本文转自雷锋网,如需转载请至雷锋网官网申请授权。
DeepMind又冷不丁给了我们一个小惊喜。
我们都知道,强化学习苦于泛化能力差,经常只能针对单个任务来从头开始学习。
像DeepMind之前开发的AlphaZero,尽管可以玩转围棋、国际象棋和日本将棋,但对每种棋牌游戏都只能从头开始训练。
泛化能力差也是AI一直被诟病为人工智障的一大原因。人类智能厉害的一点就是,可以借鉴之前的经验,迅速适应新环境,比如你不会因为是第一次吃川菜,就看着一口鸳鸯锅不知所措,你吃过潮汕火锅嘛,不都是涮一下的事情嘛。
但是,泛化能力也不是一蹴而就的,就像我们玩游戏的时候,也是先做简单任务,然后逐步升级到复杂任务。在游戏《空洞骑士》中,一开始你只需要随意走动挥刀砍怪就行,但在噩梦级难度的“苦痛之路”关卡中,没有前面一点点积累的烂熟于心的技巧,只能玩个寂寞。
1、多任务元宇宙
DeepMind此次就采用了这种“课程学习”思路,让智能体在不断扩展、升级的开放世界中学习。也就是说,AI的新任务(训练数据)是基于旧任务不断生成的。
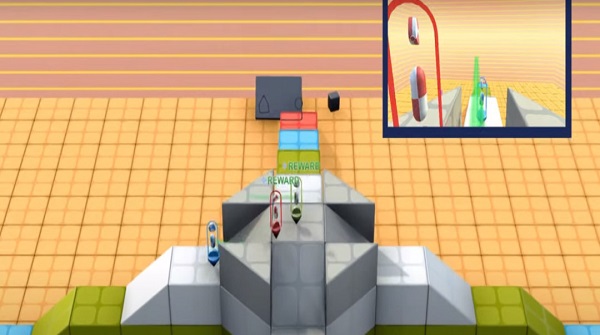
在这个世界中,智能体可以尽情锻炼自己,简单的比如“靠近紫色立方体”,复杂一点的比如“靠近紫色立方体或将黄色球体放在红色地板上”,甚至还可以和其他智能体玩耍,比如捉迷藏——“找到对方,并且不要被对方找到”。
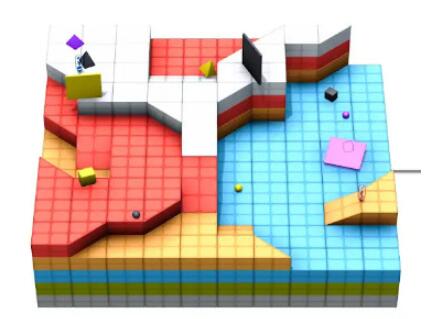
每个小游戏存在于世界的一个小角落,千千万万个小角落拼接成了一个庞大的物理模拟世界,比如下图中的几何“地球”。
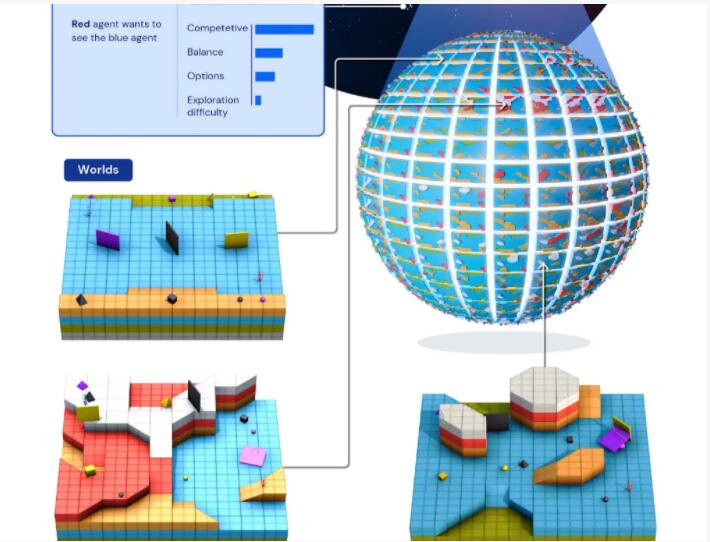
总体来说这个世界的任务由三个要素构成,即任务=游戏+世界+玩家,并根据三个要素的不同关系,决定任务的复杂度。
复杂度的判断有四个维度:竞争性,平衡性,可选项,探索难度。
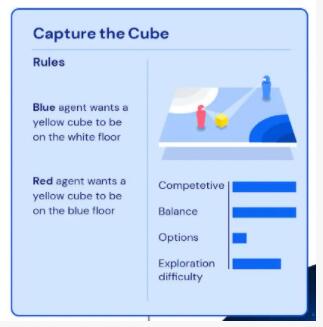
