本文转载自微信公众号「一个程序员的修炼之路」,作者河边一枝柳。转载本文请联系一个程序员的修炼之路公众号。
如果在Windows中编程应该了解一些Windows的内存管理,而堆(Heap)也属于内存管理的一部分。这篇文章对你理解Windows内存分配的基本原理和调试堆内存问题或许会有所帮助。
Windows Heap概述
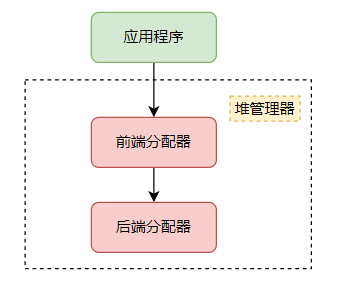
下图参考<<Windows高级调试>>所画,并做了一些小小的修改。可以看出来程序中对堆的直接操作主要有三种:
- 进程默认堆。每个进程启动的时候系统会创建一个默认堆。比如LocalAlloc或者GlobalAlloc也是从进程默认堆上分配内存。你也可以使用GetProcessHeap获取进程默认堆的句柄,然后根据用这个句柄去调用HeapAlloc达到在系统默认堆上分配内存的效果。
- C++编程中常用的是malloc和new去申请内存,这些由CRT库提供方法。而根据查看在VS2010之前(包含),CRT库会使用HeapCreate去创建一个堆,供CRT库自己使用。在VS2015以后CRT库的实现,并不会再去创建一个单独的堆,而使用进程默认堆。 (VS2013的CRT源码我并未查看,有兴趣的可以看看VS2013默认的CRT库采用的是进程默认堆还是新建的堆)。
- 自建堆。这个泛指程序通过HeapCreate去创建的堆,然后利用HeapAlloc等API去操作堆,比如申请空间。
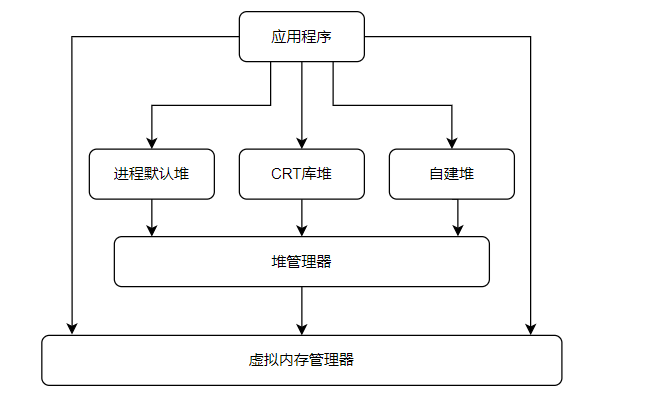
那么堆管理器是通过调用虚拟管理器的一些方法进行堆管理的实现,比如VirtualAlloc之类的函数。同样应用程序也可以直接使用VirtualAlloc之类的函数对内存进行使用。
说到这里不免有些生涩,我们就写一个示例代码来看看一个进程的堆情况。
- #include <windows.h>
- #include <iostream>
- #include <intsafe.h>
- using namespace std;
- const char* GetHeapTypeString(HANDLE pHandle)
- {
- ULONG ulHeapInfo;
- HeapQueryInformation(pHandle,
- HeapCompatibilityInformation,
- &ulHeapInfo,
- sizeof(ulHeapInfo),
- NULL);
- switch (ulHeapInfo)
- {
- case 0:
- return "Standard";
- case 1:
- return "Look Aside List";
- case 2:
- return "Low Fragmentation";
- }
- return "Unknow type";
- }
- void PrintAllHeaps()
- {
- DWORD dwNumHeap = GetProcessHeaps(0, NULL);
- if (dwNumHeap == 0)
- {
- cout << "No Heap!" << endl;
- return;
- }
- PHANDLE pHeaps;
- SIZE_T uBytes;
- HRESULT Result = SIZETMult(dwNumHeap, sizeof(*pHeaps), &uBytes);
