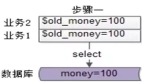
对于分布式系统的架构师来说,CAP 定理所描述的一致性和可用性是一个较大的挑战。网络远程跨机房是不可避免的,数据中心之间的高延迟总是导致数据中心之间在短时间内出现某种断开。因此,传统的分布式应用体系结构被设计成要么放弃数据一致性,要么降低可用性。
不幸的是,我们不能牺牲应用可用性。尝试保持一致性,业界接受了最终一致性模型。在这个模型中,应用依赖于数据库管理系统来合并数据的所有本地副本,以使它们最终保持一致。除非出现数据冲突,最终一致性模型看起来很好。一些最终一致性模型承诺尽最大努力解决冲突,但不能保证强一致性。
1. 什么是CRDT?
一个新趋势是,围绕CRDT构建的模型提供了强最终一致性。那么,什么是CRDT 呢?
CRDT是无冲突复制数据类型的缩写。CRDT通过预先确定的一套解决冲突规则和语义来实现了最终一致性,它引入一组特殊的基础数据类型, CRDT是一种特殊的数据类型,可以从所有数据库副本汇聚数据。常用的 CRDTs包括 G-counters (grow-only counters)、 PN-counters (positive-negative counters)、寄存器、 G-sets (grow-only sets)、2P-sets (two-phase sets)、 or- sets (observed-remove sets)等等。
在背后,CRDT依靠以下数学特性来处理数据:
- 交换律:a ☆ b = b ☆ a
- 结合律:a ☆ ( b ☆ c ) = ( a ☆ b ) ☆ c
- 等幂: a ☆ a = a
G 计数器是一个完美的例子,操作 CRDT合并的业务。这里,a + b = b + a 和 a + (b + c) = (a + b) + c。副本之间只交换更新(增加的内容)。CRDT 通过添加更新来合并更新。例如,g 集合应用幂等({ a,b,c } u { c } = { a,b,c })来合并所有元素。幂等可以避免在元素通过不同路径传递和汇聚时重复添加到数据结构中的元素。
一个典型的多主系统的副本同步方式如下:
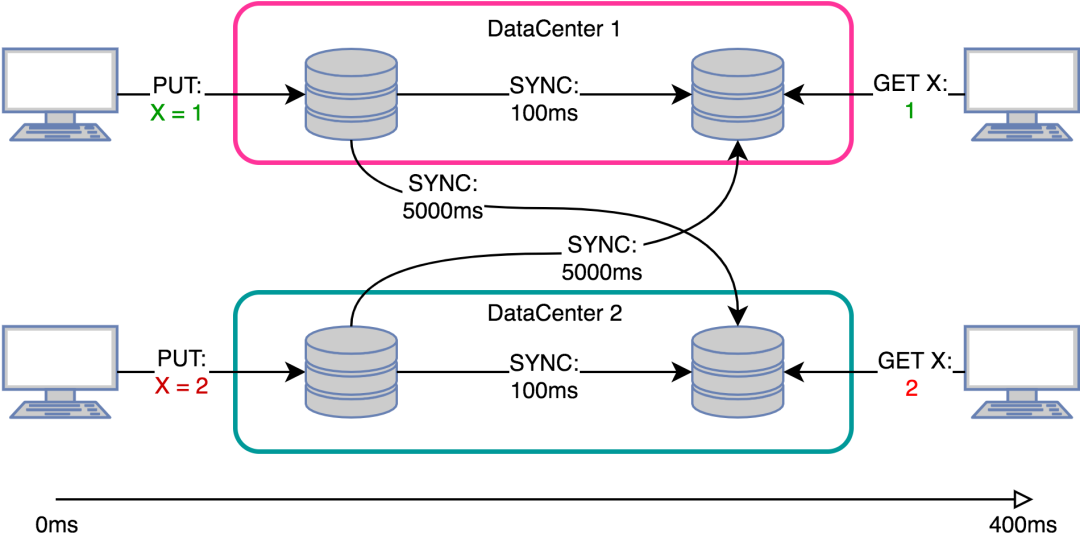
CRDT能够自己解决合并冲突,更一般的情况是处理在多leader分布式系统中的副本同步。
那么, 有哪些典型的副本同步模式呢?
