前言
我们经常都会碰到延迟任务,定时任务这种需求。在网络连接的场景中,常常会出现一些超时控制。随着连接数量的增加,这些超时任务的数量往往也是很庞大的。实现对大量任务的超时管理并不是一个容易的事情。
几种定时任务的实现
java.util.Timer
JDK 在 1.3 的时候引入了Timer数据结构用于实现定时任务。Timer的实现思路比较简单,其内部有两个主要属性:
- TaskQueue:定时任务抽象类TimeTask的列表。
- TimerThread:用于执行定时任务的线程。
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
- 1.
- 2.
Timer结构还定义了一个抽象类TimerTask并且继承了Runnable接口。业务系统实现了这个抽象类的run方法用于提供具体的延时任务逻辑。
TaskQueue内部采用大顶堆的方式,依据任务的触发时间进行排序。而TimerThread则以死循环的方式从TaskQueue获取队列头,等待队列头的任务的超时时间到达后触发该任务,并且将任务从队列中移除。
Timer的数据结构和算法都很容易理解。所有的超时任务都首先进入延时队列。后台超时线程不断的从延迟队列中获取任务并且等待超时时间到达后执行任务。延迟队列采用大顶堆排序,在延迟任务的场景中有三种操作,分别是:添加任务,提取队列头任务,查看队列头任务。
查看队列头任务的事件复杂度是 O(1) 。而添加任务和提取队列头任务的时间复杂度都是 O(Logn) 。当任务数量较大时,添加和删除的开销也是比较大的。此外,由于Timer内部只有一个处理线程,如果有一个延迟任务的处理消耗了较多的时间,会对应的延迟后续任务的处理。
代码如下:
public static void main(String[] args) {
Timer timer = new Timer();
// 延迟 1秒 执行任务
timer.schedule(
new java.util.TimerTask() {
@Override
public void run() {
System.out.println("延迟 1秒 执行任务"+System.currentTimeMillis());
}
}
,1000);
timer.schedule(
new java.util.TimerTask() {
@Override
public void run() {
System.out.println("延迟 2秒 执行任务"+System.currentTimeMillis());
}
}
,2000);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
timer.cancel();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
ScheduledThreadPoolExecutor
由于Timer只有一个线程用来处理延迟任务,在任务数量很多的时候显然是不足够的。在 JDK1.5 引入线程池接口ExecutorService后,也对应的提供了一个用于处理延时任务的ScheduledExecutorService子类接口。该接口内部也一样使用了一个使用小顶堆进行排序的延迟队列存放任务。线程池中的线程会在这个队列上等待直到有任务可以提取。
