大家好,我是小风哥。
计算机系统中有很多程序员习以为常但又十分神秘的存在:函数调用、系统调用、进程切换、线程切换以及中断处理。
函数调用能让程序员提高代码可复用性,系统调用能让程序员向操作系统发起请求,进程线程切换让多任务成为可能,中断处理能让操作系统管理外部设备。
这些机制是计算机系统中的基石,可是你知道这些机制是如何实现的吗?
这篇文章将告诉你答案,其背后的实现如此优雅且一致。
速度与激。。寄存器
你有没有想过,CPU为什么需要寄存器?
原因很简单:速度。
通常CPU可以在一个时钟周期内访问一次寄存器,CPU访问内存的速度大概要比访问寄存器慢100倍左右。
因此如果CPU没有寄存器而完全依赖内存的话,那么计算速度将比现在慢的多。
作为程序员来说,当我们使用高级语言编写的程序时,其操作的数据都存放在内存中,而对于负责运算类的机器指令来说其操作的数据都存放在寄存器中。
实际上寄存器和内存没有什么本质的区别,都是用来存储信息的。
当然,除了临时保存中间计算结果之外,还有很多有趣的寄存器。根据用途,寄存器有很多类型,但是,我们感兴趣的有以下几种寄存器。
栈寄存器:Stack Pointer
函数在运行时都有一个运行时栈,对于栈来说最重要的信息就是栈顶,栈顶信息就保存在栈寄存器中,stack pointer,通过该寄存器就能跟踪函数的调用栈。
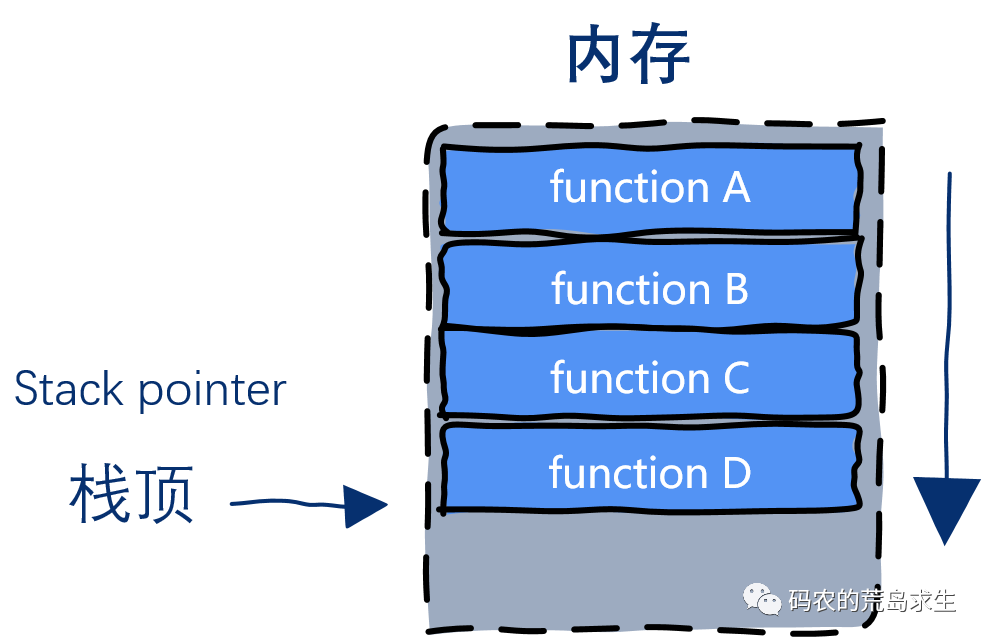
最为程序员我们知道,函数在运行时会有一块独立的内存空间,用来保存函数内定义的局部变量、传递的参数以及返回值信息等,这块独立的内存空间就叫栈帧,随着函数调用层次的加深,栈帧也随之增加;当函数调用完成后栈帧由按照相反的顺序依次减少,这些栈帧就构成了栈区。
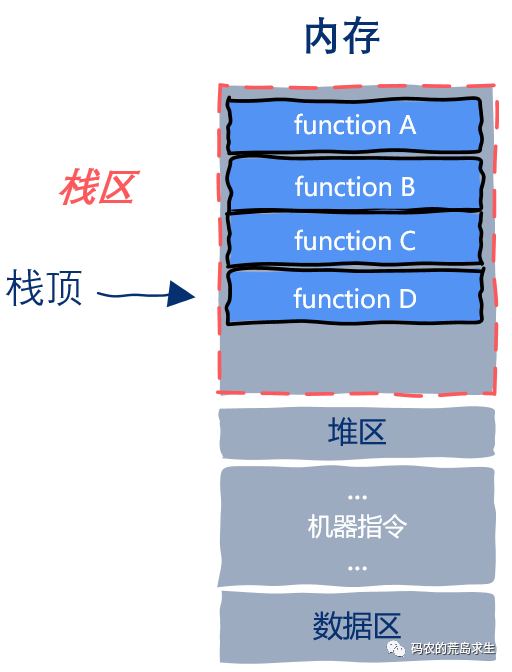
函数的运行时栈信息是关于程序运行状态最重要的信息之一。
那么其它的之一呢?