- if (Result != S_OK) {
- return;
- }
- pHeaps = (PHANDLE)malloc(uBytes);
- dwNumHeap = GetProcessHeaps(dwNumHeap, pHeaps);
- cout << "Process has heaps: " << dwNumHeap << endl;
- for (int i = 0; i < dwNumHeap; ++i)
- {
- cout << "Heap Address: " << pHeaps[i]
- << ", Heap Type: " << GetHeapTypeString(pHeaps[i]) << endl;
- }
- return;
- }
- int main()
- {
- cout << "========================" << endl;
- PrintAllHeaps();
- cout << "========================" << endl;
- HANDLE hDefaultHeap = GetProcessHeap();
- cout << "Default Heap: " << hDefaultHeap
- << ", Heap Type: " << GetHeapTypeString(hDefaultHeap) << endl;
- return 0;
- }
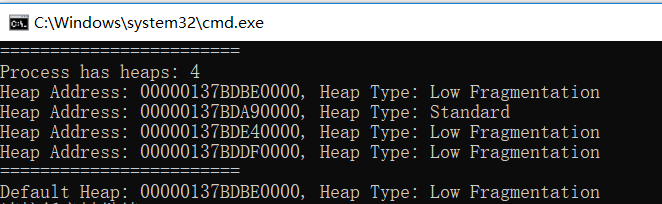
这是一个在Win10上运行的64位程序输出的结果: 这个进程我们并没有在main中显示的创建Heap,我们都知道进程在启动的时候初始化会创建相关的资源,其中也包含了堆。这个进程共创建了四个堆。可以看出来第一个堆就是进程的默认堆,并且是采用的 Low Fragmentation的分配策略的堆。
堆的内存分配策略
堆主要有前端分配器和后端分配器,我所理解的前端分配器就是类似于缓存一样,便于快速的查询所需要的内存块,当前端分配器搞不定的时候,就交给后端分配器。
前端分配器主要分为, 而Windows Vista之后进程默认堆均采用低碎片前端分配器。
- 旁视列表 (Look Aside List)
- 低碎片 (Low Fragmentation)
以下的场景均采用32位的程序进行的描述。
前端分配器之旁视列表
旁视列表 (Look Aside List, LAL)是一种老的前端分配器,在Windows XP中使用。
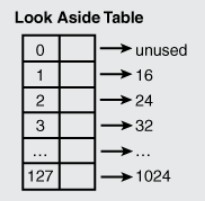
这是一个连续的数组大小为128,每个元素对应一个链表,因为其存储的是整个Heap块的大小,那就包含了用户申请的大小+堆块元数据,而这里元数据大小为8字节, 而最小分配粒度为8字节(32位程序),那么最小的堆块的大小则为16个字节。从数据1~127,每个链表锁存储的堆块大小按照8字节粒度增加。
那么当用户申请一个比如10字节大小的的内存,则在LAL中查找的堆块大小为18字节=10字节+元数据8字节,则在表中找到的刚好匹配的堆块大小为24字节的节点,并将其从链表中删除。
而当用户释放内存的时候,也会优先查看前端处理器是否处理,如果处理则将内存插入到相应的链表中。
前端分配器之低碎片
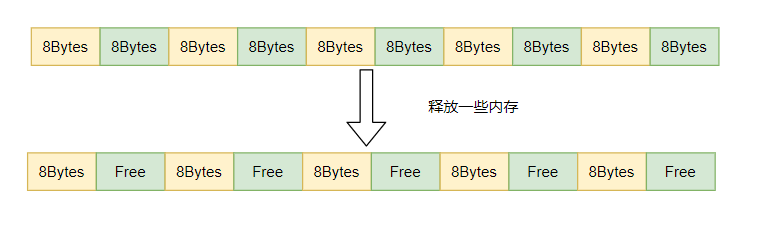