整体来说,ScheduledExecutorService 区别于 Timer 的地方就在于前者依赖了线程池来执行任务,而任务本身会判断是什么类型的任务,需要重复执行的在任务执行结束后会被重新添加到任务队列。
而对于后者来说,它只依赖一个线程不停的去获取队列首部的任务并尝试执行它,无论是效率上、还是安全性上都比不上前者。
ScheduledExecutorService的实现上有一些特殊,只有一个线程能够提取到延迟队列头的任务,并且根据任务的超时时间进行等待。在这个等待期间,其他的线程是无法获取任务的。这样的实现是为了避免多个线程同时获取任务,导致超时时间未到达就任务触发或者在等待任务超时时间时有新的任务被加入而无法响应。
由于ScheduledExecutorService可以使用多个线程,这样也缓解了因为个别任务执行时间长导致的后续任务被阻塞的情况。不过延迟队列也是一样采用小顶堆的排序方式,因此添加任务和删除任务的时间复杂度都是 O(Logn) 。在任务数量很大的情况下,性能表现比较差。
代码如下:
public class ScheduledThreadPoolServiceTest {
// 参数代表可以同时执行的定时任务个数
private ScheduledExecutorService service = Executors.newScheduledThreadPool(3);
/**
* schedule:延时2秒执行一次任务
*/
public void task0() {
service.schedule(() -> {
System.out.println("task0-start");
sleep(2);
System.out.println("task0-end");
}, 2, TimeUnit.SECONDS);
}
/**
* scheduleAtFixedRate:2秒后,每间隔4秒执行一次任务
* 注意,如果任务的执行时间(例如6秒)大于间隔时间,则会等待任务执行结束后直接开始下次任务
*/
public void task1() {
service.scheduleAtFixedRate(() -> {
System.out.println("task1-start");
sleep(2);
System.out.println("task1-end");
}, 2, 4, TimeUnit.SECONDS);
}
/**
* scheduleWithFixedDelay:2秒后,每次延时4秒执行一次任务
* 注意,这里是等待上次任务执行结束后,再延时固定时间后开始下次任务
*/
public void task2() {
service.scheduleWithFixedDelay(() -> {
System.out.println("task2-start");
sleep(2);
System.out.println("task2-end");
}, 2, 4, TimeUnit.SECONDS);
}
private void sleep(long time) {
try {
TimeUnit.SECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