比如在“抢方块”游戏中,蓝色智能体需要把黄色方块放到白色区域,红色智能体需要把黄色方块放到蓝色区域。这两个目标是矛盾的,因此竞争性比较强;同时双方条件对等,平衡性比较高;因为目标简单,所以可选项少;这里DeepMind把探索难度评为中上,可能是因为定位区域算是比较复杂的场景。
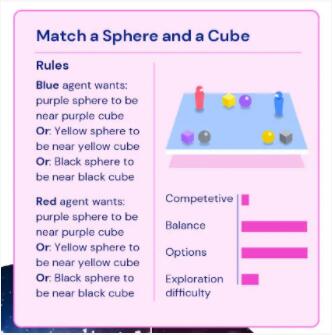
再例如,在“球球喜欢和方块一起玩”游戏中,蓝色和红色智能体都有一个共同的目标,让相同颜色的球体和方块放在相近的位置。
这时候,竞争性自然很低;平衡性毋庸置疑是很高的;可选项相比上面的游戏会高很多;至于探索难度,这里没有定位区域,智能体随便把球体和方块放哪里都行,难度就变小了。
基于这四个维度,DeepMind打造了一个任务空间的、超大规模的“元宇宙”,几何“地球”也只是这个元宇宙的一个小角落,限定于这个四维任务空间的一个点。DeepMind将这个“元宇宙”命名为Xland,它包含了数十亿个任务。
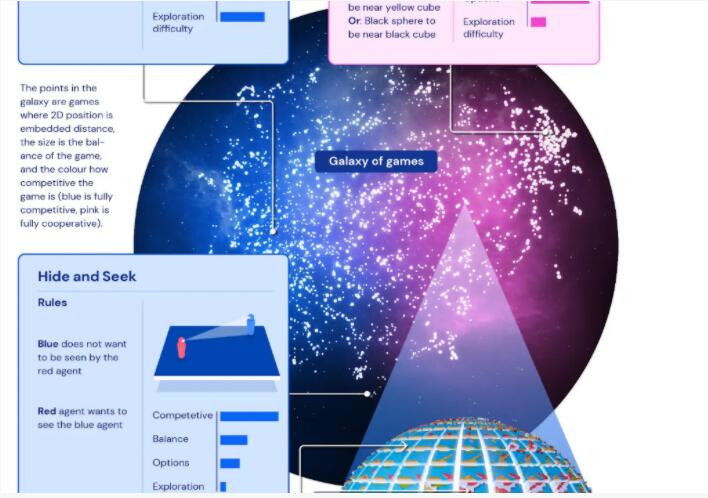
来看看XLand的全貌,它由一系列游戏组成,每个游戏都可以在许多不同的模拟世界中进行,这些世界的拓扑和特征平滑地变化。

2、终生学习
数据有了,那么接下来就得找到合适的算法。DeepMind发现,目标注意网络 (GOAT) 可以学习更通用的策略。
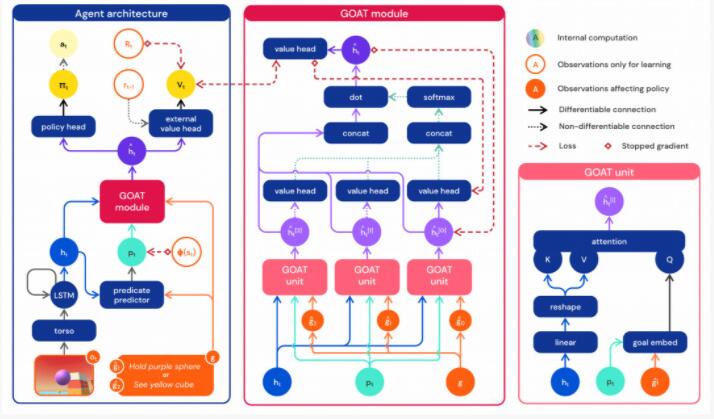
具体来说,智能体的输入包括第一视角的RGB图像、本体感觉以及目标。经过初步处理后,生成中间输出,传递给GOAT模块,该模块会根据智能体的当前目标处理中间输出的特定部分,并对目标进行逻辑分析。
所谓逻辑分析是指,对每个游戏,可以通过一些方法,来构建另一个游戏,并限制策略的价值函数的最优值上限或者下限。