先说说内存碎片我这里简要概述下: 如下图所示假设一段大的连续的内存被分割为若干个8字节的内存块,然后这个时候释放了图中绿色部分的内存块,那么此时总共空出了40字节的内存,但想去申请一个16字节的内存块,却无法申请到一个连续的16字节内存块,从而分配内存失败,这就是内存碎片。
所谓的低碎片前端分配器,是将LAL类似的数组中的粒度重新进行了划分:
| 数据Index | 堆块递增粒度 | 堆块字节范围 |
|---|---|---|
| 0~31 | 8 | 8~256 |
| 32~47 | 16 | 272~512 |
| … | … | … |
| 112-127 | 512 | 8704~16384 |
可以看到同样的数组的大小,将其按照不同的粒度划分,相比较LAL分配的大小粒度逐步增大,到了最后的112-127区间粒度已经增大到了512字节,最大支持的16384。粒度更大的分配有利于缓解内存碎片,提高内存的使用效率。Windows Vista之后进程默认堆均采用低碎片前端分配器。
后端分配器
其实讲到前面这部分可能还有一些人云里雾里。那么我们的内存到底是怎么划分出来的呢?这就是后端分配器要做的事情了。看看后端分配器是如何管理这些内存的。
先说说堆在内存中的展现形式,一个堆主要由若干个Segment(段)组成,每个Segment都是一段连续的空间,然后用双向链表串起来。而一般情况下,一开始只有一个Segment,然后在这个Segment上申请空间,叫做Heap Entry(堆块)。但是这个Segment可能会被用完,那就新开辟一个Segment,而且一般新的Segement大小是原先的2倍,如果内存不足则不断的将申请空间减半。这里有个要注意的就是当划分了一个新的Segment后比如其空间为1GBytes,那么其真实的使用的物理内存肯定不会是1GBytes,因为此时内存还没有被应用程序申请,这个时候实际上这个Segment只是Reserve了这段虚拟地址空间,而当真正应用程序申请内存的时候,才会一小部分一小部分的Commit,这个时候才会用到真正的物理存储空间。
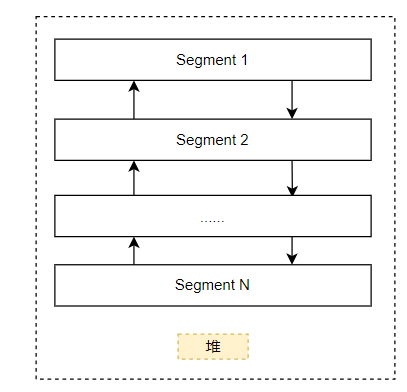
而应用程序申请的内存在Segment上叫做Entry(块),他们是连续的,可以看到一个块一般具有:
- 前置的元数据: 这里主要存储有当前块的大小,前一个块的大小,当前块的状态等。
- 用户数据区: 这段内存才是用户申请并且使用的内存。当然这块数据可能比你申请的内存要大一些,因为32位下面最小的分配粒度是8字节。这也是为什么有时候程序有时候溢出了几个字符,好像也没有导致程序异常或者崩溃的原因。
- 后置的元数据: 这个一般用于调试所用。一般发布的时候不会占用这块空间。
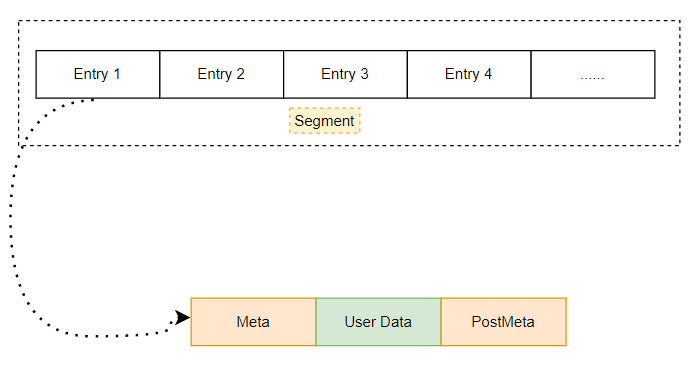
那么哪些块是可以直接使用的呢?这就涉及到这些块元数据中的状态,可以表明这个块是否被占用,如果是空闲状态则可以使用。
后端分配器,不会傻傻的去遍历所有的块的状态来决定是否可以分配吧?这个时候就用到了后端分配器的策略。
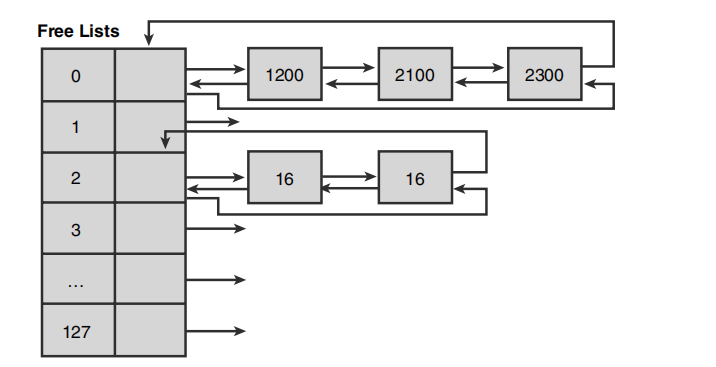
这个表有点类似于LAL, 只是注意看下这个index为0的多了一个list,从小到大排列,可变大小的从大于1016字节的小于524272字节的将在这个链表里面存储。超过524272字节将直接通过VirtualAlloc之类的API直接获取内存。
假设此时前端堆管理器需要寻找一个32字节的堆块, 后端管理器将如何操作?
