本文转自雷锋网,如需转载请至雷锋网官网申请授权。
经过漫长的等待,ICCV 2021终于迎来放榜时刻!
ICCV官方在推特上公布了这一消息,并表示今年共有6236篇投稿,最终1617篇论文被接收,接收率为25.9%,相比于2017年(约29%),保持了和2019年相当的较低水平。
而投稿量则依旧逐年大幅增长,从2017年的2143篇,到2109年的4328篇,再到如今的6236篇,相比上一届多了50%左右。
你看邮件的时候是这表情吗?
不得不说,官方皮起来也是接地气、真扎心、没谁了哈哈~
论文ID地址:https://docs.google.com/spreadsheets/u/1/d/e/2PACX-1vRfaTmsNweuaA0Gjyu58H_Cx56pGwFhcTYII0u1pg0U7MbhlgY0R6Y-BbK3xFhAiwGZ26u3TAtN5MnS/pubhtml
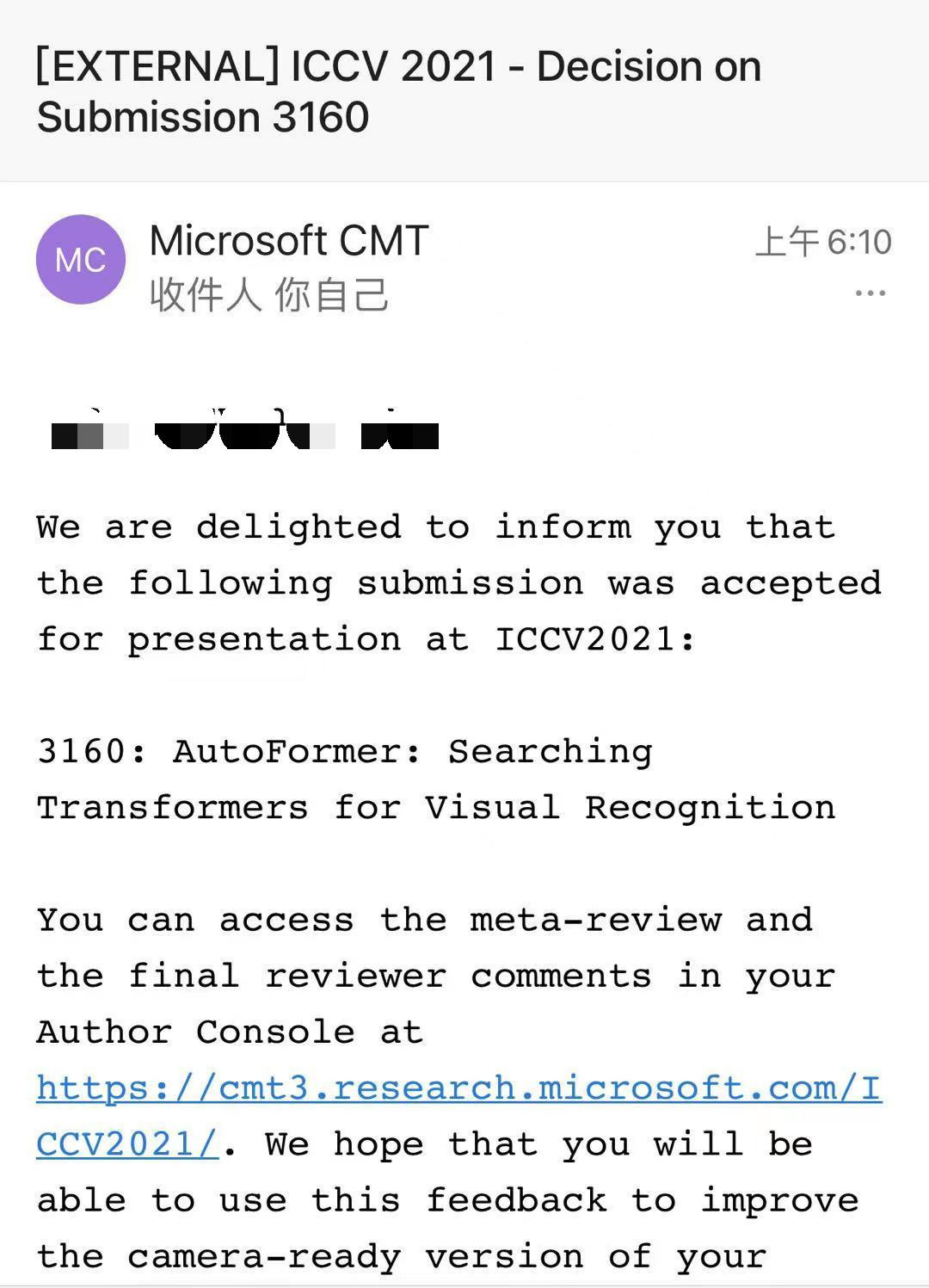
也就在今天,AI科技评论发现了一项非常厉害的研究,号称可一次性训练10万个ViT,论文也刚刚喜提ICCV accepted!