指令地址寄存器:Program Counter
这类寄存器的名称比较多,基于历史原因,大部分将其称为Program Counter,PC,即我们熟悉的程序计数器;在x86下则被称为Instruction Pointer,IP,怎么称呼不重要,重要的是理解其作用。在本文中统一将其称为PC寄存器。
我们都知道,程序员用高级语言编写的程序最终通过编译器生成最终的机器指令,那么一个问题就是在茫茫的机器指令海洋中,CPU怎么知道该去执行哪条机器指令呢?
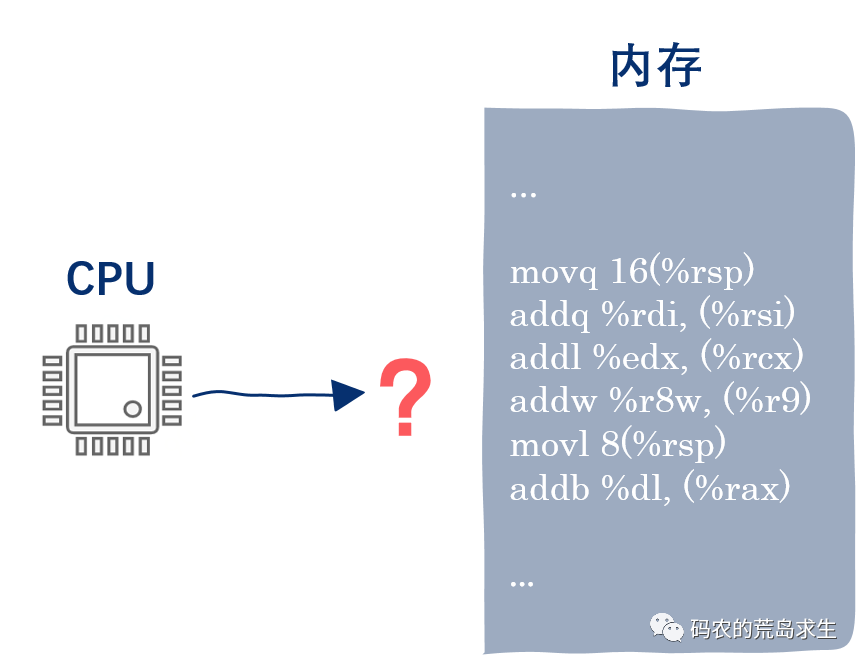
原来,奥秘就藏在指令地址寄存器中。
程序在启动时会把机器指令的首地址写入到PC寄存器中,这样CPU需要做的就是根据PC寄存器中的地址去内存中取出指令。
通常来说,指令都是顺序执行的,也就是说PC寄存器中的值不断的+1,但对于一些涉及控制转移的机器指令来说,这些指令会把一个新的指令地址放到PC寄存器中,这包括分支跳转——也就是if语句、函数调用以及返回等。
控制了CPU的PC寄存器就掌握了CPU的航向,机器指令自己会根据执行状态指挥CPU接下来该去执行哪些指令,这才是真正的自动驾驶,非常amazing有没有!
指令地址寄存器是关于程序运行时状态另一个最重要的信息之一。
状态寄存器:Status Register
CPU内部除了上述两类寄存器外,还有一类状态寄存器,Status Register;在x86架构下被称为FLAGS register,ARM架构下被称为application program status register,以下统称状态寄存器。
从名字也能看出来,该寄存器是保存状态信息的,有什么有趣的状态信息呢?
