本文转载自微信公众号「数仓宝贝库」,作者叶桦 等 。转载本文请联系数仓宝贝库公众号。
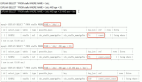
案例:一条很简单的SQL语句明明选择了索引扫描,但效率还是很低,SQL语句比较简单,是对单张表进行查询,示例代码如下:
- SQL> set autot trace
- SQL> SELECT REQUISITION_ID PARAM1, '1' PARAM2, /*电子标签*/ '1' PARAM3
- 2 FROM dbo.LIS_REQUISITION_INFO
- 3 WHERE PRINT_TIME >=
- 4 TO_DATE('2019-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
- 5 AND PRINT_TIME < SYSDATE
- 6 and length(requisition_id) = 12
- 7 AND (TAT1_STATE = '' OR TAT1_STATE IS NULL)
- 8 AND ROWNUM < 800;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1151136383
- ------------------------------------------------------------------------------------------
- | Id | Operation |Name |Rows | Bytes | Cost (%CPU)| Time |
- ------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 799 | 18377 | 160K (1)| 00:32:03 |
- |* 1 | COUNT STOPKEY | | | | | |
- |* 2 | FILTER | | | | | |
- |* 3 | TABLE ACCESS BY
- INDEX ROWID |LIS_REQUISITION_INFO| 800 | 18400 | 160K (1)| 00:32:03 |
- |* 4 | INDEX RANGE SCAN |I_PRINT_TIME | | | 3799 (1)| 00:00:46 |
- ------------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter(ROWNUM<800)
- 2 - filter(SYSDATE@!>TO_DATE(' 2019-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
- 3 - filter("TAT1_STATE" IS NULL AND LENGTH("REQUISITION_ID")=12)
- 4 - access("PRINT_TIME">=TO_DATE(' 2019-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
- "PRINT_TIME"<SYSDATE@!)
- Statistics
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 1204017 consistent gets
- 161836 physical reads
- 19984 redo size
- 761 bytes sent via SQL*Net to client
- 520 bytes received via SQL*Net from client
- 2 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 3 rows processed
从上述代码的执行计划可以看出,Id=4的dbo.LIS_REQUISITION_INFO表选择的索引是I_PRINT_TIME,PRINT_TIME为时间字段,逻辑读高达1204017,下面我们看下该列的选择性,命令如下:
- SQL> select /*+ NO_MERGE LEADING(a b) */
- b.owner,
- b.table_name,
- a.column_name,
- b.num_rows,
- a.num_distinct Cardinality,
- ROUND(A.num_distinct * 100 / B.num_rows, 1) selectivity
- from dba_tab_col_statistics a, dba_tables b
- where a.owner = b.owner
- and a.table_name = b.table_name
- and a.owner = 'DBO'
- and a.table_name = 'LIS_REQUISITION_INFO'
- and a.column_name = 'PRINT_TIME';
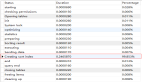
- OWNER TABLE_NAME COLUMN_NAME NUM_ROWS CARDINALITY SELECTIVITY
- ------- --------------------- ----------- -------- ----------- -----------
- DBO LIS_REQUISITION_INFO PRINT_TIME 6933600 2226944 32.1
LIS_REQUISITION_INFO的数据量为6 933 600条,PRINT_TIME列的不同值为2 226 944个,选择性高达32.1%,PRINT_TIME给定了条件时间范围,目前从执行计划来看,
LIS_REQUISITION_INFO表的访问先通过I_PRINT_TIME索引进行范围扫描,符合条件的记录回表之后再过滤,产生了大量的单块读。虽然PRINT_TIME的选择性很高,且符合索引扫描的要求,但因为其给定的条件范围太大,导致该字段并不是一个很好的索引选择。
除了PRINT_TIME,该SQL还有requisition_id、TAT1_STATE和ROWNUM,下面就来看下它们的选择性,命令如下:
- SQL> select /*+ NO_MERGE LEADING(a b) */
- b.owner,
- b.table_name,
- a.column_name,
- b.num_rows,
- a.num_distinct Cardinality,
- ROUND(A.num_distinct * 100 / B.num_rows, 1) selectivity
- from dba_tab_col_statistics a, dba_tables b
- where a.owner = b.owner
- and a.table_name = b.table_name
