传统的 OLAP 系统在业务中往往扮演着比较静态的角色,以通过分析海量的数据得到业务的洞察(比如说预计算好的视图、模型等),从这些海量数据分析到的结果再通过另外一个系统提供在线数据服务(比如HBase、Redis、MySQL等)。这里的服务(Serving)和分析(Analytical)是个割裂的过程。与此不同的是,实际的业务决策过程往往是一个持续优化的在线过程。服务的过程会产生大量的新数据,我们需要对这些新数据进行复杂的分析。分析产生的洞察实时反馈到服务,让业务的决策更实时,从而创造更大的商业价值。
Hologres定位是一站式实时数仓,融合分析能力(Analytical)与在线服务(Serving)为一体,减少数据的割裂和移动。本文的内容将会针对Hologres的服务能力(核心为点查能力),介绍Hologres到底具备哪些服务能力,以及背后的实现原理。
通常我们所说的点查场景是指Key/Value查询的场景,广泛用于在线服务。由于点查场景的广泛需求,市场上存在多种KV数据库定位于支持高吞吐、低延时的点查场景,例如被大家广而熟知的HBase,它通过自定义的一套API来提供点查的能力,在许多业务场景都能够获得较好的效果。但是HBase在实际使用中也会存在一定的缺点,这也使得很多业务从HBase迁移至Hologres,主要有以下几点:
当数据规模大到一定程度的时候,HBase在性能方面将会有所下降,无法满足大规模的点查计算,同时在稳定性上也变得不如人意,需要有经验的运维支持
HBase提供的是自定义API,上手有一定的成本。Hologres直接通过SQL提供高吞吐、低延时的点查服务。相比于其它KV系统提供自定义API,SQL接口无疑更加的简单易用。
HBase采用Schema Free设计,没有数据类型,对于检查数据质量,修正数据质量也带来了复杂度,查错难,修正难。Hologres具备与Postgres兼容的几乎所有主流数据类型,可以通过Insert/Select/Update/Delete标准SQL语句对数据进行查看、更新。
在Hologres中的点查场景是指行存表基于主键(PK)的查询。
- --建行存表BEGIN;CREATE TABLE public.holotest ( "a" text NOT NULL, "b" text NOT NULL, "c" text NOT NULL, "d" text NOT NULL, "e" text NOT NULL,PRIMARY KEY (a,b));CALL SET_TABLE_PROPERTY('public.holotest', 'orientation', 'row');CALL SET_TABLE_PROPERTY('public.holotest', 'time_to_live_in_seconds', '3153600000');COMMIT;-- Hologres通过SQL进行点查select * from table where pk = ?; -- 一次查询单个点select * from table where pk in (?, ?, ?, ?, ?); -- 一次查询多个点
点查场景技术实现难点
正常情况下,一条SQL语句的执行,需要经过SQL Parser进行解析成AST(抽象语法树),再由Query Optimizer处理生成Plan(可执行计划),最终通过执行Plan拿到计算结果。而要想通过SQL做到高吞吐、低延时、稳定的点查服务,则必须要克服如下困难:
在不破坏PostgreSQL生态的情况下,SQL接口如何做到高QPS?
如何做低甚至避免SQL解析与优化器的开销
一套高效的Client SDK如何与后端存储进行交互?
如何在低消耗的情况下,做到高并发的交互
如何减少消息传递过程中的开销
如何感知后端的压力、配合做到最好的吞吐与延迟
后端存储如何在高性能的情况下更加稳定?