近来,Vision Transformer (ViT) 模型在诸多视觉任务中展现出了强大的表达能力和潜力。
纽约州立大学石溪分校与微软亚洲研究院的研究人员提出了一种新的网络结构搜索方法AutoFormer,用来自动探索最优的ViT模型结构。
AutoFormer能一次性训练大量的不同结构的ViT模型,并使得它们的性能达到收敛。
其搜索出来的结构对比手工设计的ViT模型有较明显的性能提升。

方法亮点:
-
同时训练大量Vision Transformers模型,使其性能接近单独训练;
-
简单有效,能够灵活应用于Vision Transformer的变种搜索;
-
性能较ViT, DeiT等模型有较明显提升。
论文地址:https://arxiv.org/abs/2107.00651
代码地址:https://github.com/microsoft/AutoML/tree/main/AutoFormer
1. 引言
最近的研究发现,ViT能够从图像中学习强大的视觉表示,并已经在多个视觉任务(分类,检测,分割等)上展现出了不俗的能力。
然而,Vision Transformer 模型的结构设计仍然比较困难。例如,如何选择最佳的网络深度、宽度和多头注意力中的头部数量?
作者的实验发现这些因素都和模型的最终性能息息相关。然而,由于搜索空间非常庞大,我们很难人为地找到它们的最佳组合。

图1: 不同搜索维度的变化会极大地影响模型的表现能力
本文的作者提出了一种专门针对Vision Transformer 结构的新的Neural Architecture Search (NAS) 方法 AutoFormer。AutoFormer大幅节省了人为设计结构的成本,并能够自动地快速搜索不同计算限制条件下ViT模型各个维度的最佳组合,这使得不同部署场景下的模型设计变得更加简单。