比如对于涉及到算术运算的指令来说,其在执行过程中可能会产生进位,也可能会溢出,那么这些信息就保存在状态寄存器中。
除此之外,你肯定听说过程序的执行一般有两种模式:内核态和用户态。
对于大部分的程序员其编写的应用程序运行在用户态,在用户态下不能执行特权指令,比如你没办法写一个程序直接去控制系统中的各种硬件资源。
而在内核态下,CPU可以执行任意的特权指令,内核就工作在内核态,因此内核可以掌控一切。关于用户态内核态完整的阐述参见博主深入理解操作系统第2章,关注公众号码农的荒岛求生并回复操作系统即可。
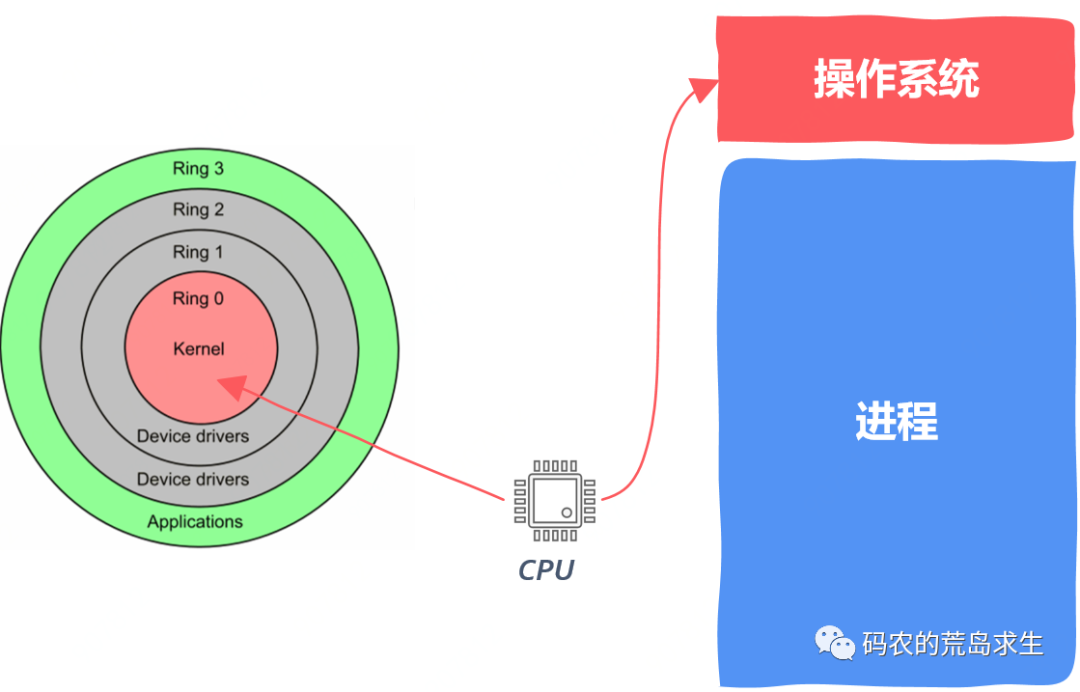
那么我们怎么知道当前程序运行在哪种状态呢?
答案就在CPU内部的状态寄存器中,该寄存器中有特定的比特位来标记当前CPU正工作在哪种模式下。
现在你应该知道寄存器的重要作用了吧。
上下文:Context
通过这些寄存器,你可以知道程序运行到当前这一刻时最细粒度的切面,这一时刻这些寄存器中保存的所有信息就是我们通常所说的上下文,context。
上下文的作用是什么呢?
只要你能拿到一个程序运行时的上下文并保存起来,那么你可以随时暂停该程序的运行,也可以随时利用该信息恢复该程序的运行。
为什么要保存和恢复上下文信息呢?原因就在于CPU的个数是有限的,这就意味一个CPU可能会执行多个进程,即这些进程要共享该CPU资源,更具体的是CPU的计算资源和这里所说的各种寄存器。
这是实现函数调用、系统调用、进程切换、线程切换以及中断处理的基本机制。
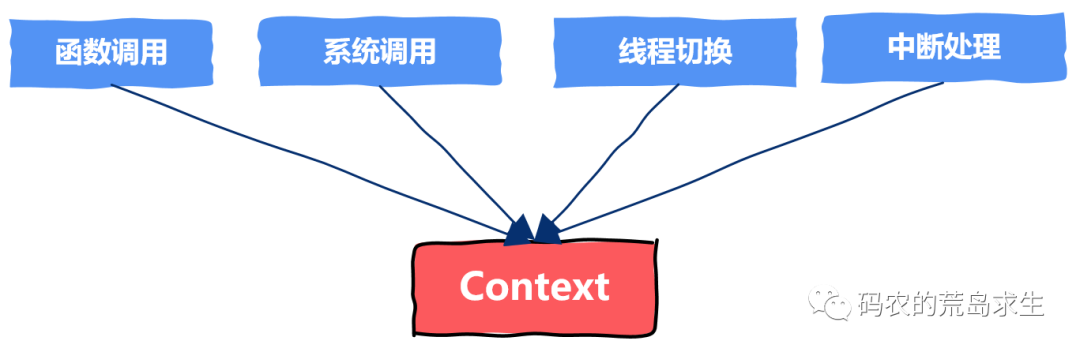
而程序在运行过程中逃不出函数调用、系统调用、进程切换、线程切换以及中断处理这几项操作,由此可见上下文信息的保存和恢复在计算机科学中重要的作用。
那么上下文信息又该如何保存呢?保存到哪里呢?又该怎么恢复呢?函数调用、系统调用、进程切换、线程切换以及中断处理又是怎样实现的呢?
