1. 概述
本文主要讲解MaxCompute Spark资源调优,目的在于在保证Spark任务正常运行的前提下,指导用户更好地对Spark作业资源使用进行优化,极大化利用资源,降低成本。
2. Sensor
Sensor提供了一种可视化的方式监控运行中的Spark进程,每个worker(Executor)及master(Driver)都具有各自的状态监控图,可以通过Logview中找到入口,如下图所示:
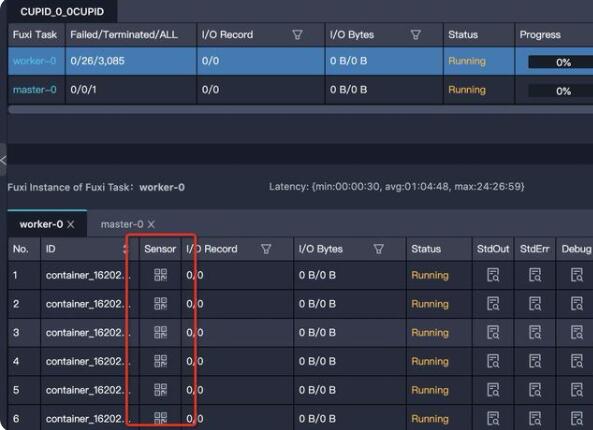
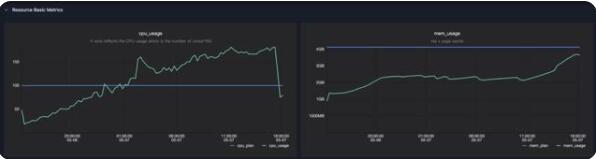
打开Sensor之后,可以看到下图提供了Driver/Executor在其生命周期内的CPU和内存的使用情况:
cpu_plan/mem_plan(蓝线)代表了用户申请的CPU和内存计划量
用户可以直观地从cpu_usage图中看出任务运行中的CPU利用率
mem_usage代表了任务运行中的内存使用,是mem_rss和page cache两项之和,详见下文
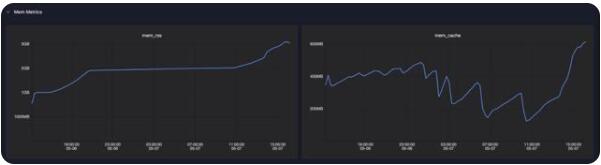
Memory Metrics
mem_rss 代表了进程所占用了常驻内存,这部分内存也就是Spark任务运行所使用的实际内存,通常需要用户关注,如果该内存超过用户申请的内存量,就可能会发生OOM,导致Driver/Executor进程终止。此外,该曲线也可以用于指导用户进行内存优化,如果实际使用量远远小于用户申请量,则可以减少内存申请,极大化利用资源,降低成本。
mem_cache(page_cache)用于将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,通常由系统进行管理,如果物理机内存充足,那么mem_cache可能会使用很多,用户可以不必关心该内存的分配和回收。
3. 资源参数调优
(1)Executor Cores
相关参数:spark.executor.cores
每个Executor的核数,即每个Executor中的可同时运行的task数目
Spark任务的最大并行度是num-executors * executor-cores
Spark任务执行的时候,一个CPU core同一时间最多只能执行一个Task。如果CPU core数量比较充足,通常来说,可以比较快速和高效地执行完这些Task。同时也要注意,每个Executor的内存是多个Task共享的,如果单个Executor核数太多,内存过少,那么也很可能发生OOM。
(2)Executor Num
相关参数:spark.executor.instances
该参数用于设置Spark作业总共要用多少个Executor进程来执行
通常用户可以根据任务复杂度来决定到底需要申请多少个Executor
此外,需要注意,如果出现Executor磁盘空间不足,或者部分Executor OOM的问题,可以通过减少单个Executor的cores数,增加Executor的instances数量来保证任务总体并行度不变,同时降低任务失败的风险。
(3)Executor Memory
相关参数:spark.executor.memory
该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且JVM OOM在Executor中更为常见。
相关参数2:spark.executor.memoryOverhead
设置申请Executor的堆外内存,主要用于JVM自身,字符串, NIO Buffer等开销,注意memoryOverhead 这部分内存并不是用来进行计算的,用户代码及spark都无法直接操作。
如果不设置该值,那么默认为spark.executor.memory * 0.10,最小为384 MB
Executor 内存不足的表现形式:
在Executor的日志(Logview->某个Worker->StdErr)中出现Cannot allocate memory

在任务结束的Logview result的第一行中出现:The job has been killed by "OOM Killer", please check your job's memory usage.