ScheduledThreadPoolServiceTest test = new ScheduledThreadPoolServiceTest();
System.out.println("main start");
test.task0();
//test.task1();
// test.task2();
test.sleep(10);
System.out.println("main end");
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
DelayQueue
Java 中还有个延迟队列 DelayQueue,加入延迟队列的元素都必须实现 Delayed 接口。延迟队列内部是利用 PriorityQueue 实现的,所以还是利用优先队列!Delayed 接口继承了Comparable 因此优先队列是通过 delay 来排序的。
Redis sorted set
Redis的数据结构Zset,同样可以实现延迟队列的效果,主要利用它的score属性,redis通过score来为集合中的成员进行从小到大的排序。zset 内部是用跳表实现的。
跳表数据结构的示意图:
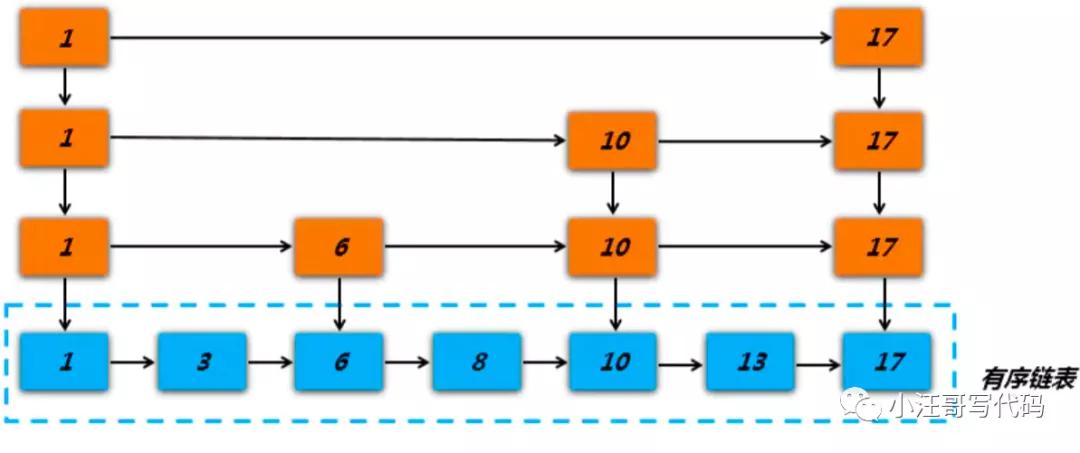
总体上,跳跃表删除操作的时间复杂度是O(logN)。
有没有更高效的数据结构?
Timer 、ScheduledThreadPool 、 DelayQueue,总结的说下它们都是通过优先队列来获取最早需要执行的任务,因此插入和删除任务的时间复杂度都为O(logn),并且 Timer 、ScheduledThreadPool 的周期性任务是通过重置任务的下一次执行时间来完成的。
但是由于新增任务和提取任务的时间复杂度都是 O(Logn) ,在任务数量很大,比如几万,十几万的时候,性能的开销就变得很巨大。
问题就出在时间复杂度上,插入删除时间复杂度是O(logn),那么假设频繁插入删除次数为 m,总的时间复杂度就是O(mlogn)
那么,是否存在新增任务和提取任务比 O(Log2n) 复杂度更低的数据结构呢?答案是存在的。在论文《Hashed and Hierarchical Timing Wheels》中设计了一种名为时间轮( Timing Wheels )的数据结构,这种结构在处理延迟任务时,其新增任务和删除任务的时间复杂度降低到了 O(1) 。
时间轮算法
基本原理
见名知意,时间轮的数据结构很类似于我们钟表上的数据指针。
时间轮用环形数组实现,数组的每个元素可以称为槽,和 HashMap一样称呼。
槽的内部用双向链表存着待执行的任务,添加和删除的链表操作时间复杂度都是 O(1),槽位本身也指代时间精度,比如一秒扫一个槽,那么这个时间轮的最高精度就是 1 秒。
也就是说延迟 1.2 秒的任务和 1.5 秒的任务会被加入到同一个槽中,然后在 1 秒的时候遍历这个槽中的链表执行任务。
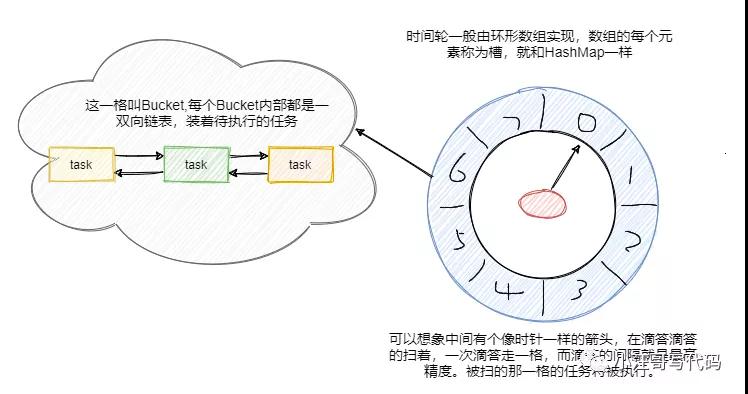
任务插入
当有一个延迟任务要插入时间轮时,首先计算其延迟时间与单位时间的余值,从指针指向的当前槽位移动余值的个数槽位,就是该延迟任务需要被放入的槽位。