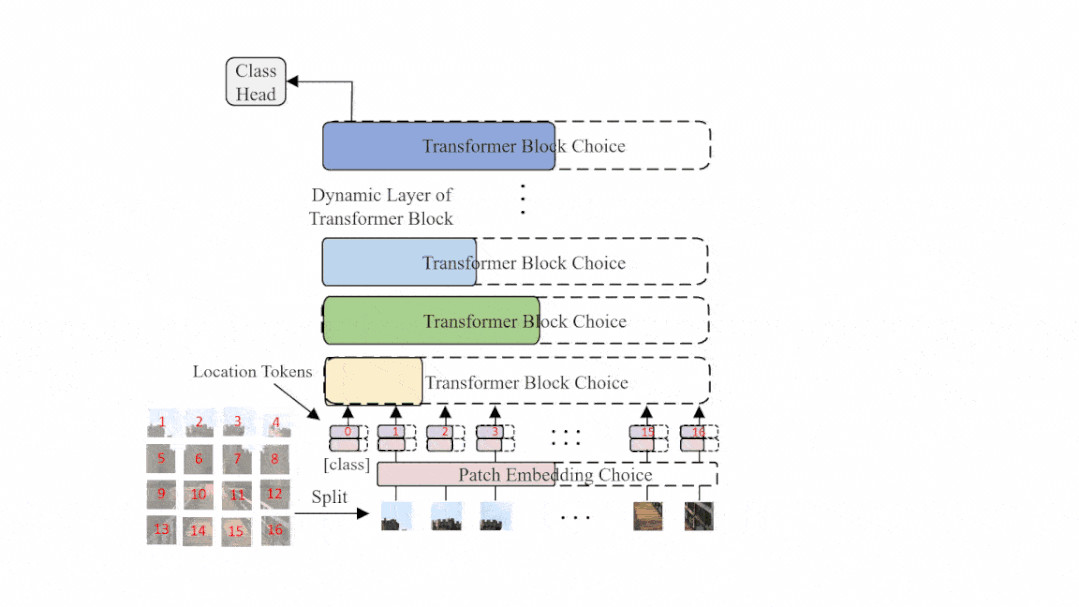
图2: AutoFormer的结构示意图,在每一个训练迭代中,超网会动态变化并更新相应的部分权重
2. 方法
常见的One-shot NAS 方法[1, 2, 3]通常采取权重共享的方式来节省计算开销,搜索空间被编码进一个权重共享的超网 (supernet) 中,并运用超网权重作为搜索空间中结构权重的一个估计。其具体搜索过程可分为两个步骤,第一步是更新超网的权重,如下公式所示。

第二步是利用训练好的超网权重来对搜索空间中结构进行搜索。
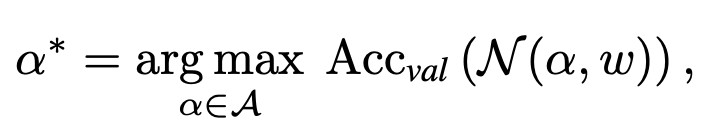
在实验的过程中,作者发现经典One-shot NAS方法的权重共享方式很难被有效地运用到Vision Transformer的结构搜索中。这是因为之前的方法通常仅仅共享结构之间的权重,而解耦同一层中不同算子的权重。
如图3所示,在Vision Transformer的搜索空间中,这种经典的策略会遇到收敛缓慢和性能较低的困难。
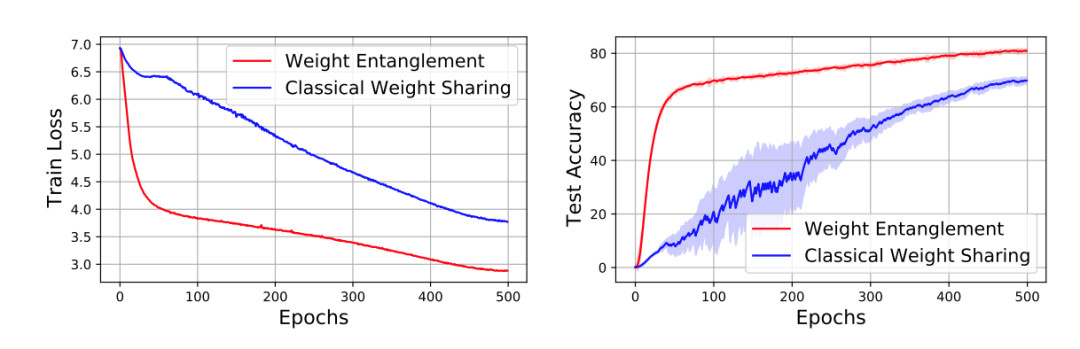
图3 权重纠缠和经典权重共享的训练以及测试对比
受到OFA [4], BigNAS [5] 以及Slimmable networks [6, 7] 等工作的启发,作者提出了一种新的权重共享方式——权重纠缠 (Weight Entanglement)。