这个时候请求到了后端分配器,后端分配器假设也没有在这个表中查找到32字节的空闲块,那么将先查找64字节的空闲块,如果找到,则将其从列表中移除,然后将其分割为两个16字节的块, 一个设置为占用状态返回给应用程序,一个设置为空闲状态插入响应的链表中。
那如果还没有找到呢?那么这个时候堆管理器会从Segment中提交(Commit)更多的内存去使用,创建新的块, 如果当前Segment空间也不够了,那就创建新的Segement
有细心的同学可能说,那前端分配器和后端分配器差不多吗,这里面有个很重要的就是,前端分配器链表中的块是属于占用状态的, 而后端分配器链表中的块是属于空闲状态的。
假设释放内存,该如何操作?
首先要看前端分配器是否处理这个释放的块,比如加入到相应的链表中去,如果不处理,那么后端分配器将会查看相邻的块是否也是空闲的,如果是空闲状态,将会采用块合并成一个大的块,并对相应的后端分配器链表进行操作。
当然了当你释放的内存足够多的时候,其实堆管理器也不会长期霸占着物理存储器的空间,也会在适当的情况下调用Decommit操作来减少物理存储器的使用。
Windbg查看进程中的堆
进程堆信息查看
进程堆的信息是放在PEB(进程环境块)中,可以通过查看PEB相关的信息, 可以看到当前进程包含有3个堆,并且堆的数组地址为0x77756660
- 0:000> dt _PEB @$peb
- ......
- +0x088 NumberOfHeaps : 3
- ......
- +0x090 ProcessHeaps : 0x77756660 -> 0x00fa0000 Void
- ......
然后我们查看对应的三个堆的地址,分别为0xfa0000, 0x14b0000和0x2e10000, 而第一个一般为进程的默认堆00fa0000。
- 0:006> dd 0x77756660
- 77756660 00fa0000 014b0000 02e10000 00000000
- 77756670 00000000 00000000 00000000 00000000
- 77756680 00000000 00000000 00000000 00000000
- 77756690 00000000 00000000 00000000 00000000
- 777566a0 00000000 00000000 00000000 00000000
- 777566b0 00000000 00000000 00000000 00000000
- 777566c0 ffffffff ffffffff 00000000 00000000
- 777566d0 00000000 020007d0 00000000 00000000
其实上述步骤Windbg提供了一个方法可以直接查看概要信息了, 可以看到系统默认堆00fa0000为LFH堆,并且已经Reserve了空间为1128K, Commit的内存为552K。
- 0:000> !heap -s
- ......
- LFH Key : 0x8302caa1
- Termination on corruption : ENABLED
- Heap Flags Reserv Commit Virt Free List UCR Virt Lock Fast
- (k) (k) (k) (k) length blocks cont. heap
- -----------------------------------------------------------------------------
- 00fa0000 00000002 1128 552 1020 178 21 1 1 0 LFH
- 014b0000 00001002 60 12 60 1 2 1 0 0
- 02e10000 00001002 1188 92 1080 4 4 2 0 0 LFH
- -----------------------------------------------------------------------------
可以通过dt _HEAP 00fa0000命令去查看进程默认堆的信息,也可以通过Windbg直接提供的命令去查看, 可以看到其分配空间的最小粒度(Granularity)为8字节。并且只有一个Segment.
