












作为Kafka集群的负责人,消费端出现消息积压,反复发生重平衡等问题时,如何快速定位性能瓶颈显的至关重要。
本篇将详细介绍消费端端监控指标,让架构师提出的性能优化方案提供数据支撑。
Kafka的设计者早就为我们考虑好了,提供了丰富多彩的监控指标。
1、消费端指标
Kafka中的监控指标通过MBean进行存储,我们可以通过jconsole中进行查看,截图如下:
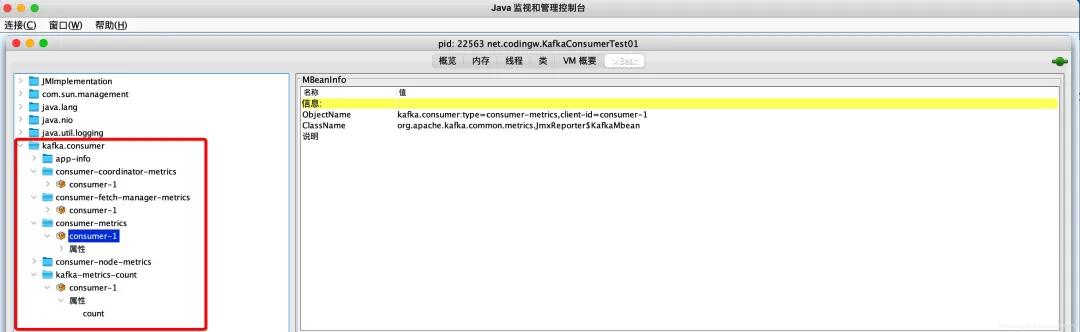
主要分为如下四个维度展开:
- Consumer-coordinator-metrics
消费者组协调器相关的监控指标。
- Consumer-fetch-manager-metrics
消费组消息拉取相关的监控指标
- Consumer-node-metrics
以broker节点为维度的统计信息,消费端向多个broker节点拉取消息等监控指标。
- Kafka-metrics-count
接下来将分别展开,详细介绍其各个指标的含义,并给出一些实践指导。
1.1 消费者组协调器监控指标
组协调器相关的监控指标明细说明如下:
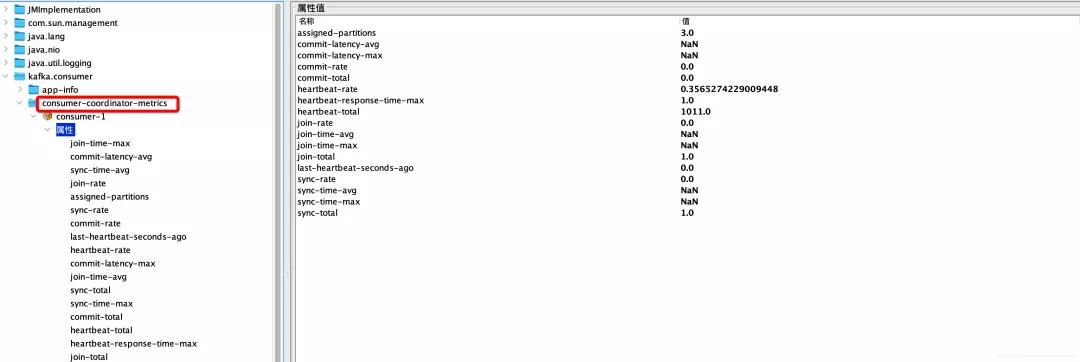
详细说明如下:
- join-time-max
消费者重新加入消费组的最大时长
- join-time-avg
消费者重新加入消费组的平均时长
- join-rate
消费者加入消费组的TPS
实践指导:该值为0正常,该值越大,越有问题,说明消费者在频繁加入消费者,在加入消费者的过程中消费者是不会消费消息的。
- join-time-avg
消费者加入消费组的平均时间
- join-total
该消费者重新加入消费组的次数(重平衡发生的次数)
实践指导:该值值的采集,如果该值过大,说明发生重平衡的次数太多,重平衡时该消费者时不参与消息消费。
- commit-latency-avg
提交位点的平均耗时
- commit-rate
提交位点的tps
- commit-latency-max
提交位点时的最大延迟时间
- commit-total
消费者启动以来的位点提交的总次数
- sync-time-avg
消费者发送sync的平均响应时长。