到这里,DeepMind向我们提出了一个问题:对于每个智能体,什么样的任务集合才是最好的呢?换句话说,在打怪升级中,什么样的关卡设置才会让玩家能顺利地升级为“真”高手,而不是一刀9999?
DeepMind给出的答案是,每个新任务都基于旧任务生成,“不会太难,也不会太容易”。其实,这恰好是让人类学习时感到“爽”的兴奋点。
在训练开始时,太难或太容易的任务可能会鼓励早期学习,但会导致训练后期的学习饱和或停滞。
实际上,我们不要求智能体在一个任务上非常优秀,而是鼓励其终身学习,即不断去适应新任务。
而所谓太难、太容易其实是比较模糊的描述。我们需要的是一个量化方法,在新任务和旧任务之间做弹性连接。
怎么不让智能体在新任务中因为不适应而“暴死”呢?进化学习就提供了很好的灵活性。总体来说,新任务和旧任务是同时进行的,并且每个任务有多个智能体参与“竞争”。在旧任务上适应得好的智能体,会被选拔到新任务上继续学习。
在新任务中,旧任务的优秀智能体的权重、瞬时任务分布、超参数都会被复制,参与新一轮“竞争”。
并且,除了旧任务中的优秀智能体,还有很多新人参与,这就引进了随机性、创新性、灵活性,不用担心“暴死”问题。
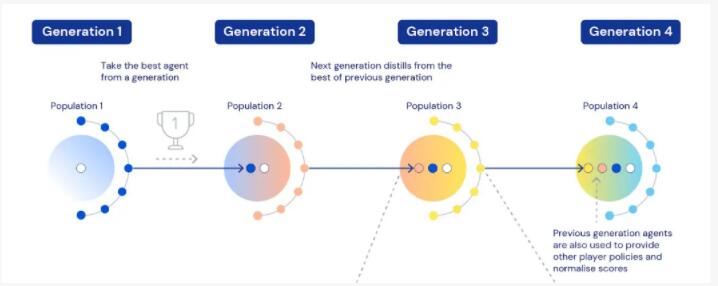
当然,在每个任务中不会只有一种优秀智能体。因为任务也是不断在生成的、动态变化的,一个任务可以训练出有不同长处的智能体,并往不同的方向演化(随着智能体的相对性能和鲁棒性进行)。
最终,每个智能体都会形成不同的擅长任务的集合,像极了春秋战国时期的“百家争鸣”。说打怪升级显得格局小了,这简直是在模拟地球嘛。
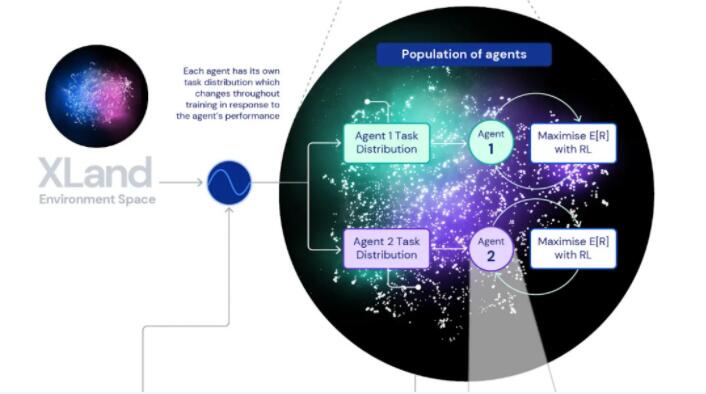
DeepMind表示,“这种组合学习系统的迭代特性是,不优化有界性能指标,而是优化迭代定义的通用能力范围,这使得智能体可以开放式地学习,仅受环境空间和智能体的神经网络表达能力的限制。”
3、智能初现
最终,在这个复杂“元宇宙”中升级、进化、分流的智能体形成了什么优秀物种呢?