- 0:006> !heap -a 00fa0000
- Index Address Name Debugging options enabled
- 1: 00fa0000
- Segment at 00fa0000 to 0109f000 (00089000 bytes committed)
- Flags: 00000002
- ForceFlags: 00000000
- Granularity: 8 bytes
- Segment Reserve: 00100000
- Segment Commit: 00002000
- DeCommit Block Thres: 00000800
- DeCommit Total Thres: 00002000
- Total Free Size: 0000597f
- Max. Allocation Size: 7ffdefff
- Lock Variable at: 00fa0248
- Next TagIndex: 0000
- Maximum TagIndex: 0000
- Tag Entries: 00000000
- PsuedoTag Entries: 00000000
- Virtual Alloc List: 00fa009c
- 03321000: 00100000 [commited 101000, unused 1000] - busy (b), tail fill
- Uncommitted ranges: 00fa008c
- 01029000: 00076000 (483328 bytes)
- FreeList[ 00 ] at 00fa00c0: 00ffcf40 . 00ff3290
- 00ff3288: 00208 . 00010 [100] - free
- 00fb1370: 00060 . 00010 [100] - free
- 00fb10a0: 00020 . 00010 [100] - free
- 00fa6c40: 00088 . 00010 [100] - free
- 00fa8e98: 00010 . 00010 [100] - free
- 00fafa78: 000d0 . 00018 [100] - free
- 00faea20: 00138 . 00018 [100] - free
- 00fafc38: 00030 . 00020 [100] - free
- 00ff4570: 00128 . 00028 [100] - free
- 00faeeb8: 00058 . 00028 [100] - free
- 00faf0c8: 00060 . 00028 [100] - free
- 00fad980: 00050 . 00028 [100] - free
- 00fb83f0: 00050 . 00040 [100] - free
- 00faed78: 00030 . 00080 [100] - free
- 00feebd8: 000e8 . 00080 [100] - free
- 00faeb80: 00050 . 000d0 [100] - free
- 00ff0398: 00148 . 000d8 [100] - free
- 00fafed0: 000b0 . 000f0 [100] - free
- 00fb8130: 00210 . 00270 [100] - free
- 00fef460: 00808 . 003c8 [100] - free
- 00ffcf38: 003c8 . 2c0a8 [100] - free
- Segment00 at 00fa0000:
- Flags: 00000000
- Base: 00fa0000
- First Entry: 00fa0498
- Last Entry: 0109f000
- Total Pages: 000000ff
- Total UnCommit: 00000076
- Largest UnCommit:00000000
- UnCommitted Ranges: (1)
- Heap entries for Segment00 in Heap 00fa0000
- address: psize . size flags state (requested size)
- 00fa0000: 00000 . 00498 [101] - busy (497)
- 00fa0498: 00498 . 00108 [101] - busy (100)
- 00fa05a0: 00108 . 000d8 [101] - busy (d0)
- ......
- 01029000: 00076000 - uncommitted bytes.
查看Segment
一般来说我们通过上述的命令已经可以基本查看到Segment在一个堆中的信息了。如果要针对一个Segment进行查看可以用如下方式:
- 0:006> dt _HEAP_SEGMENT 00fa0000
- ntdll!_HEAP_SEGMENT
- +0x000 Entry : _HEAP_ENTRY
- +0x008 SegmentSignature : 0xffeeffee
- +0x00c SegmentFlags : 2
- +0x010 SegmentListEntry : _LIST_ENTRY [ 0xfa00a4 - 0xfa00a4 ]
- +0x018 Heap : 0x00fa0000 _HEAP
- +0x01c BaseAddress : 0x00fa0000 Void
- +0x020 NumberOfPages : 0xff
- +0x024 FirstEntry : 0x00fa0498 _HEAP_ENTRY
- +0x028 LastValidEntry : 0x0109f000 _HEAP_ENTRY
- +0x02c NumberOfUnCommittedPages : 0x76
- +0x030 NumberOfUnCommittedRanges : 1
- +0x034 SegmentAllocatorBackTraceIndex : 0
- +0x036 Reserved : 0
- +0x038 UCRSegmentList : _LIST_ENTRY [ 0x1028ff0 - 0x1028ff0 ]
查看申请的内存地址
其实在调试过程中一般最关注的是变量的地址关联的内容信息。比如说我写了个程序其申请的内存变量地址为0x00fb5440, 申请的大小为5字节。
首先可以通过如下命令查找到地址所在的位置为堆:
- 0:000> !address 0x00fb5440
- Building memory map: 00000000
- Mapping file section regions...
- Mapping module regions...
- Mapping PEB regions...
- Mapping TEB and stack regions...
- Mapping heap regions...
- Mapping page heap regions...
- Mapping other regions...
- Mapping stack trace database regions...
- Mapping activation context regions...