如图4所示,权重纠缠进一步共享不同结构之间的权重,使得同一层中不同算子之间能够互相影响和更新,实验证明权重纠缠对比经典的权重共享方式,拥有占用显存少,超网收敛快和超网性能高的优势。
同时,由于权重纠缠,不同算子能够得到更加充分的训练,这使得AutoFormer能够一次性训练大量的ViT模型,且使其接近收敛。(详情见实验部分)
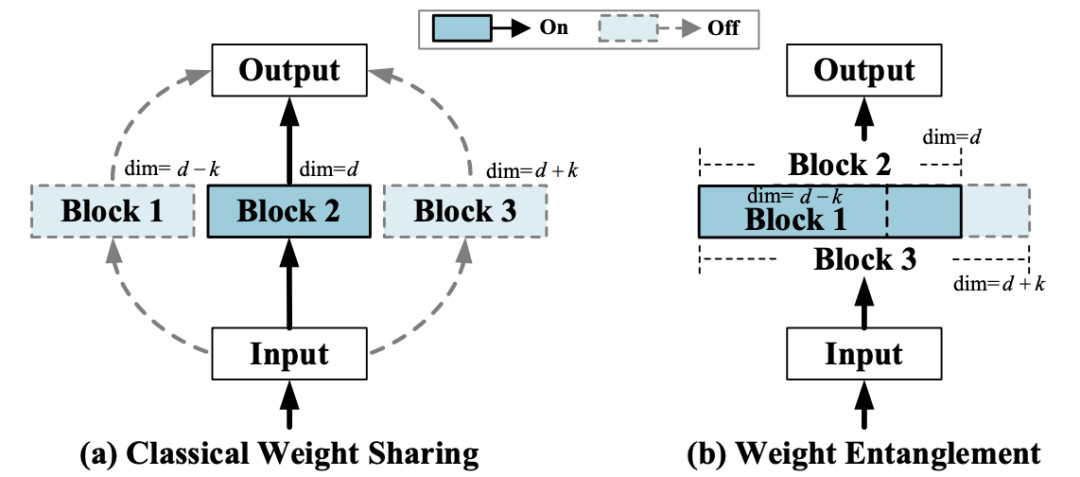
图4 权重纠缠和权重共享的对比示意图
3. 实验
作者设计了一个拥有超过1.7x10^17备选结构的巨大搜索空间,其搜索维度包括ViT模型中的五个主要的可变因素:宽度 (embedding dim)、Q-K-V 维度 (Q-K-V dimension)、头部数量 (head number)、MLP 比率 (MLP ratio) 和网络深度 (network depth),详见表1。
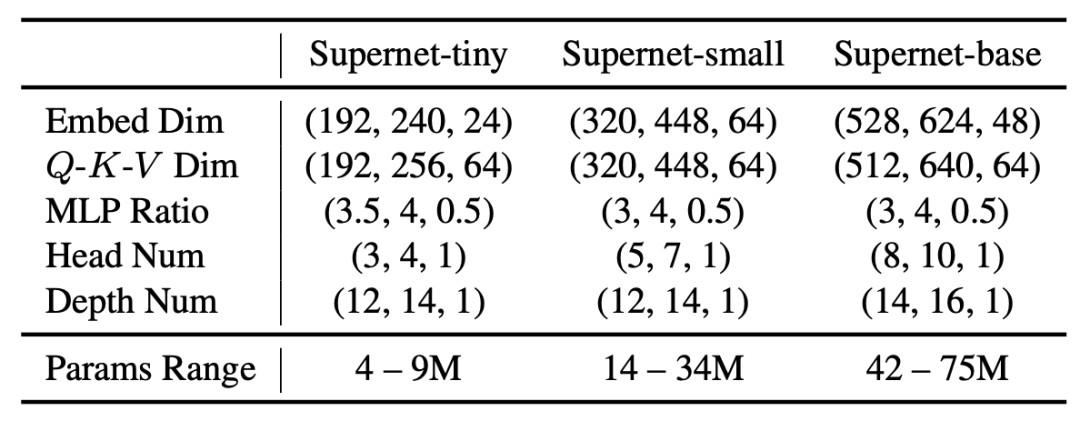
表1:AutoFormer的搜索空间
为了验证方法的有效性,作者将AutoFormer搜索得到的结构和近期提出的ViT模型以及经典的CNN模型在ImageNet上进行了比较。
对于训练过程,作者采取了DeiT [8]类似的数据增强方法,如 Mixup, Cutmix, RandAugment等, 超网的具体训练参数如表2所示。所有模型都是在 16块Tesla V100 GPU上进行训练和测试的。
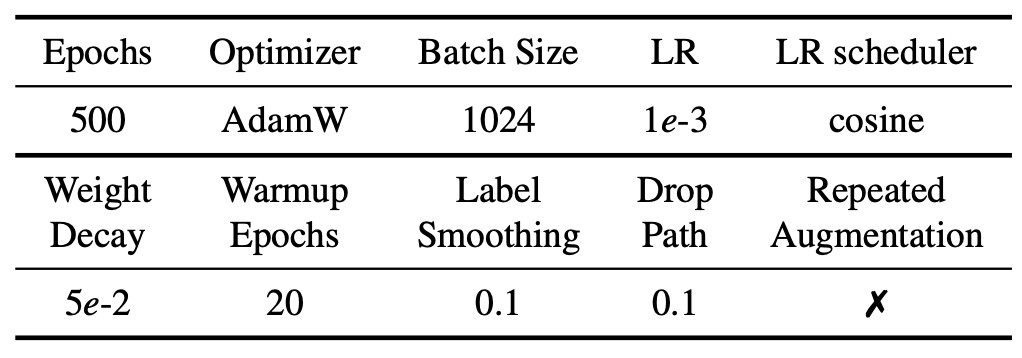
表2 超网的训练参数
如图5 和表3所示,搜索得到的结构在ImageNet数据集上明显优于已有的ViT模型。
