1.什么是SLI/SLO
SLI,全名Service Level Indicator,是服务等级指标的简称,它是衡定系统稳定性的指标。
SLO,全名Sevice Level Objective,是服务等级目标的简称,也就是我们设定的稳定性目标。
简单一句话:SLI 就是我们要监控的指标,SLO 就是这个指标对应的目标。
如何选择SLI
在系统中,常见的指标有很多种,比如:
- 系统层面:CPU使用率、内存使用率、磁盘使用率等
- 应用服务器层面:端口存活状态、JVM的状态等
- 应用运行层面:状态码、时延、QPS、TPS以及连接数等
- PASS层面:mysql、redis、kafka、mq和分布式文件储存等组件的QPS、TPS、时延等。
这么多指标,应该如何选择呢?只要遵从两个原则就可以:
- 选择能够标识一个主体是否稳定的指标,如果不是这个主体本身的指标,或者不能标识主体稳定性的,就要排除在外。
- 优先选择与用户体验强相关或用户可以明显感知的指标。
我们可以直接套用 Google 的方法:VALET。VALET 是 5 个单词的首字母,分别是 Volume、Availability、Latency、Error 和 Ticket。这 5 个单词就是我们选择 SLI 指标的 5 个维度。
Volume 容量(流量)
就是常说的QPS,TPS等。下图是性能测试的拐点模型。
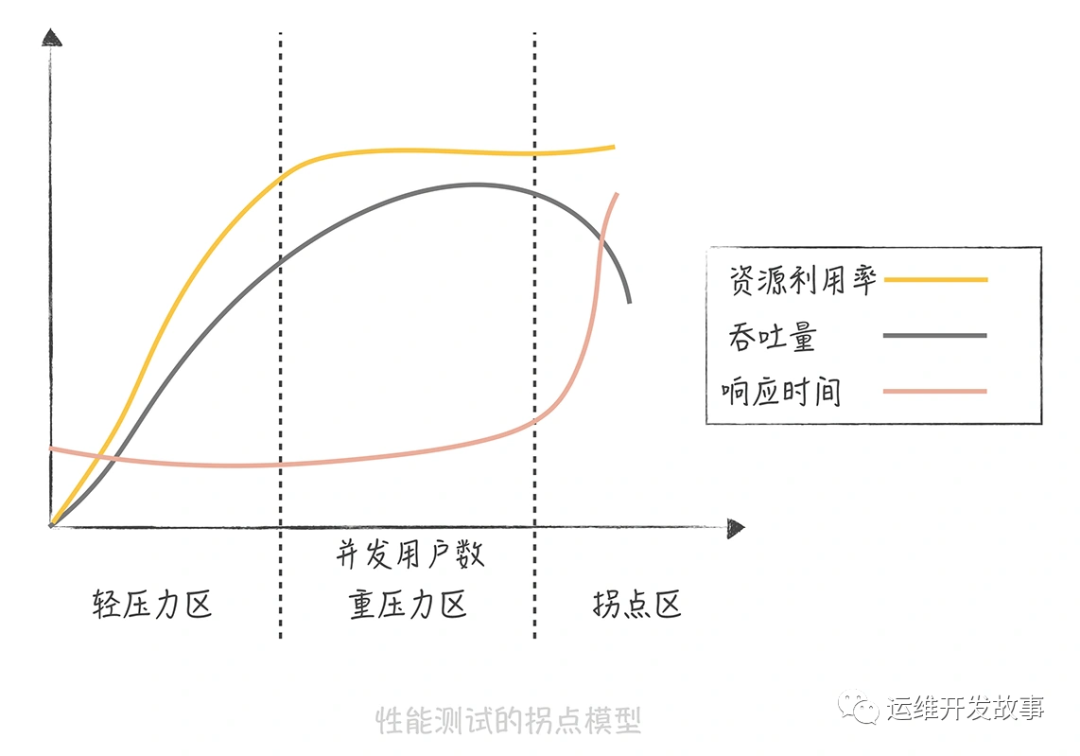
从图中你可以发现,并发用户数处于轻压力区时,响应时间平稳,吞吐量和并发用户数线性相关。而当并发用户数处于重压力区时,系统资源利用率到达极限,吞吐量开始有下降的趋势,响应时间也会略有上升。这个时候,再对系统增加压力,系统就进入拐点区,处于超负荷状态,吞吐量下降,响应时间大幅度上升。 所以我们在评估系统性能时通常需要做压力测试,目的就是找到系统的“拐点”,从而知道系统的承载能力,也便于找到系统的瓶颈,持续优化系统性能。
Availability 可用性
可用性是一个抽象的概念,你需要知道要如何来度量它,与之相关的概念是:MTBF 和 MTTR。
- MTBF(Mean Time Between Failure)是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
- MTTR(Mean Time To Repair)表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
- 可用性与 MTBF 和 MTTR 的值息息相关,我们可以用下面的公式表示它们之间的关系:
Availability = MTBF / (MTBF + MTTR)
- 1.