- Usage: Heap
- Base Address: 00fa0000
- End Address: 01029000
- Region Size: 00089000 ( 548.000 kB)
- State: 00001000 MEM_COMMIT
- Protect: 00000004 PAGE_READWRITE
- Type: 00020000 MEM_PRIVATE
- Allocation Base: 00fa0000
- Allocation Protect: 00000004 PAGE_READWRITE
- More info: heap owning the address: !heap 0xfa0000
- More info: heap segment
- More info: heap entry containing the address: !heap -x 0xfb5440
然后可以通过如下命令查看当前申请内存的详细堆块信息, 其处于被占用状态(busy)。可以看到其堆块的大小为0x10, 我们实际申请的内存为5字节,那么0x10(Size) - 0xb (Unused) = 5, 可以看出来Unused是包含了_HEAP_ENTRY块元数据的大小的。而我们实际用户可用的内存是8字节 (最小分配粒度),比我们申请的5字节多了三个字节,这也是为什么程序有时候溢出了几个字符,并没有导致程序崩溃或者异常的原因。
- 0:000> !heap -x 0xfb5440
- Entry User Heap Segment Size PrevSize Unused Flags
- -----------------------------------------------------------------------------
- 00fb5438 00fb5440 00fa0000 00fad348 10 - b LFH;busy
那么我们也可以直接查看Entry的结构:
- 0:000> dt _HEAP_ENTRY 00fb5438
- ntdll!_HEAP_ENTRY
- +0x000 UnpackedEntry : _HEAP_UNPACKED_ENTRY
- +0x000 Size : 0xa026
- +0x002 Flags : 0xdc ''
- +0x003 SmallTagIndex : 0x83 ''
- +0x000 SubSegmentCode : 0x83dca026
- +0x004 PreviousSize : 0x1b00
- +0x006 SegmentOffset : 0 ''
- +0x006 LFHFlags : 0 ''
- +0x007 UnusedBytes : 0x8b ''
- +0x000 ExtendedEntry : _HEAP_EXTENDED_ENTRY
- +0x000 FunctionIndex : 0xa026
- +0x002 ContextValue : 0x83dc
- +0x000 InterceptorValue : 0x83dca026
- +0x004 UnusedBytesLength : 0x1b00
- +0x006 EntryOffset : 0 ''
- +0x007 ExtendedBlockSignature : 0x8b ''
- +0x000 Code1 : 0x83dca026
- +0x004 Code2 : 0x1b00
- +0x006 Code3 : 0 ''
- +0x007 Code4 : 0x8b ''
- +0x004 Code234 : 0x8b001b00
- +0x000 AgregateCode : 0x8b001b00`83dca026
如果细心的同学可以能会发现以下两个问题:
- 结构中Size的值是0xa026和之前命令中看到的大小0x10不一样,这个是因为Windows对这些元数据做了编码,需要用堆中的一个编码数据做异或操作才能得到真实的值。具体方法笔者试过,在这里不在赘述,可以在参考文章中获取方法。
- Size是2字节描述,那么最大可以描述的大小应该为0xffff,但是之前不是说最大的块可以是0x7FFF0 (524272字节), 应该不够存储啊?这个也和第一个问题有关联,在通过上述方法计算出的Size之后还需要乘以8, 才是真正的数据大小。
Windows 自建堆的使用建议
在<
保护组件
先看看书中原话:
假如你的应用程序需要保护两个组件,一个是节点结构的链接表,一个是 B R A N C H结构的二进制树。你有两个源代码文件,一个是 L n k L s t . c p p,它包含负责处理N O D E链接表的各个函数,另一个文件是 B i n Tr e e . c p p,它包含负责处理分支的二进制树的各个函数。
现在假设链接表代码中有一个错误,它使节点 1后面的8个字节不