知识点:消费者加入小组后由该消费者中的Leader负责进行队列分配,然后将分配方案发送给组协议器,各个从节点将向组协调器获取分配队列。
- sync-rate
消费者发送sync的tps
- sync-total
消费者发送sync请求的总次数
- sync-time-max
消费者sync请求响应的最大响应时间
- assigned-partitions
当前分配到的分区数量
- heartbeat-total
心跳请求的总数
- heartbeat-response-time-max
心跳请求的最大响应时间
- last-heartbeat-seconds-ago
上一次发送心跳包的时间
- heartbeat-rate
发送心跳包的tps
从监控指标来看,我们有能得知消费端协调器的职责:
- 协调消费者加入消费组
- 协调消费者Leader进行队列负载分配
- 发送心跳,保持会话
- 提交位点
1.2 消费者消息拉取监控指标
消费者与消息拉取相关的监控指标如下图所示:
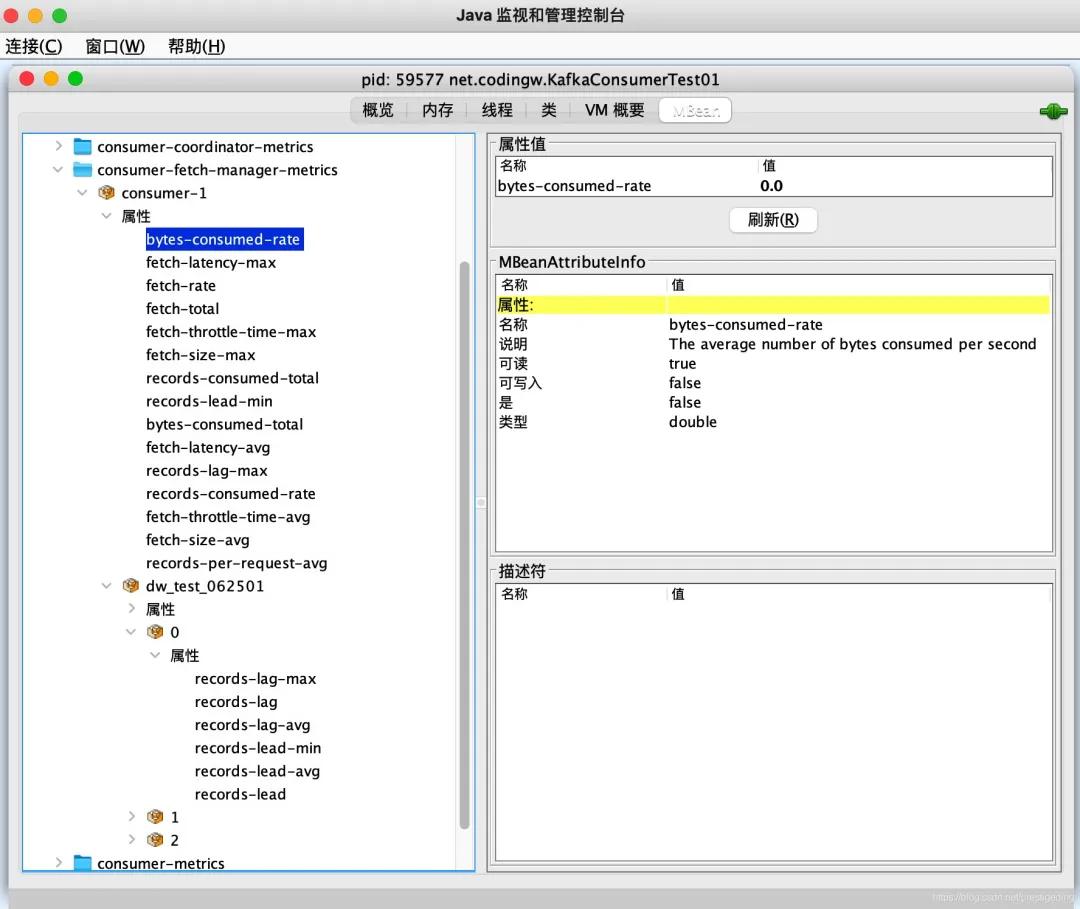
消费组拉取指标的组织分成消费组与该消费组订阅的多个topic两个维度。
接下来详细分析上述指标:
- bytes-consumed-rate
消费端每秒提交到业务的tps。
- bytes-consumed-total
消费端目前消费的总字节数。
- fetch-latency-max
API.FETCH请求(即向broker端发送消息拉取)的最大耗时。
- records-per-request-avg
每一次Fetch请求拉取的消息条数(对当前指标取平均值)。
- fetch-rate
客户端发送Fetch请求的tps。
- fetch-total
客户端总共发起的Fetch请求个数
- fetch-throttle-time-max
消息拉取(Fetch请求)由于服务端(broker)限流的最大限流时长,关于broker端限流机制,后续会重点探究。
- fetch-throttle-time-avg
消息拉取Fetch请求的平均限流时长。
- fetch-size-max
单个分区一次消息拉取最大的字节数。
实践指导:该值非常有必要采集监控,可以评估消费端消息的拉取能力,如果该值持续接近设置的期望值,如果消费端tps不满足需求,可以适当调大该值。