如何最大化利用cpu资源
如何减少各种内存的分配与拷贝、避免热点key等问题对系统带来的不稳定性
如何减少冷数据IO的影响
在克服上述3大类困难后,整体的工作方式就可以非常的简洁:在接入层(FrontEnd)上直接通过Client SDK与后端存储通信。
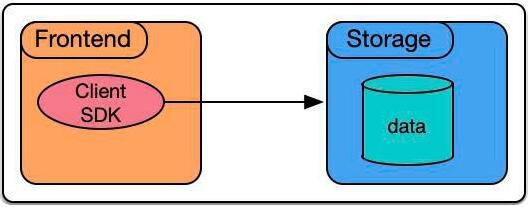
下面将会介绍Hologres是如何克服以上3大困难,从而实现高吞吐低延时的点查。
降低、避免SQL解析与优化器的开销
Query Optimizer进行Short Cut
由于点查的Query足够简单,Hologres的Query Optimizer进行了相应的short cut,点查Query并不会进入Opimizer的完整流程。Query进入FrontEnd后它会交由Fixed Planner进行处理,并由其生成对于的Fixed Plan(点查的物理Plan),Fixed Planner非常轻,无需经过任何的等价变换、逻辑优化、物理优化等步骤,仅仅是基于AST树进行了一些简单的分析并构建出对应的Fixed Plan,从而尽量规避掉优化器的开销。
Prepared Statement
尽管Query Optimizer对点查Query进行了short cut,但是Query进入到FrontEnd后的解析开销依然存在、Query Optimizer的开销也没有完全避免。
Hologres兼容Postgres,Postgres的前、后端通信协议有extended协议与simple协议两种:
simple协议:是一次性交互的协议,Client每次会直接发送待执行的SQL给Server,Server收到SQL后直接进行解析、执行,并将结果返回给Client。simple协议里Server无可避免的至少需要对收到的SQL进行解析才能理解其语义。
extended协议:Client与Server的交互分多阶段完成,整体大致可以分成两大阶段。
第一阶段:Client在Server端定义了一个带名字的Statement,并且生成了该Statement所对应的generic plan(不与特定的参数绑定的通用plan)。
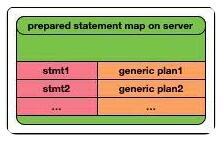
第二阶段:用户通过发送具体的参数来执行第一阶段中定义的Statement。第二阶段可以重复执行多次,每次通过带上第一阶段中所定义的Statement名字,以及执行所需要的参数,使用第一阶段生成的generic plan进行执行。由于第二阶段可以通过Statement名字和附带的参数来反复执行第一个阶段所准备好的generic plan,因此第二个段在Frontend的开销几乎等同于0。
为此Hologres基于Postgres的extended协议,支持了Prepared Statement,做到了点查Query在Frontend上的开销接近于0。
高性能的内部通信
BHClient是Hologres实现的一套用于与后端存储直接通信的高效Private Client SDK,主要有以下几个优势:
1)Reactor模型、全程无锁的异步操作
BHClient工作方式类似reactor模型,每个目标shard对应一个eventloop,以“死循环”的方式处理该shard上的请求。由于HOS对调度执行单元的抽象,即使是shard很多的情况下,这种工作方式的基础消耗也足够低。
2)高效的数据交换协议binary row
通过自定义一套内部的数据通信协议binary row来减少整个交互链路上的内存的分配与拷贝。
3)反压与凑批
BHClient可以感知后端的压力,进行自适应的反压与凑批,在不影响原有Latency的情况下提升系统吞吐。
稳定可靠的后端存储
1)LSM(Log Structured Merge Tree)
Hologres的行存表采取LSM进行存储,相比于传统的B+树,LSM能够提供更高的写吞吐,因为它不会出现任何的随机写,Append Only的操作保证了其只会顺序的写盘。
一个行存tablet上会存在一个memtable,和多个immutable memtable。
数据更新都会写入到memtable中,当memtable写满后会转变为immtable memtable,immutable memtable会Flush成Key有序的SST(Sorted String Table)文件,SST文件一旦生成则不能修改,因此不会发生随机写的操作。
SST文件在文件系统里面按层组织,除了level 0上的SST文件间无序,且存在overlap外,其它level上的SST文件间有序,且无overlap。因此查询的时候,对于level 0上的文件需要逐个遍历,而其它level的文件可以二分查找。底层的SST文件通过Compaction成新的SST文件去到更高层,因此低层的数据要比高层的新,所以一旦在某层上找到了满足条件的key则无需往更高层去查询。
2)基于C++纯异步的开发
采用LSM对数据进行组织存储的系统并不仅仅只有Hologres,LSM在谷歌的"BigTable"论文中被提出后,很多的系统都对其进行了借鉴采用,例如HBase。Hologres采用C++进行开发,相较于Java,native语言使得我们能够追求到更极致的性能。同时基于HOS(Hologres Operation System)提供的异步接口进行纯异步开发,HOS通过抽象ExecutionContext来自我管理CPU的调度执行,能够最大化的利用硬件资源、达到吞吐最大化。
3)IO优化与丰富的Cache机制
Hologres实现了非常丰富的Cache机制row cache、block cache、iterator cache、meta cache等,来加速热数据的查找、减少IO访问、避免新内存分配。当无可避免的需要发生IO时,Hologres会对并发IO进行合并、通过wait/notice机制确保只访问一次IO,减少IO处理量。通过生成文件级别的词典及压缩,减少文件物理存储成本及IO访问。
总结
Hologres致力于一站式实时数仓,除了具备处理复杂OLAP分析场景的能力之外,还支持超高QPS在线点查服务,通过使用标准的Postgres SDK接口,就能通过SQL获得低延时、高吞吐的在线服务能力,简化学习成本,提升开发效率。