游戏与栈
经常玩游戏的同学应该都知道,游戏里有主线,有时在主线任务中还要去完成一些支线任务,也就是说任务A依赖任务B,任务B依赖任务C,那么任务的依赖关系是这样的:
- A -> B -> C
那么很显然只有完成任务C你才能继续任务B,完成任务B才能继续任务A,因此任务完成顺序是这样的:
- C-> B -> A
我们可以看到任务完成顺序和任务依赖顺序是相反的:先来的反而后完成。
这天然适合栈来表示。
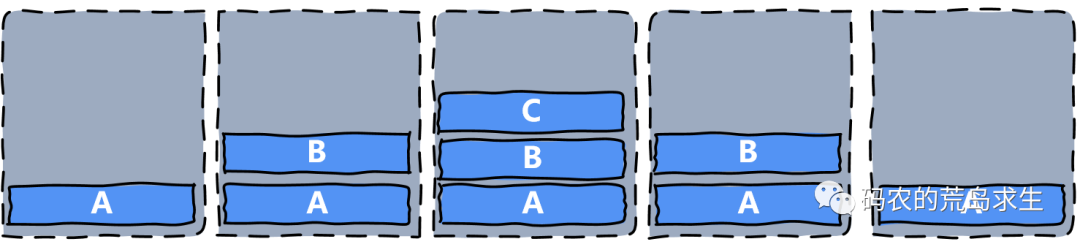
这里特别值得注意的是,栈是一种机制,和其本身是怎么实现的没有关系,你可以用软件来实现栈,也可以用硬件来实现栈。
栈是一种如此简单的结构,却又如此强大。栈是实现计算机系统的一种极为重要的基础机制,接下来的讲解就能让你意识到栈的重要作用。
函数调用与运行时栈
函数是编程语言中最重要的概念之一,函数让代码复用成为可能,你知道函数调用是如何实现的吗?
函数调用的难点在于CPU不能在平铺直叙的往前依次顺序的执行机器指令,而是要跳转到被调函数的第一条机器指令,执行完该函数后还要跳转回来。
当你从A函数跳转到B函数时,A函数被暂停运行,当被调函数执行完后A函数继续运行。
因此这里就涉及到A函数的状态保存与状态恢复。
函数的运行时状态有什么呢?
主要有返回地址以及使用的寄存器信息,这就是在本文开头讲解的寄存器,我们将其称为函数运行时上下文,简称为context。
这些context保存在哪里呢?我想你已经猜到了,没错,就是栈中,我们为每个函数分配一块空间,当A函数调用B函数时,我们在这块空间中保存该函数的context,当B函数执行结束后,我们再用该context恢复A函数的运行。