- fetch-latency-avg
消息拉取的平均耗时。
- fetch-size-avg
一次消息拉取的平均字节数
- records-consumed-total
消费端消费端总字节数
- records-lead-min
当前消费位点与日志端中最小位点的差值。
- records-lag-max
分配给消费者的分区中,消息积压的最大值。
实战指导:可以基于该值做告警。
消费者还会从主题-分区级别采集与消费进度相关的指标,相关指标说明如下:
- records-lag
- records-lag-avg
- records-lag-max
- records-lead
- records-lead-avg
- records-lead-min
对于上述指标,主要是解释一下两个基本的含义,其他指标是对其进行聚合计算(max,avg)。
- records-lag
消费积压,即消费位点与当前分区最大位点点差距,该值越大,说明消费端处理速度越慢,需要十分关注,通常需要接入告警,及时通知项目方。
- records-lead
消费位点与当前分区最小位点的差距,我对该值的具体用途暂未参悟,有心的读者看到,欢迎与我共同交流。
1.3 消费者网络相关监控指标
上面的指标主要是关注消费端协调器、消费端Fetch(消息拉取)两个重要维度,接下来关注一下从消息者的视角关注一下底层网络IO等维度相关的指标,相关指标的采集入口位Kafka的org.apache.kafka.common.network.Selector,其具体的指标如下图所示:
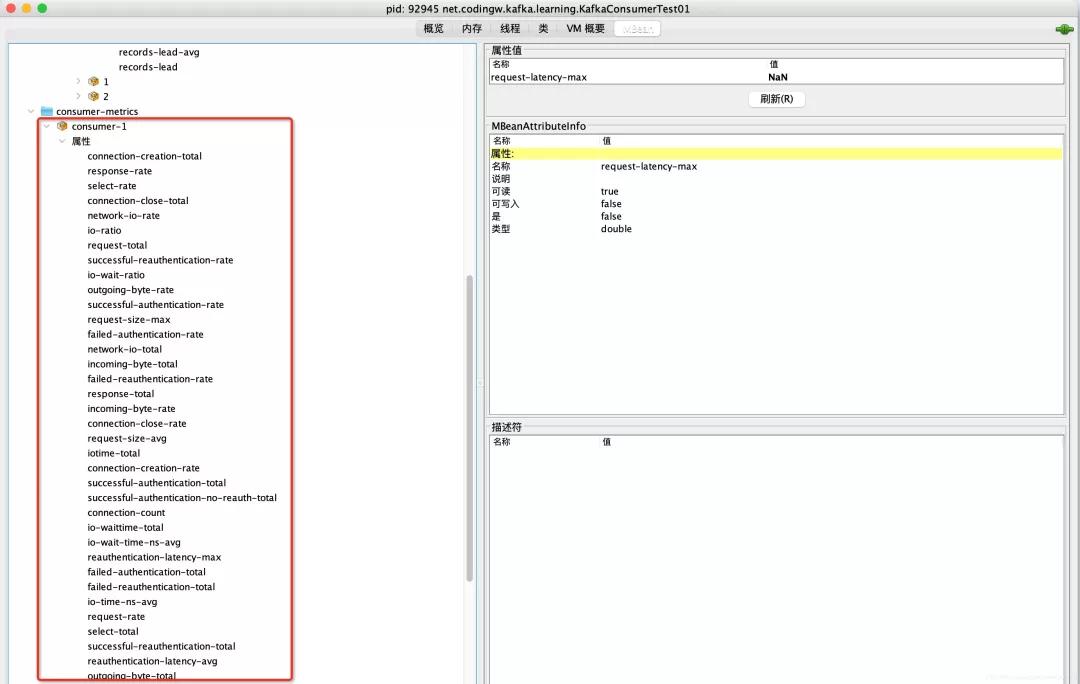
其实这些指标基本与生产者相同,说明如下:
- request-rate
请求发送tps。
- request-size-max
请求发送的最大字节
- request-size-avg
请求的平均大小
- request-total
总共的请求个数
- select-rate
事件选择器tps。
- select-total
事件选择器执行事件选择的总次数
- response-total
响应请求总数
- response-rate
响应TPS
- outgoing-byte-rate
每秒发送字节数