举个例子,时间轮有8个槽位,编号为 0 ~ 7 。指针当前指向槽位 2 。新增一个延迟时间为 4 秒的延迟任务,4 % 8 = 4,因此该任务会被插入 4 + 2 = 6,也就是槽位6的延迟任务队列。
时间槽位的实现
时间轮的槽位实现可以采用循环数组的方式达成,也就是让指针在越过数组的边界后重新回到起始下标。概括来说,可以将时间轮的算法描述为:
用队列来存储延迟任务,同一个队列中的任务,其延迟时间相同。用循环数组的方式来存储元素,数组中的每一个元素都指向一个延迟任务队列。
有一个当前指针指向数组中的某一个槽位,每间隔一个单位时间,指针就移动到下一个槽位。被指针指向的槽位的延迟队列,其中的延迟任务全部被触发。
在时间轮中新增一个延迟任务,将其延迟时间除以单位时间得到的余值,从当前指针开始,移动余值对应个数的槽位,就是延迟任务被放入的槽位。
基于这样的数据结构,插入一个延迟任务的时间复杂度就下降到 O(1) 。而当指针指向到一个槽位时,该槽位连接的延迟任务队列中的延迟任务全部被触发。
延迟任务的触发和执行不应该影响指针向后移动的时间精确性。因此一般情况下,用于移动指针的线程只负责任务的触发,任务的执行交由其他的线程来完成。比如,可以将槽位上的延迟任务队列放入到额外的线程池中执行,然后在槽位上新建一个空白的新的延迟任务队列用于后续任务的添加。
关于扩容
那假设现在要加入一个50秒后执行的任务怎么办?这槽好像不够啊?难道要加槽嘛?和HashMap一样扩容?
假设要求精度为 1 秒,要能支持延迟时间为 1 天的延迟任务,时间轮的槽位数需要 60 × 60 × 24 = 86400 。这就需要消耗更多的内存。显然,单纯增加槽位数并不是一个好的解决方案。
常见有两种方式:
通过增加轮次。50 % 8 + 1 = 3,即应该放在槽位是 3,下标是 2 的位置。然后 (50 - 1) / 8 = 6,即轮数记为 6。也就是说当循环 6 轮之后扫到下标的 2 的这个槽位会触发这个任务。Netty 中的 HashedWheelTimer 使用的就是这种方式。
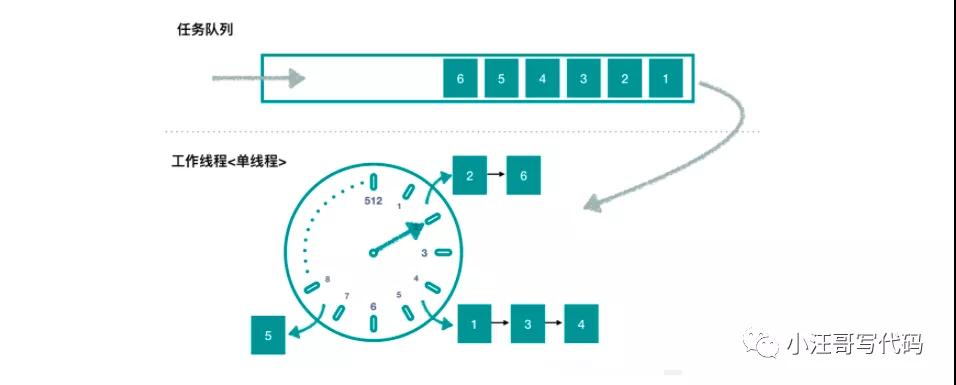
通过多层次。这个和我们的手表就更像了,像我们秒针走一圈,分针走一格,分针走一圈,时针走一格。
多层次时间轮就是这样实现的。假设上图就是第一层,那么第一层走了一圈,第二层就走一格。
可以得知第二层的一格就是8秒,假设第二层也是 8 个槽,那么第二层走一圈,第三层走一格,可以得知第三层一格就是 64 秒。
那么一格三层,每层8个槽,一共 24 个槽时间轮就可以处理最多延迟 512 秒的任务。
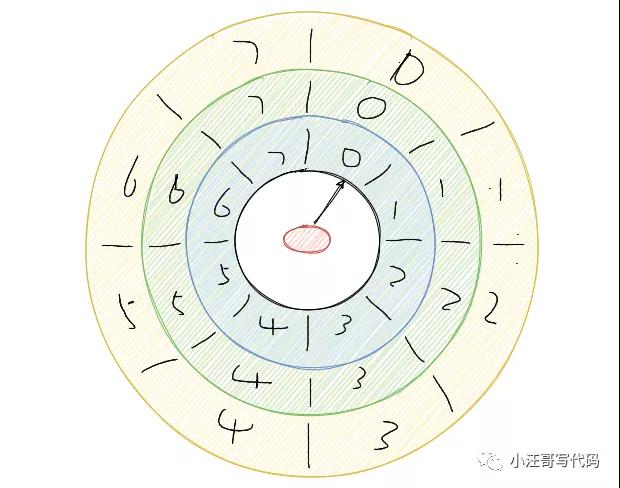
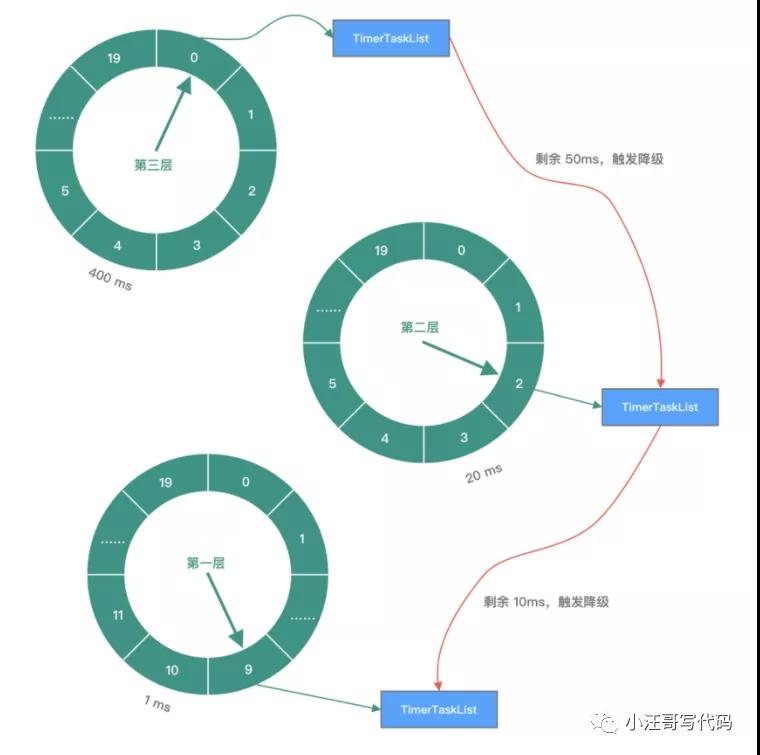
而多层次时间轮还会有降级的操作,假设一个任务延迟 500 秒执行,那么刚开始加进来肯定是放在第三层的,当时间过了 436 秒后,此时还需要 64 秒就会触发任务的执行,而此时相对而言它就是个延迟 64 秒后的任务,因此它会被降低放在第二层中,第一层还放不下它。
再过个 56 秒,相对而言它就是个延迟 8 秒后执行的任务,因此它会再被降级放在第一层中,等待执行。
降级是为了保证时间精度一致性。Kafka内部用的就是多层次的时间轮算法。
降级过程:
本文转载自微信公众号「小汪哥写代码」,可以通过以下二维码关注。转载本文请联系小汪哥写代码公众号。