的四倍。根据攻击路径不同,常见DDoS攻击可分为直接型攻击、反射型攻击。
1.2. 后门攻击
后门(程序)令身份验证系统失效,授予特定用户远程访问权限。后门攻击是利用系统中存有的后门对信息系统发送远程命令,进而控制系统。被利用的后门可以是软件系统或硬件系统设计过程中留有的,也可以是攻击者先前攻击成功后留下的。
1.3. 漏洞利用
信息安全漏洞是硬件或软件在配置以及实现等过程中存在的安全弱点。漏洞利用是利用在本地或远程计算机上硬件或软件内的一个或多个漏洞,进行非法活动如安装恶意软件、运行恶意代码、获取隐私数据、控制系统。
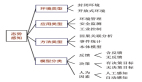
国家信息安全漏洞库使用的漏洞分类指南将信息安全漏洞划分为26种类型,图1给出了它们间的层次关系。
图1 CNNDV漏洞分类层次树
1.4. 扫描窃听
扫描窃听是借助网络安全扫描技术通过网络获取目标网络或主机信息的行为。网络安全扫描一直是安全专业人员在网络中进行服务发现的关键技术,但同时也被攻击者用于发现被攻击系统开放的端口、脆弱性等构建攻击工具需要的信息。现已有很多成熟的扫描工具如Nmap、Nessus、Acunetix等可以使用。常见的扫描窃听攻击分为端口扫描攻击、漏洞扫描攻击。
端口扫描攻击通过发送探测数据包,获取端口响应,进而推测开放的服务与端口信息。端口扫描会反馈目标端口是以下三种中的一种状态:(1)开放:目标主机正在监听端口,并正在使用扫描中使用的服务;(2)关闭:已收到数据包请求,但服务未监听端口;(3)过滤:已发送数据包请求,但没有答复,表明防火墙过滤了请求数据包。每个开放的端口都为攻击者提供了访问点,提供了破坏机会。
1.5. 网络钓鱼
网络钓鱼攻击通过假装为可信任的实体(通常是真实的机构或人),欺骗用户信任,并常常营造一种紧迫感促使用户采取行动,进而实现攻击目标。根据攻击形式的不同,网络钓鱼攻击包括钓鱼邮件、域名欺骗、水坑钓鱼等。
- 钓鱼邮件:钓鱼邮件是最常见的网络钓鱼攻击。攻击者为了令邮件可信,会在钓鱼邮件中使用与伪装的机构或人员类似的邮件地址,使用相同的措辞、字体、标识和签名。通过吸引用户跳转到设计好的恶意网站中或下载恶意附件等方式获得如用户名、密码、联系方式等重要敏感信息。
- 域名欺骗:域名欺骗是指通过采用被伪装的真实网站设计,使用类似的网络域名和字符,创建一个欺诈性的网站,并使其看起来真实可信。如使用域名apple.co伪装苹果公司域名apple.com。
- 水坑钓鱼:水坑攻击不直接对攻击目标实施攻击,而是通过感染攻击目标常用的网站等达到攻击目的。水坑攻击首先确定目标公司员工最常访问的几种特定网站(如公司服务供应商网站),然后感染这类中的一个或多个。当有员工访问被感染的网站,会引发其主机加载恶意软件,为攻击者访问公司内网、获取敏感信息提供机会。
当这些类型的攻击仅针对一个人时,可归类为鱼叉式网络钓鱼攻击。如在鱼叉式钓鱼邮件攻击中,攻击者向在目标组织中扮演特定角色的某人发送量身定制的电子邮件。此邮件旨在从特定人员获取登录信息或感染特定人员的计算机。
1.6. 干扰攻击
干扰攻击指通过某种技术手段,对网络进行干扰影响通信质量或通信中断的行为。
1.7. 其他网络攻击
其他网络攻击指上述六个子类中未包括的网络攻击。
2、基于主动学习模型的网络攻击识别
主动学习(Active Learning)方法可以通过要求专家仅注释信息量最大的样本来降低标注成本的同时保证准确。主动学习框架主要分为两个部分:采样策略和学习器,其先通过某种采样策略从大量无标注样本中选择目标样本提交专家标注,再用标注好的样本去训练学习器。此过程可结合学习器的性能表现作为反馈结合采样策略主动选择样本,避免标注无效样本,减少训练样本的资金和时间投入。由于训练深度学习模型时间较长,因此只考虑基于批处理的主动学习模型,即每轮选取b个样本去交给专家标注。
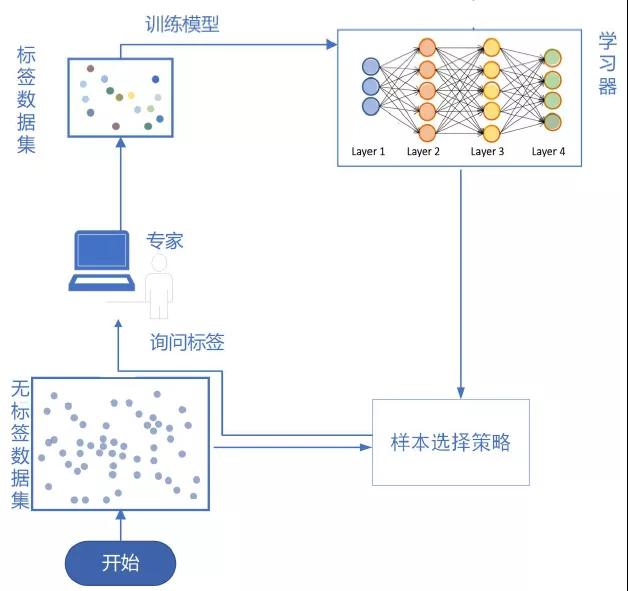
图2 基于主动学习框架的攻击识别模型训练图
由于主动学习中的关键问题是如何选择最有意义的样本来要求智慧体(通常是人类专家)进行标记,因此研究工作主要侧重在采样策略。不确定采样(Uncertainty sampling)是一种常用的采样策略,它选取当前分类器最不确定性的样本请求标注。不确定性度量方法包括最不信任,最小距离,熵,不同学习者的意见分歧等。