- outgoing-byte-total
总发送字节数
- incoming-byte-rate
每秒接受字节数
- incoming-byte-total
总工接受字节数
- io-ratio
IO线程处理IO读写的总时间
- io-time-ns-avg
每一次事件选择器调用IO操作的平均时间(单位为纳秒)
- io-waittime-total
io线程等待读写就绪的平均时间(单位为纳秒)
- iotime-total
io处理总时间。
- io-wait-ratio
io等待占io总处理时间的比例
- io-wait-time-ns-avg
io线程平均等待时间(纳秒)
实战指导:网络相关的监控指标,可以重点关注一下io线程相关的性能。
1.4 按broker节点采集监控数据
客户端还会按照broker的维度,重点采集与请求相关的指标,例如请求tps、平均响应时间。
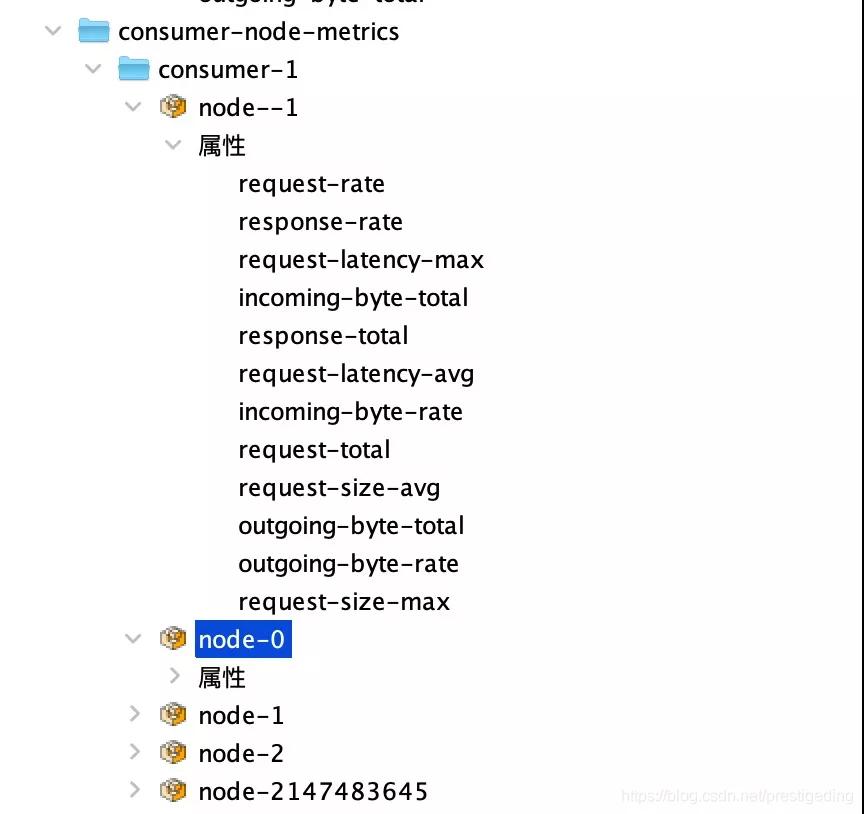
实战指导:监控指标的含义都已经在上文中提到过,这些指标应该是最值得采集,特别是request-latency-max、request-latency-avg,这对确认broker是否存在瓶颈。
2、监控指标采集
虽然Kafka内置了众多的监控指标,但这些指标默认是存储在内存中,既然是存放在内存中,为了避免监控数据无休止的增加内存触发内存溢出,通常监控数据的存储基本是基于滑动窗口,即只会存储最近一段时间内的监控数据,进行滚动覆盖。
故为了更加直观的展示这些指标,因为需要定时将这些信息进行采集,统一存储在其他数据库等持久化存储,可以根据历史数据绘制曲线,希望实现的效果如下图所示:
在这里插入图片描述
基本的监控采集系统架构设计如下图所示:
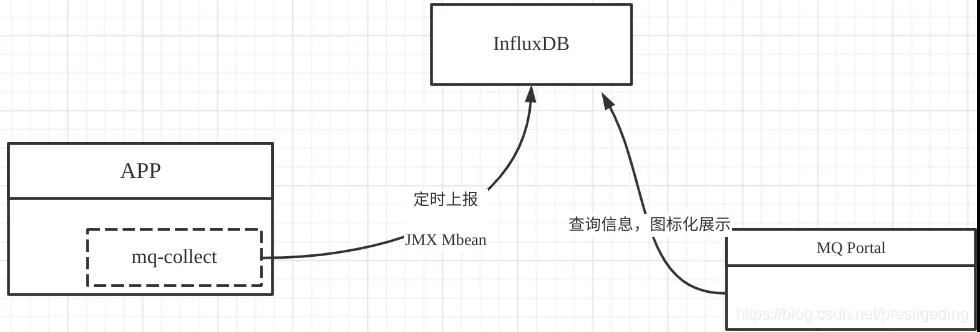
mq-collect应该是放在生产者SDK中,通过mq-collect类库异步定时将采集信息上传的到时序数据库InfluxDB,然后通过mq-portal门户展示页面,对每一个生产客户端按指标进行可视化展示,实现监控数据的可视化,从而为性能优化提供依据。
本文转载自微信公众号「中间件兴趣圈」,可以通过以下二维码关注。转载本文请联系中间件兴趣圈公众号。


