在Sensor中发现内存使用率非常高
在Executor的日志中出现java.lang.OutOfMemoryError: Java heap space
在Executor的日志中出现GC overhead limit exceeded
Spark UI中发现频繁的GC信息
可能出现OOM的间接表现形式:部分Executor出现No route to host: workerd********* / Could not find CoarseGrainedScheduler等错误
可能原因及解决方案:
限制executor 并行度,将cores 调小:多个同时运行的 Task 会共享一个Executor 的内存,使得单个 Task 可使用的内存减少,调小并行度能缓解内存压力增加单个Executor内存
增加分区数量,减少每个executor负载
考虑数据倾斜问题,因为数据倾斜导致某个 task 内存不足,其它 task 内存足够
如果出现了上文所述的Cannot allocate memory或The job has been killed by "OOM Killer", please check your job's memory usage,这种情况通常是由于系统内存不足,可以适当增加一些堆外内存来缓解内存压力,通常设置spark.executor.memoryOverhead为1g/2g就足够了
(4)Driver Cores
相关参数spark.driver.cores
通常Driver Cores不需要太大,但是如果任务较为复杂(如Stage及Task数量过多)或者Executor数量过多(Driver需要与每个Executor通信并保持心跳),在Sensor中看到Cpu利用率非常高,那么可能需要适当调大Driver Cores
另外要注意,在Yarn-Cluster模式运行Spark任务,不能直接在代码中设置Driver的资源配置(core/memory),因为在JVM启动时就需要该参数,因此需要通过--driver-memory命令行选项或在spark-defaults.conf文件/Dataworks配置项中进行设置。
(5)Driver Memory
相关参数1:spark.driver.memory
设置申请Driver的堆内内存,与executor类似
相关参数2:spark.driver.maxResultSize
代表每个Spark的action(例如collect)的结果总大小的限制,默认为1g。如果总大小超过此限制,作业将被中止,如果该值较高可能会导致Driver发生OOM,因此用户需要根据作业实际情况设置适当值。
相关参数3:spark.driver.memoryOverhead
设置申请Driver的堆外内存,与executor类似
Driver的内存通常不需要太大,如果Driver出现内存不足,通常是由于Driver收集了过多的数据,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大。
表现形式:
Spark应用程序无响应或者直接停止
在Driver的日志(Logview->Master->StdErr)中发现了Driver OutOfMemory的错误
Spark UI中发现频繁的GC信息
在Sensor中发现内存使用率非常高
在Driver的日志中出现Cannot allocate memory
可能原因及解决方案:
代码可能使用了collect操作将过大的数据集收集到Driver节点
在代码创建了过大的数组,或者加载过大的数据集到Driver进程汇总
SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。有时候如果stage过多,Driver端甚至会有栈溢出
(6)本地磁盘空间
相关参数:spark.hadoop.odps.cupid.disk.driver.device_size:
该参数代表为单个Driver或Executor申请的磁盘空间大小,默认值为20g,最大支持100g
Shuffle数据以及BlockManager溢出的数据均存储在磁盘上
磁盘空间不足的表现形式:
在Executor/Driver的日志中发现了No space left on device错误
解决方案:
最简单的方法是直接增加更多的磁盘空间,调大spark.hadoop.odps.cupid.disk.driver.device_size
如果增加到100g之后依然出现该错误,可能是由于存在数据倾斜,shuffle或者cache过程中数据集中分布在某些block,也可能是单个Executor的shuffle数据量确实过大,可以尝试:
对数据重分区,解决数据倾斜问题
缩小单个Executor的任务并发spark.executor.cores
缩小读表并发spark.hadoop.odps.input.split.size
增加executor的数量spark.executor.instances
需要注意:
同样由于在JVM启动前就需要挂载磁盘,因此该参数必须配置在spark-defaults.conf文件或者dataworks的配置项中,不能配置在用户代码中
此外需要注意该参数的单位为g,不能省略g
很多时候由于用户配置位置有误或者没有带单位g,导致参数实际并没有生效,任务运行依然失败
4. 总结
上文主要介绍了MaxCompute Spark在使用过程中可能遇到的资源不足的问题及相应的解决思路,为了能够最大化利用资源,首先建议按照1: 4的比例来申请单个worker资源,即1 core: 4 gb memory,如果出现OOM,那么需要查看日志及Sensor对问题进行初步定位,再进行相应的优化和资源调整。不建议单个Executor Cores 设置过多,通常单个Executor在2-8 core是相对安全的,如果超过8,那么建议增加instance数量。适当增加堆外内存(为系统预留一些内存资源)也是一个常用的调优方法,通常在实践中可以解决很多OOM的问题。最后,用户可以参考官方文档https://spark.apache.org/docs/2.4.5/tuning.html,包含更多的内存调优技巧,如gc优化,数据序列化等。