如果是A函数调用B函数,B函数调用C函数的话,那么:

这块用来保存context的空间就是栈帧,当然这里不止保存上下文信息,还保存有函数参数,局部变量等信息。
从这里我们可以看到,栈+上下文让我们实现了函数调用。
当然限于篇幅,这里关于函数运行时栈的讲解非常简略,关于这一部分更加详细的讲解关注公众号码农的荒岛求生并回复关键词运行时栈即可。
系统调用与内核栈
当我们读写磁盘文件或者创建新的线程时,你有没有想过到底是谁帮你读写的文件,是谁帮你创建的线程呢?
答案是操作系统。
是的,当你调用类似open这样的函数时,其实是操作系统在帮你完成文件打开操作,用户程序向操作系统请求服务就是通过系统调用实现的。
好奇的同学可能会继续问,既然是操作系统来完成这些请求,那么操作系统内部肯定也是调用一系列函数来完成请求处理,有函数调用就需要运行时栈,那么操作系统完成系统调用所需要的运行时栈在哪里呢?
答案就在内核栈中,Kernel Stack。
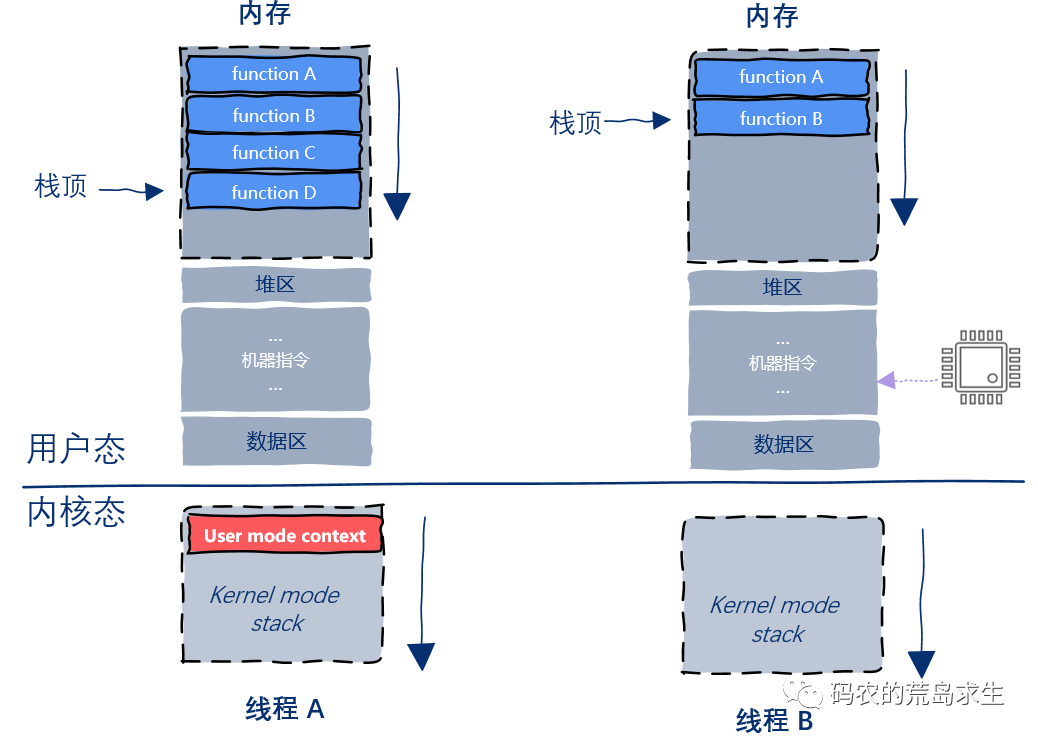
原来,每一个用户态线程在内核态都有一个对应的内核栈:
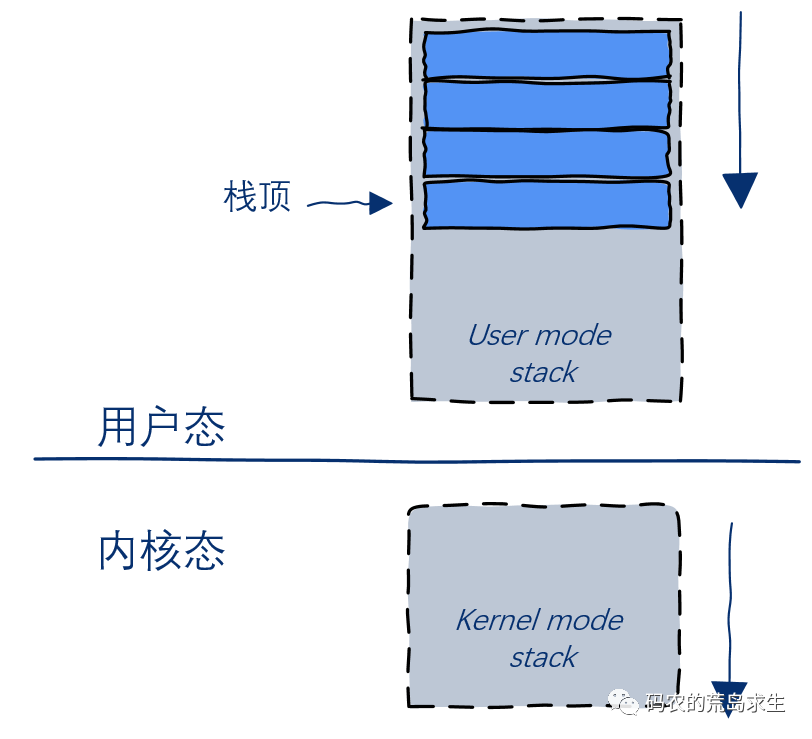
当用户线程需要请求操作系统服务时利用系统调用切换到内核模式,这时内核开始代表该用户态线程执行,内核的执行过程需要的运行时栈就放在了上图中的内核栈中。
让我们来看一下系统调用的过程。
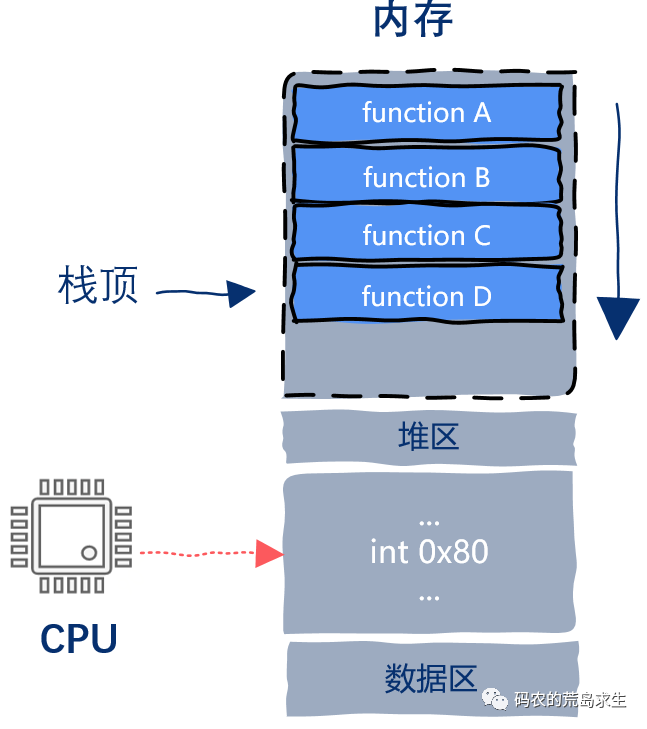
