1.数组再分组
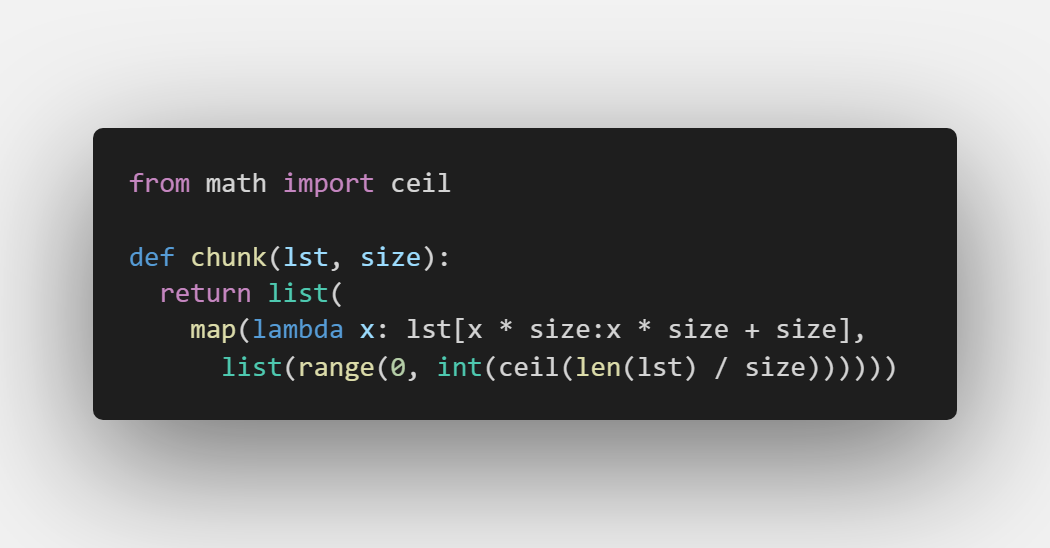
对一个列表根据所需要的大小进行细分:
效果如下:
- EXAMPLES
- chunk([1,2,3,4,5],2)# [[1,2],[3,4],5]
return中,map的第二个参数是一个列表,map会将列表中的每一个元素用于调用第一个参数的 function 函数,返回包含每次 function 函数返回值的新列表。
2.数字转数组
同样是一则关于map的应用,将整形数字拆分到数组中:
- def digitize(n):
- return list(map(int, str(n)))
效果如下:
- EXAMPLES
- digitize(123)# [1, 2, 3]
它将整形数字n转化为字符串后,还自动对该字符串进行了序列化分割,最后将元素应用到map的第一个参数中,转化为整形后返回。
3.非递归斐波那契
还记得菲波那切数列吗,前两个数的和为第三个数的值,如0、1、1、2、3、5、8、13....
如果使用递归来实现这个算法,效率非常低下,我们使用非递归的方式实现:

效果如下:
- EXAMPLES
- fibonacci(7)# [0, 1, 1, 2, 3, 5, 8, 13]
这样看是很简单,但是思维要绕得过来哦。
4.下划线化字符串
批量统一变量名称或者字符串格式。
效果如下:
- EXAMPLES
- snake('camelCase')# 'camel_case'
- snake('some text')# 'some_text'
- snake('some-mixed_string With spaces_underscores-and-hyphens')# 'some_mixed_string_with_spaces_underscores_and_hyphens'
- snake('AllThe-small Things')# "all_the_small_things"
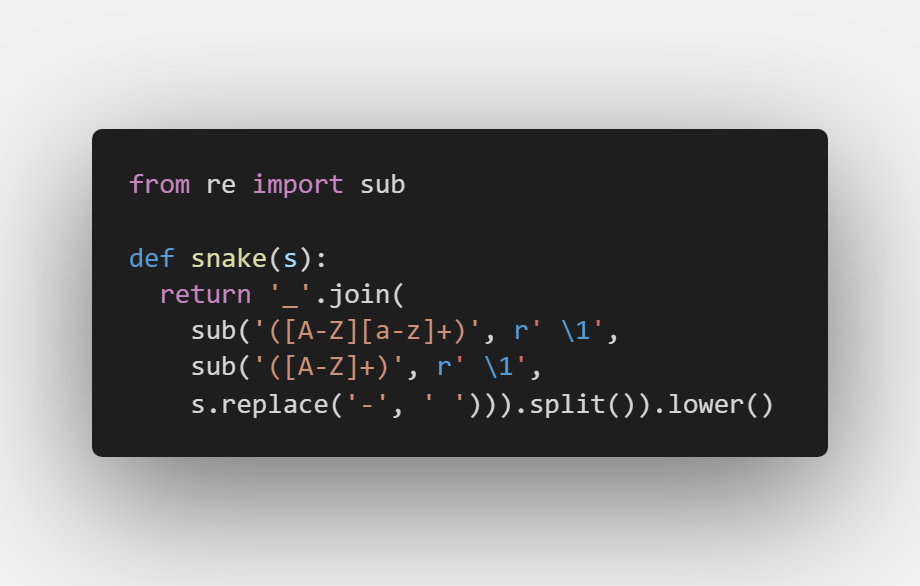
re.sub用于替换字符串中的匹配项。这里其实是一个“套娃”用法,一开始可能不太好理解,需要慢慢理解。
第一个替换,是将s字符串中,使用' '替换'-'。
第二个替换,是针对第一个替换后的字符串,对符合'([A-Z]+)'正则表达式的字符区段(全大写的单词)用r' \1'替换,也就是用空格区分开每一个单词。
第三个替换,是对第二个替换后的字符串,对符合'([A-Z][a-z]+)'正则表达式的字符区段(也就是首字母大写,其他字母小写的词语)用r' \1'替换,也是将单词用空格分隔开。