Latency 延迟
是说响应是否足够快,这是一个会直接影响用户访问体验的指标。但是这个还对系统资源有影响。这里区分成功请求和失败请求很重要。
- 复杂的高并发系统通常会有很多的系统模块组成,同时也会依赖很多的组件和服务,比如说缓存组件,队列服务等等。它们之间的调用最怕的就是延迟而非失败,因为HTTP 500错误通常是瞬时的,可以通过重试的方式解决。
- 调用某一个模块或者服务发生比较大的延迟,调用方就会阻塞在这次调用上,它已经占用的资源得不到释放。当存在大量这种阻塞请求时,调用方就会因为用尽资源而挂掉。如果把HTTP 500回复的延迟也计算在内,可能会产生误导性的结果。因此,监控错误恢复的延迟是很重要的。
Error 错误
错误率有多少?这里除了 5xx 之外,我们还可以把 4xx 列进来,因为前面我们的服务可用性不错,但是从业务和体验角度,4xx 太多,用户也是不能接受的。有时候还有隐式的失败。比如http 200恢复中包含了错误内容,或者策略导致的失败。比如我们要求超过一秒的请求就返回失败,这样超过一秒的请求都是失败请求。当协议内部的错误码不能表达全部的失败情况时,可以利用其它信息,如内部协议,来跟踪一部分特定故障情况。
Ticket 故障单
是否需要人工介入?如果一项工作或任务需要人工介入,那说明一定是低效或有问题的。举一个我们常见的场景,数据任务跑失败了,但是无法自动恢复,这时就要人工介入恢复;或者超时了,也需要人工介入,来中断任务、重启拉起来跑等等。
Tickets 的 SLO 可以想象成它的中文含义:门票。一个周期内,门票数量是固定的,比如每月 20 张,每次人工介入,就消耗一张,如果消耗完了,还需要人工介入,那就是不达标了。好,VALET 我们就讲完了,怎么选 SLI 指标,你是不是一下子就清楚了。可以说,这是一个我们可以直接复用的工具。
SLO 方式计算
我们可以将多个SLO的百分数相乘,得到最后的SLO值。
- SLO1:99.95% 状态码成功率
- SLO2:90% Latency <= 80ms
- SLO3:99% Latency <= 200ms
- 直接用公式表示:
Availability = SLO1 & SLO2 & SLO3
- 1.
2.案例:
本案例源自《SRE工作手册》英文版第三章,讲述的是家得宝(THD)公司在SRE转型中如何使用VALET来定义SLO:家得宝又创建一个 VALET 应用程序,以存储和报告 SLO 数据。由于 SLO 可以最好地用作趋势工具,因此该服务每天、每周和每月对 SLO 进行跟踪。请注意,我 SLO 是一种趋势分析工具,可用于错误预算,但未直接连接到监控系统。相反,家得宝仍旧有各种不同的监控平台,每个监控平台都有自己的报警。这些监控系统每天汇总其 SLO ,并发布到 VALET 服务以进行趋势分析。这种设置的缺点是,监控系统中设置的警报阈值未与 SLO 集成在一起。但是,可以根据需要灵活地更改监控系统。TPS 报告是第一个与 VALET 服务集成的系统,到目前为止,家得宝的 VALET 与其各种本地应用程序平台(在 VALET 中注册的服务的一半以上)集成。
VALET 仪表板
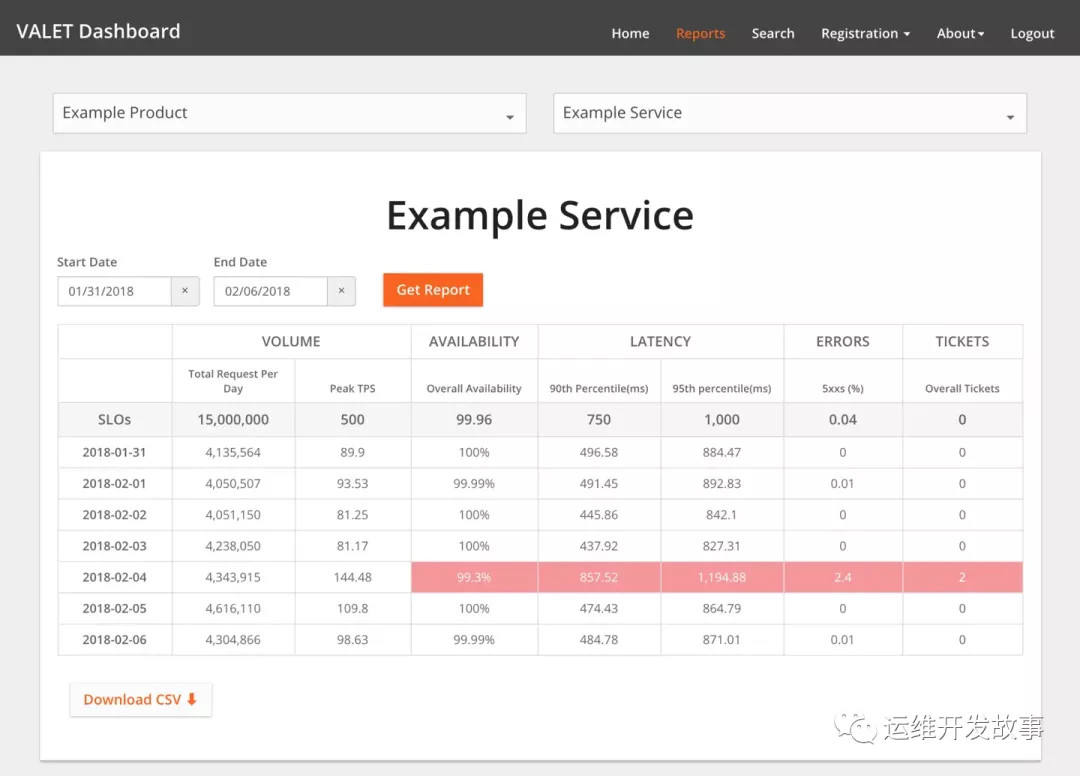
VALET 仪表板如上图所示,用于可视化和报告此数据,并且相对简单。它允许用户:
- 注册新服务。这通常意味着将服务分配给一个或多个URL,这些URL可能已经收集了VALET数据。
- 为五个 VALET 类别中的任何一个设定 SLO 目标。
- 在每个 VALET 类别下添加新的指标类型。例如,一项服务可以跟踪 P99 的延迟,而另一项服务可以跟踪 P90 (或两者)的延迟。后端处理系统可以跟踪每天的交易量(一天创建的购买订单),而客户服务前端可以跟踪每秒的高峰交易。
VALET 仪表板使用户可以立即报告许多服务的 SLO ,并以多种方式对数据进行切片和切块。例如,一个团队可以查看过去一周不满足 SLO 的所有服务的统计信息。寻求查看服务性能的团队可以查看所有服务及其所依赖服务的延迟。VALET 仪表板将数据存储在简单的Cloud SQL数据库中,开发人员使用流行的 BI 工具来构建报告。这些报告成为开发人员采取新的最佳实践的基础:定期对其服务进行 SLO 审核(通常是每周或每月)。基于这些审查,开发人员可以创建操作项以将服务返回到其 SLO ,或者可以决定需要调整不切实际的 SLO。
将VALET应用于批处理应用
当围绕 SLO 开发可靠的报告时,家得宝还发现,只要对 VALET 稍作调整,就可以用在批处理应用程序上,如下所示:
- 容量:处理的记录量
- 可用性:在一定时间内完成工作的频率(以百分比为单位)
- 延迟:作业运行所需的时间
- 错误:无法处理的记录
- 故障单:操作员必须手动修复数据并重新处理作业的次数
3.总结:
根据上面的 SLI 和 SLO 设定标准示例,内容很直观,需要你认真研上面的内容。请你尝试按照上面的格式,制定一个自己所负责系统的 SLO。
本文转载自微信公众号「运维开发故事」,可以通过以下二维码关注。转载本文请联系运维开发故事公众号。