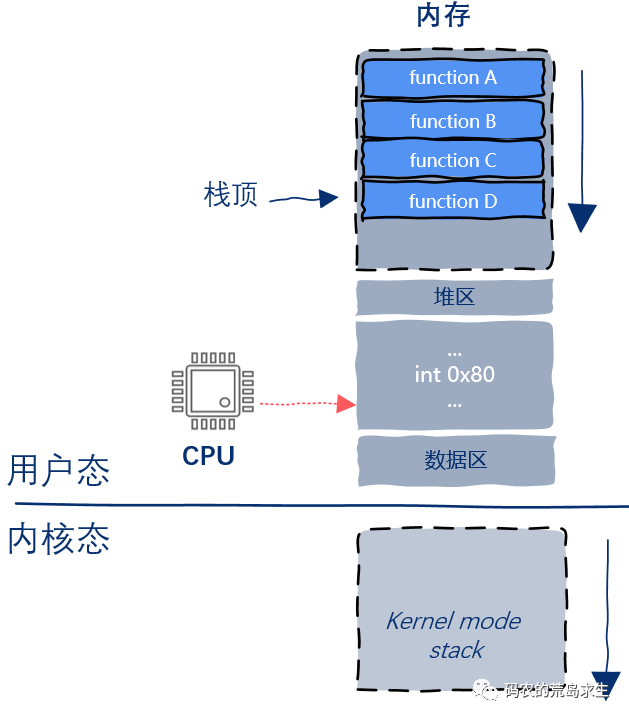
开始时,程序运行在用户态,此时内核栈还是空的,假设用户态执行到functionD时需要请求操作系统服务,假设functionD需要调用open函数,该函数内部包含就系统调用,被编译器翻译后会生成一条int指令,此时CPU执行到该指令:
该指令的执行将触发CPU的状态切换,此时CPU从用户态切换为内核态,并找到该用户态线程对应的内核线程,注意重点来了,此时用户态线程的执行上下文信息(寄存器信息)被保存在内核栈中:
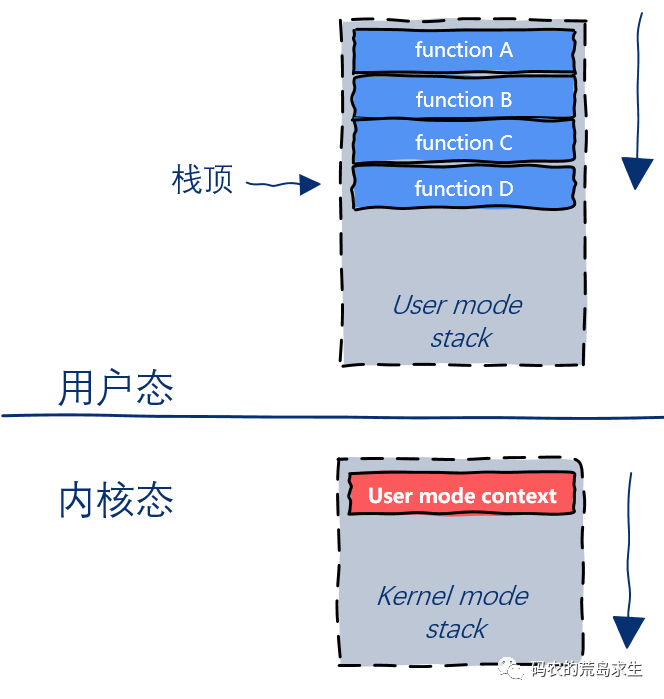
此后CPU开始在内核中执行open相关的操作,后续内核栈会像用户态运行时栈一样随着函数的调用和返回增长以及减少:
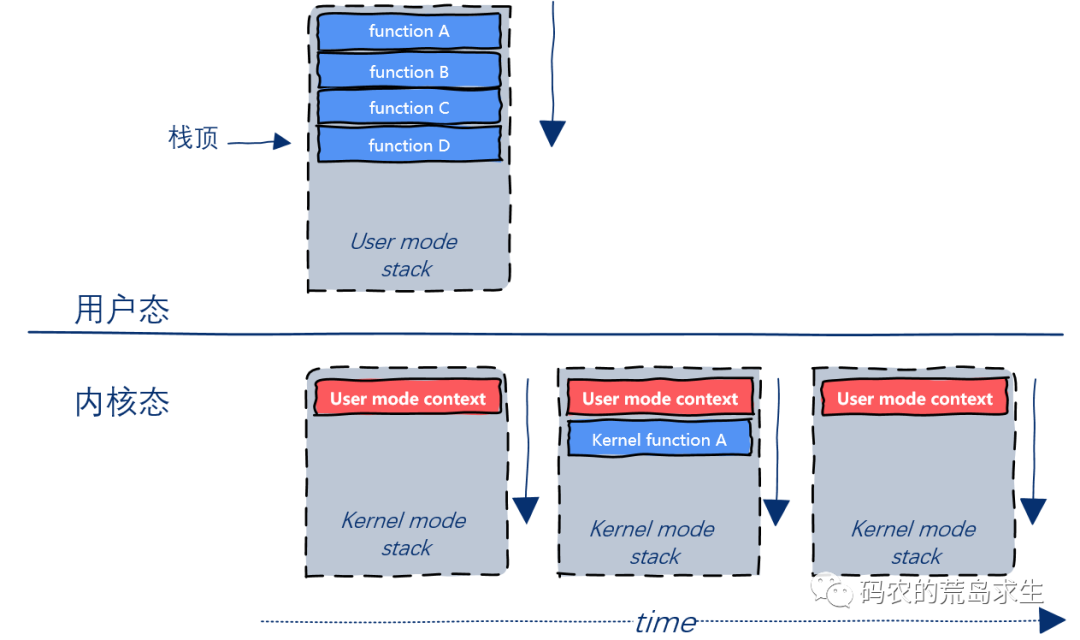
当系统调用执行完成后,根据内核栈中保存的用户态程序上下文信息恢复CPU状态,并从内核态切换回用户态,这样用户态线程就可以继续运行了:
现在你应该明白这个过程了吧。
那么操作系统为什么要这么麻烦的费心维护用户态以及内核态呢?用户态程序为什么要利用系统调用来请求操作系统服务呢?不能直接像普通函数一样调用操作系统的代码吗?关于这些问题的答案,你可以参考博主的深入理解操作系统第2章,关注公众号码农的荒岛求生并回复操作系统这几个字即可。
中断与中断函数栈
现在我们已经讲解了两种涉及CPU上下文切换的场景,包括函数调用以及系统调用,接下来我们再看一种,中断处理。