然而,这些经典的主动学习方法可能并不适用于批处理方式。由于深度模型的复杂性,待训练参数较多,训练时间往往相对普通机器学习模型更长。经典主动学习方法利用单个样本更新模型的做法不适于深度学习模型,因此需采用基于批处理的学习方式。即每次从大量的样本池中选择一个批次的样本,训练更新模型。但仅仅按不确定性排名选取的集合会存在样本冗余的风险,不适用于批量主动学习。为此,研究者们依据批量学习需求,对不确定性算法进行了改进。例如,通过引入多样性和密度改进了基于不确定性的标准,或者设计一种结合多样性度量的主动学习批处理模式方法。他们都对目标函数施加了多样性约束,以使选择用于标记的样本彼此之间应有足够的差异。为了避免不确定的样本是实际的噪声,利用高斯混合模型从密集区域中选择不确定的样本。
名为CEAL的伪标记方法,其不仅可以执行不确定性选择,还可以在增加的训练集中添加高度可信的样本以提高泛化精度。与上述主动学习方法不同,其可从训练模型预测结果中推断出所选样本的一些标签。它的主要缺点在于需要调整阈值以控制预测的置信度,以免破坏训练集。不可避免的,基于不确定性的算法高度依赖于训练充分的学习模型。但是,流程初期拥有的标签数据数量很少,可能会导致训练的模型最终效果较差。
为了提升模型的最终效果,还有一些其他采样方法。费希尔(Fisher)信息矩阵作为模型不确定性的度量,可以有效地减少分类模型的Fisher信息的未标记集。或者使所选样本尽可能地具有多样性和不确定性进行采样。但是,在深度学习模型中,不确定性采样方法通常利用输出层的前一层的输出即logits评估不确定性,这可能导致其性能表现比随机选择采样算法(Random sampling)表现更差,即使是最好的批量主动学习模型。另一种主流的批主动学习方法是贝叶斯主动学习方法,其原理是通过对每个查询样本或一组查询后的预期误差估计样本对模型的预期改进情况,但是由于算法复杂无法扩展到深度学习使用的大规模数据集。
卷积神经网络的主动学习的定义为核心集选择问题。其以任意点到其最近标注点的距离的最大值作为评估损失评估标准,并选择可以使该距离最小化的数据集作为采样集合。通过将主动学习视为二元分类任务来从新的角度分析主动学习,以使标记集与未标记池不可区分来选择样本进行标记。由于算法中每批都需要多个小批量,因此他们的方法需要比其他方法更多的训练时间。此外,当未标记的池比标记的池大得多时,它们用来训练分类器的样本是不足以覆盖整个数据集信息的。而不平衡数据训练的分类器,将进一步限制其总体有效性。
综上所述,基于批处理的主动学习方法虽然可以减少深度学习模型的训练时间,但基于某种信息量评估标准的样本排名结果采样容易选取冗余样本。这是因为相似样本的排名相近,虽然其单独来看带有很大信息量,但如果同时选择多个,便带来了冗余信息。因此,在网络攻击识别的主动学习应用中,如何进行数据样本筛选仍旧是未来需要关注的问题。
参考文献
[1] Decomain C , Wrobel S . Active Hidden Markov Models for Information Extraction[J]. International Symposium on Intelligent Data Analysis, 2001.
[2] Settles B . Active Learning Literature Survey[J]. University of Wisconsinmadison, 2010.
[3] Freund Y , Seung H S , Shamir E , et al. Selective Sampling Using the Query by Committee Algorithm[J]. Machine Learning, 1997, 28(2-3):133-168.
[4] Wang K , Zhang D , Li Y , et al. Cost-Effective Active Learning for Deep Image Classification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 27(12):1-1.