小心被改写了,从而导致分支 3中的数据被破坏。当B i n Tr e e . c p p文件中的代码后来试图遍历二进制树时,它将无法进行这项操作,因为它的内存已经被破坏。当然,这使你认为二进制树代码中存在一个错误,而实际上错误是在链接表代码中。由于不同类型的对象混合放在单个堆栈中,因此跟踪和确定错误将变得非常困难。
我个人认为在一个应用的工程中,也许不需要做到上述那么精细的划分。但是你想一想,在一个大型工程中,会混合多个模块。比如你是做产品的,那么产品会集成其他部门甚至是外部第三方的组件,那么这些组件同时在同一个进程,使用同一个堆的时候,那么难免会出现,A模块的内存溢出问题,导致了B模块的数据处理异常,从而让你追踪问题异常复杂,更坑的是,很可能让B模块的团队背锅了。而这些是切实存在的。 这里的建议更适合于让一些关键模块使用自己的堆,从而降低自己内存使用不当,覆盖了其他组件使用的内存,从而导致异常,让问题的追踪可以集中在出错的模块中。当然这也不是绝对的,因为进程的组件都在同一个地址空间内,内存破坏也存在一种跳跃式内存访问破坏,但是大多数时候内存溢出是连续的上溢较多,这样做确实可以提高这种问题追踪的效率。
更有效的内存管理
这个主要强调是,将同种类型大小的对象放在一个堆中,尽量避免不同大小内存对象掺杂在一起导致的内存碎片问题,从而带来的堆管理效率下降。同一种对象,则可以避免内存碎片问题。当然了这些只是提供了一种思想,至于你的工程是否有必要采用这样的做法,由工程师自己来做决定。
进行本地访问
先来看看原文的描述:
每当系统必须在 R A M与系统的页文件之间进行 R A M页面的交换时,系统的运行性能就会受到很大的影响。如果经常访问局限于一个小范围地址的内存,那么系统就不太可能需要在 R A M与磁盘之间进行页面的交换。
所以,在设计应用程序的时候,如果有些数据将被同时访问,那么最好把它们分配在互相靠近的位置上。让我们回到链接表和二进制树的例子上来,遍历链接表与遍历二进制树之间并无什么关系。如果将所有的节点放在一起(放在一个堆栈中),就可以使这些节点位于相邻的页面上。实际上,若干个节点很可能恰好放入单个物理内存页面上。遍历链接表将不需要 C P U为了访问每个节点而引用若干不同的内存页面。
这个思想其实就是一种Cache思想,RAM与磁盘上的page.sys存储器(磁盘上的虚拟内存)进行页交换会带来一些时间成本。举个极限的例子,你的RAM只有一个页,你有两个对象A和B,A存放在Page1上,而B存放在Page2上,当你访问A对象的时候,必然要把Page1的内容加载到RAM中,那么这个时候B对象所在Page2肯定就在page.sys中,当你又访问B对象的时候,这个时候就得把Page2从page.sys中加载到RAM中替换掉Page1.
理解了页切换带来的性能开销后,其实这一段的思想就是将最可能连续访问的对象放在一个堆中,那么他们在一个页面的可能性也更大,提高了效率。
减少线程同步的开销
这一个很好理解,一般情况下创建的自建堆是支持多线程的,那么多线程的内存分配必然会带来同步的时间消耗,但是对于有些工程来说,只有一个线程,那么对于这一个线程的程序,在调用HeapCreate的时候设置HEAP_NO_SERIALIZE, 则这个堆只支持单线程,从而提高内存申请的效率。
迅速释放堆栈
这种思想第一提高了内存释放的效率,第二是尽可能的降低了内存泄露。记得之前看过一篇文章介绍过Arena感觉比较类似,在一个生命周期内的内存是从Arena申请,然后这个声明周期结束后,不是直接释放各个对象,而是直接销毁这个Arena,提高了释放效率,并且降低了内存泄露的可能。那么使用自建堆的原理和Arena是类似的,比如在一个任务处理之前创建一个堆,在任务处理过程中所申请的内存在这个堆上申请,然后释放的时候,直接销毁这个堆即可。
那对于对象的申请,C++中可以重载new和delete等操作符,来实现自定义的内存分配,并且可以将这个先封装成一个基类,在这个过程中需要创建的对象均继承于这个基类,复用new和delete。
总结和参考
我本以为这些是已经掌握的知识,但是写文章的时间也超过了我预想的时间,在实践中也也发现了一些自己曾经错误的理解。如果文中还有不当的地方,也希望读者给与指正。
参考
《Windows核心编程》
《Windows高级调试》
Windows Heap Chunk Header Parsing and Size Calculation: https://stackoverflow.com/questions/28483473/windows-heap-chunk-header-parsing-and-size-calculation
Understanding the Low Fragmentation Heap: http://www.illmatics.com/Understanding_the_LFH.pdf
WINDOWS 10SEGMENT HEAP INTERNALS: https://www.blackhat.com/docs/us-16/materials/us-16-Yason-Windows-10-Segment-Heap-Internals-wp.pdf