你的计算机之所以能接受键盘按键、鼠标指针、网络数据等,都是通过中断机制来完成的。
中断本质上就是打断当前CPU的执行流,跳转到具体的中断处理函数中,当中断处理函数执行完成后再跳转回来。
既然中断处理函数也是函数,那么必然和普通函数一样需要运行时栈,那么中断处理函数的运行时栈又在哪里呢?
这分为两种情况:
- 中断处理函数是没有自己特定的栈的,中断处理函数依赖内核栈来完成中断处理。
- 中断处理函数有自己特定的栈,被称之为ISR栈,ISR是interrupt service routine的简写,即中断处理函数栈。由于处理中断的是CPU,因此在这种方案下每个CPU都有一个自己的中断处理栈。
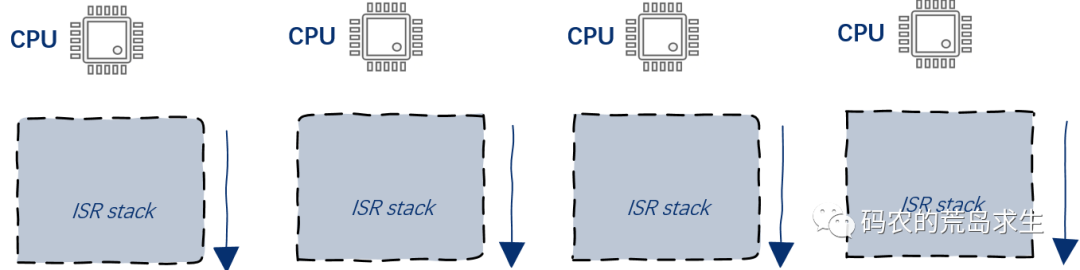
为了简单起见,我们以中断处理函数共享内核栈为例来讲解。
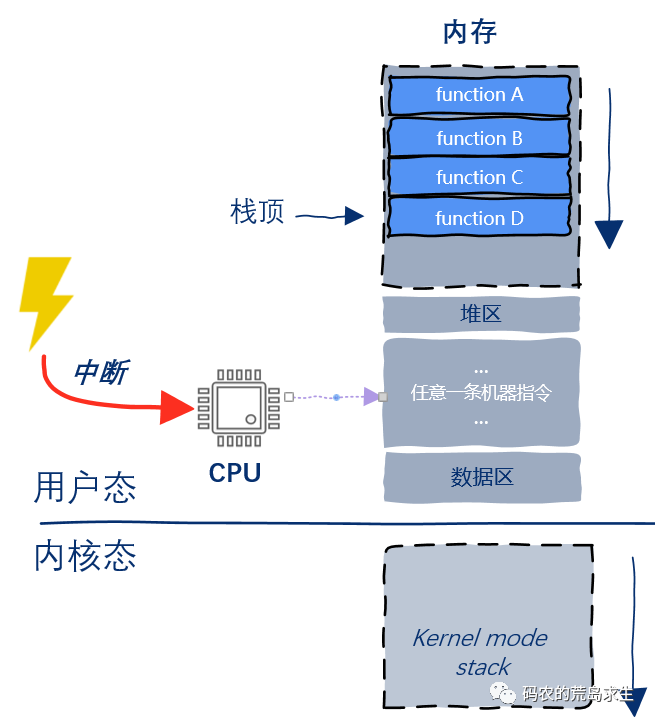
实际上你会发现中断处理函数和系统调用比较类似,不同的是系统调用是用户态程序主动发起的,而中断处理是外部设备发起的,也就是说CPU在执行完用户态的任何一条指令后都可能因为中断产生而暂停当前程序的执行转而去执行中断处理函数,如图所示:
此后的故事和系统调用类似,CPU从用户态切换为内核态,并找到该用户态线程对应的内核线程,并将用户态线程的执行上下文信息保存在内核栈中:
此后CPU跳转到中断处理函数起始地址,中断处理函数在运行过程中内核栈会像用户态运行时栈一样随着函数的调用和返回增长以及减少:
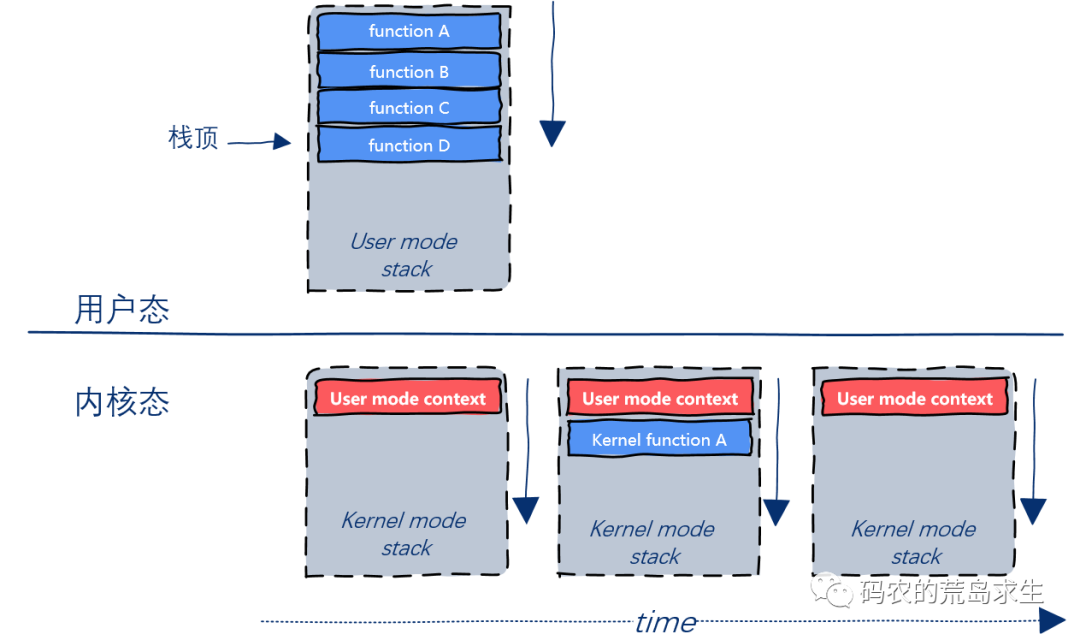