DeepMind说道,智能体有很明显的零样本学习能力,比如使用工具、打围、数数、合作&竞争等等。

来看几个具体的例子。
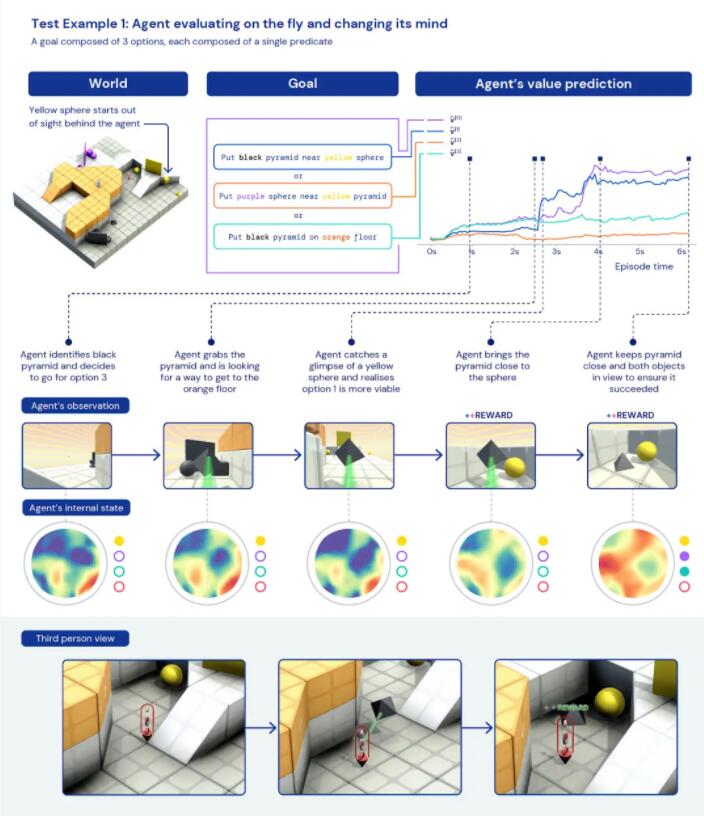
首先是,智能体学会了临场应变。它的目标有三个:
- 将黑色金字塔放到黄色球体旁边;
- 将紫色球体放到黄色金字塔旁边;
- 将黑色金字塔放到橙色地板上。
AI一开始找到了一个黑色金字塔,想着把它拿到橙色地板上(目标3),但在搬运过程中瞄见了一个黄色球体,瞬间改变主意,“我可以实现目标1啦”,将黑色金字塔放到了黄色球体旁边。
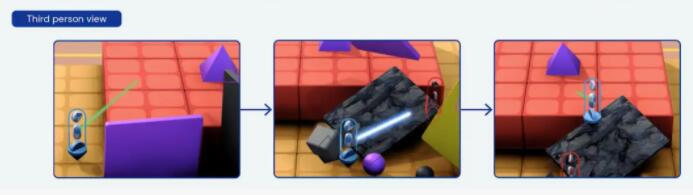
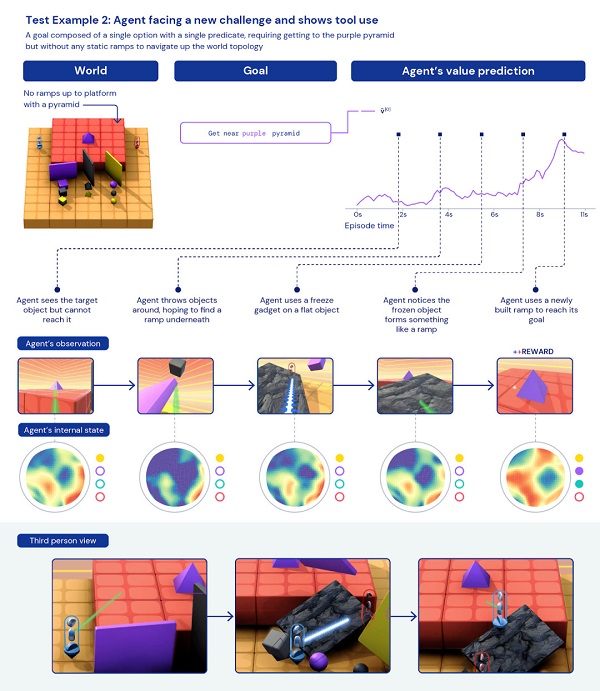
第二个例子是,不会跳高,怎么拿到高台上的紫色金字塔?
在这个任务中,智能体需要想办法突破障碍,取到高台上的紫色金字塔,高台周边并没有类似阶梯、斜坡一样的路径。
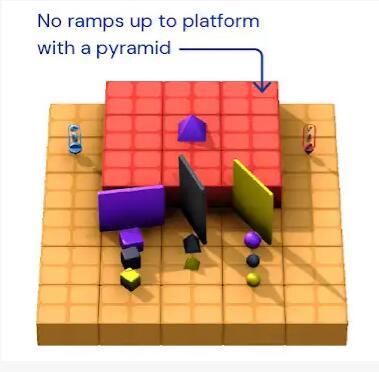