- and a.owner = 'DBO'
- and a.table_name = 'LIS_REQUISITION_INFO'
- and a.column_name in ('PRINT_TIME', 'REQUISITION_ID', 'TAT1_STATE');
- OWNER TABLE_NAME COLUMN_NAME NUM_ROWS CARDINALITY SELECTIVITY
- ------- --------------------- -------------------------- ----------- -----------
- DBO LIS_REQUISITION_INFO TAT1_STATE 6933600 2 0
- DBO LIS_REQUISITION_INFO REQUISITION_ID 6933600 6933600 100
- DBO LIS_REQUISITION_INFO PRINT_TIME 6933600 2226944 32.1
- SQL> select count(*),
- from dbo.LIS_REQUISITION_INFO
- where length(requisition_id) = 12
- COUNT(*)
- -------
- 6968919
- SQL> select TAT1_STATE, count(*)
- from dbo.LIS_REQUISITION_INFO
- group by TAT1_STATE;
- TAT1_STAT COUNT(*)
- ---------- --------
- 1242217
- 1 5355366
- 2 371401
REQUISITION_ID为主键的选择性很高,但几乎所有的记录值都符合length (requisition_id) = 12,TAT1_STATE的数据分布存在倾斜,条件中的TAT1_STATE = '' OR TAT1_STATE IS NULL属于第一种情况,占总数据量的1/3。该字段为固定取值(TAT1_STATE = '' OR TAT1_STATE IS NULL)。如果 PRINT_TIME和TAT1_STATE组合创建联合索引,那么效果又将如何呢?命令如下:
- SQL> create index dbo.idx_LIS_REQUISITION_INFO_com1 on dbo.LIS_REQUISITION_INFO
- (PRINT_TIME,TAT1_STATE) online;
- SQL> SELECT /*+ index(LIS_REQUISITION_INFO dbo.idx_LIS_REQUISITION_INFO_com1) */
- REQUISITION_ID PARAM1, '1' PARAM2, /*电子标签*/ '1' PARAM3
- FROM dbo.LIS_REQUISITION_INFO
- WHERE PRINT_TIME >=
- TO_DATE('2019-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
- AND PRINT_TIME < SYSDATE
- and length(requisition_id) = 12
- AND (TAT1_STATE = '' OR TAT1_STATE IS NULL)
- AND ROWNUM < 800;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1406522876
- -----------------------------------------------------------------------------------------------------
- | Id | Operation | Name |Starts|E-Rows|A-Rows| A-Time |Buffers|
- -----------------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | | 6 |00:00:00.27| 8146 |
- |* 1 | COUNT STOPKEY | | 1 | | 6 |00:00:00.27| 8146 |
- |* 2 | FILTER | | 1 | | 6 |00:00:00.27| 8146 |
- |* 3 | TABLE ACCESS BY
- INDEX ROWID |LIS_REQUISITION_INFO | 1 | 144 | 6 |00:00:00.27| 8146 |
- |* 4 | INDEX RANGE SCAN |IDX_LIS_REQUISITION_INFO_COM1| 1 |14398 | 8 |00:00:00.27| 8140 |
- -----------------------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter(ROWNUM<800)
- 2 - filter(SYSDATE@!>TO_DATE(' 2019-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
- 3 - filter(LENGTH("REQUISITION_ID")=12)
- 4 - access("PRINT_TIME">=TO_DATE(' 2019-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "TAT1_STATE"
- IS NULL AND "PRINT_TIME"<SYSDATE@!)
- filter("TAT1_STATE" IS NULL)
- Statistics
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 8008 consistent gets
- 8014 physical reads
- 0 redo size
- 471 bytes sent via SQL*Net to client
- 508 bytes received via SQL*Net from client
- 1 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 0 rows processed
创建索引之后,SQL性能有了明显的提升,逻辑读从原来的1204017降到8008,执行时间也从原来的32分钟降至27秒。
上述案例介绍了简单的复合索引优化,很多情况下,虽然改写SQL能够更好地解决问题,但我们往往很难让开发商去做出修改,因此索引优化变得尤为重要。当表上存在多个过滤条件时,字段在表中的选择性只能作为参考而不能成为最终依据,在实际工作中,我们应该根据业务特点对多个字段进行组合分析。在很多情况下,单个字段的选择性比较低,多个字段的选择性会成倍增长。