当中断处理函数执行完成后,根据内核栈中保存的用户态程序上下文信息恢复CPU状态,并从内核态切换回用户态,这样用户态线程就可以继续运行了。
每一次你敲击键盘、滑动鼠标、下载文件等都会有一次上述过程。关于中断处理更加完整的阐述参见博主深入理解操作系统第3章,关注公众号码农的荒岛求生并回复操作系统即可。
既然你已经知道了中断是如何实现的,接下来让我们看下最有意思的线程切换是如何实现的。
线程切换与内核栈
现在我们知道了每个线程除了用户态的函数运行时栈之外还有一个我们看不见的内核栈,系统调用陷入内核后,开始将用户态上下文信息保存在相应的内核栈上,此后内核代表该线程在内核中执行相应的操作,执行结束后根据内核栈上保存的上下文信息恢复用户态线程。
那么线程切换是如何实现的呢?线程切换是如何给CPU实施换颅术的呢?
本文剩余部分已收录至小风哥的深入理解操作系统第五章第四节,关注公众号码农的荒岛求生并回复操作系统即可。
总结
程序的运行状态说到底就是CPU内部的一些寄存器信息,比如指向运行时栈顶的栈寄存器、指向下一条要执行指令的PC寄存器等,这些被称为上下文信息,能得到这些信息你就能给暂停或者回复程序的运行。
上下文信息的保存与恢复通常通过栈这种机制来实现,栈FILO的特性天然适合应对该场景,这也使得栈成为计算机系统中最为重要的数据结构之一。
上下文信息+栈的组合使得函数调用、系统调用、进程切换、线程切换以及中断处理成为可能。
我是小风哥,希望这篇文章对大家理解CPU以及程序运行有所帮助。
本文转载自微信公众号「码农的荒岛求生」,可以通过以下二维码关注。转载本文请联系码农的荒岛求生公众号。