因为不会调高,所以智能体急的“掀桌子”,把周边的几块竖起来的板子都弄倒了。然后,巧的是,一块黑色石板倒在高台边上,“咦,等等,这不就是我要的阶梯吗?”
这个过程是否体现了智能体的智能,还无法肯定,可能只是一时的幸运罢了。关键还是,要看统计数据。
经过5代训练,智能体在 XLand 的 4,000 个独立世界中玩大约 700,000 个独立游戏,涉及340 万个独立任务的结果,最后一代的每个智能体都经历了 2000 亿次训练步骤。
目前,智能体已经能够顺利参与几乎每个评估任务,除了少数即使是人类也无法完成的任务。
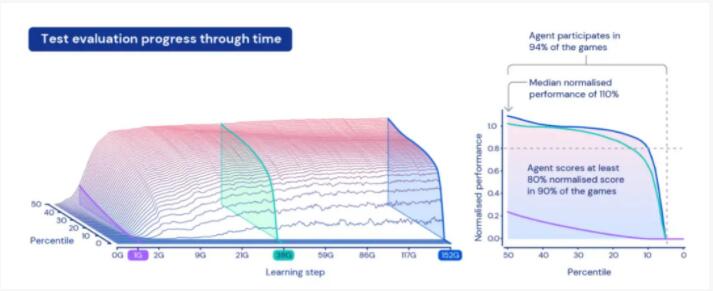
DeepMind的这项研究,或许一定程度上体现了“密集学习”的重要性。也就是说,不仅是数据量要大,任务量也要大。这也使得智能体在泛化能力上有很好的表现,比如数据显示,只需对一些新的复杂任务进行 30 分钟的集中训练,智能体就可以快速适应,而从头开始用强化学习训练的智能体根本无法学习这些任务。
在往后,我们也期待这个“元宇宙”变得更加复杂和生机勃勃,AI经过不断演化,不断给我们带来惊喜(细思极恐)的体验。