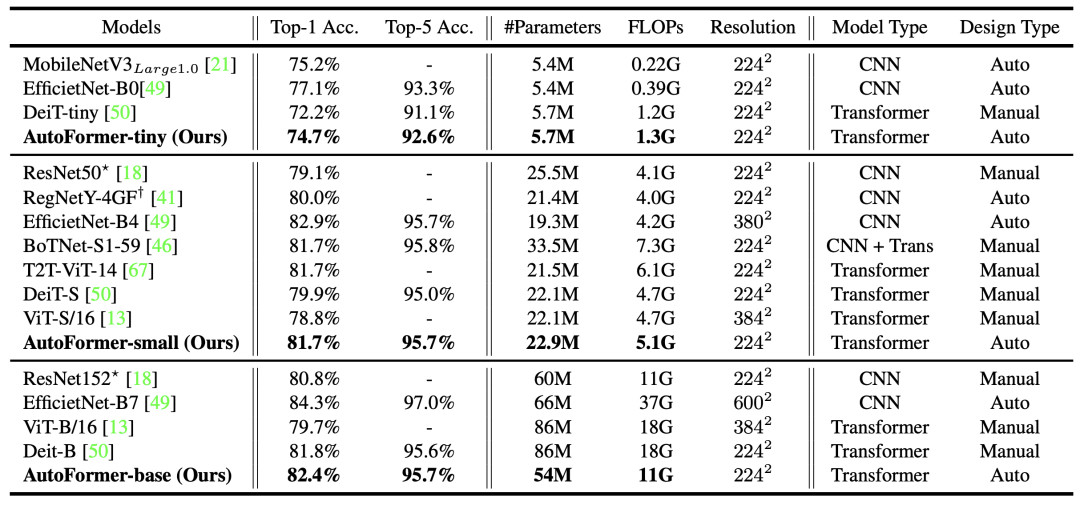
表3:各个模型在ImageNet 测试集上的结果
从表4中可以看出,在下游任务中,AutoFormer依然表现出色,利用仅仅25%的计算量就超越了已有的ViT和DeiT模型,展现了其强大的泛化性能力。

表4:下游分类任务迁移学习的结果
同时,如图5所示,利用权重纠缠,AutoFormer能够同时使得成千上万个Vision Transformers模型得到很好的训练(蓝色的点代表从搜索空间中选出的1000个较好的结构)。
不仅仅使得其在搜索后不再需要重新训练(retraining)结构,节约了搜索时间,也使得其能在各种不同的计算资源限制下快速搜索最优结构。
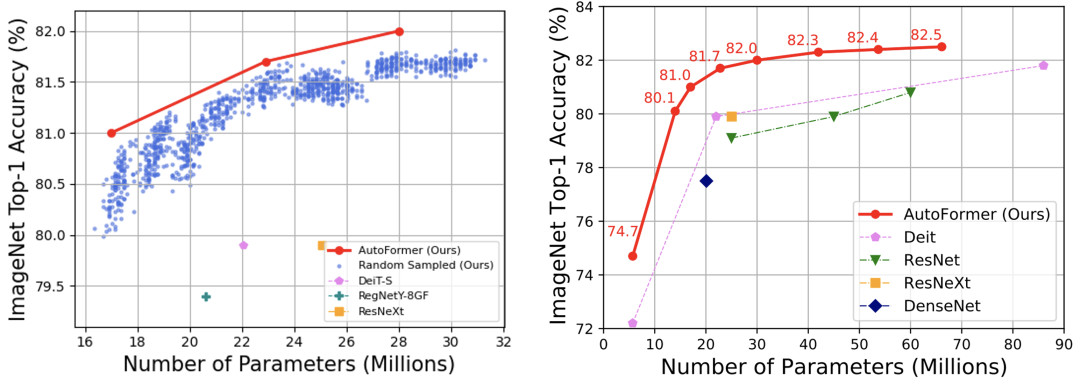
图5:左:AutoFormer能够同时训练大量结构,并使得其接近收敛。蓝色的点代表从搜索空间中选出的1000个较好的结构。右:ImageNet上各模型对比
4. 结语
本文提出了一种新的专用于Vision Transformer结构搜索的One-shot NAS方法—— AutoFormer。AutoFormer 配备了新的权重共享机制,即权重纠缠 (Weight Engtanglement)。在这种机制下,搜索空间的网络结构几乎都能被充分训练,省去了结构搜索后重新训练(Retraining)的时间。大量实验表明所提出的算法可以提高超网的排序能力并找到高性能的结构。在文章的最后,作者希望通过本文给手工ViT结构设计和NAS+Vision Transformer提供一些灵感。在未来工作,作者将尝试进一步丰富搜索空间,以及给出权重纠缠的理论分析。