2. 副本同步模式
2.1 基于状态的同步
基于状态的同步, 也称为被动同步,形式为聚合复制数据类型(Convergent Replicated Data Type,CvRDT), 用于 NFS、 AFS、 Coda 等文件系统,以及 Riak、 Dynamo 等 KV存储。
在这种情况下,副本通过发送对象的完整状态来传播更改,必须定义 merge ()函数,以将传入的更改与当前状态合并。

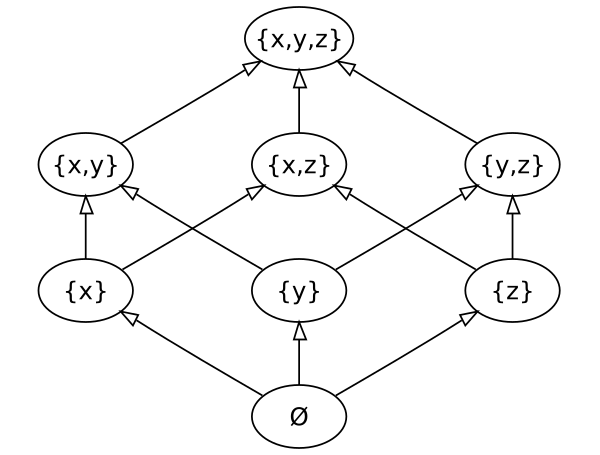
基于状态的同步必须满足以下要求,以确保复制的一致性:
- 数据类型(或复制上的状态)形成一个具有最小上界的偏序集
- Merge ()函数产生一个最小上界
- 副本构成一个连通图
例子:
数据类型: 自然数集是N,极小元到正负无穷大,则Merge (x,y) = max (x,y)
这样的要求给出了一个用于交换的幂等merge()函数,它也是给定数据类型上的一个单调递增函数。
这保证了所有的副本最终都会聚合收敛,并且让我们不用担心传输协议ーー可以丢失传播更新,也可以多次发送它们,甚至可以按任何顺序发送它们。
2.2 基于操作的同步
基于操作的同步,也称为主动同步,形式为交换复制数据类型(Commutative Replicated Data Type ,CmRDT),用于 Bayou, Rover, IceCube, Telex这样的系统。
在这种情况下,副本通过向所有副本发送操作来传播更改。当对副本进行更改时:
执行 generate ()方法,该方法返回一个要在其他副本上调用的 effector ()函数。换句话说,effector ()是一个用于修改其他副本状态的闭包。
将effector ()应用于本地状态
向所有其他副本传播effector ()
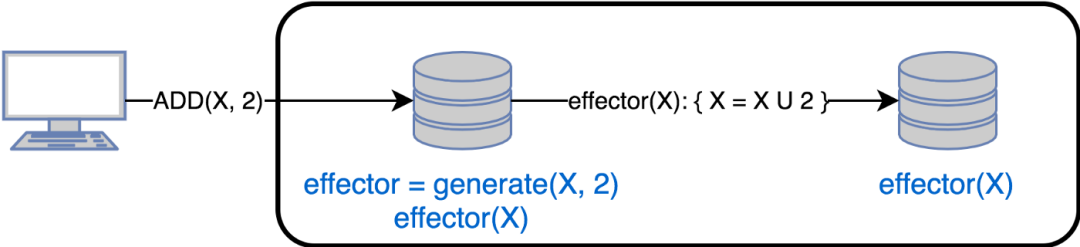
基于操作的同步必须满足以下要求,以确保复制的一致性:
- 可靠的传输协议
- 如果effector()以因果顺序交付,那么并发 effector ()就必须转换为OR
- 如果effector()在没有遵守因果顺序的情况下交付,那么所有effector()都必须转换
- 如果能够多次传递,则 effector ()必须是幂等的.
- 在现实中,一般会依赖于可靠的发布-订阅系统(例如,Kafka)作为交付的一部分。
2.3 基于增量的同步
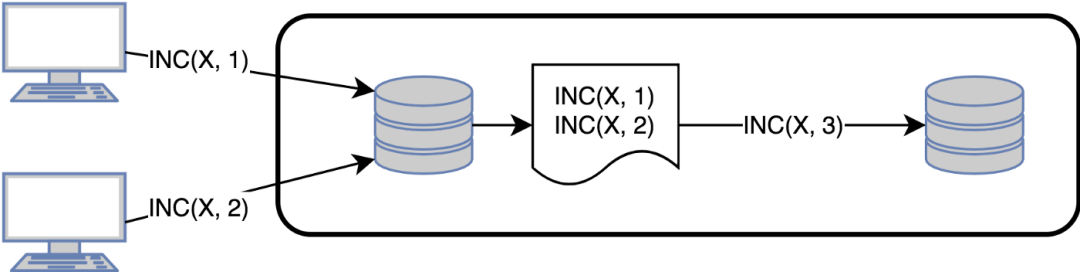
考虑到基于状态/操作的同步,如果一个更改只影响对象的一部分,那么传输整个对象的状态是没有意义的。此外,如果更新修改了相同的状态(如计数器) ,我们可以周期性地只发送一个聚合状态。
增量同步结合了状态和操作这两种方法,并传播所谓的 Delta 变异,这些变异相应地将状态更新到最后的同步日期。所以,需要发送一个完整的状态进行第一次同步,然而,一些实现实际上考虑了远程副本的状态以降低所需的数据量。
如果允许延迟,那么基于操作的日志压缩可能是下一个优化:
2.4 基于纯操作的同步
在基于操作的同步中有一个延迟,以创建一个effector()。在某些系统中,这样的延迟是不可接受的,必须立即传播更新,需要更复杂的组织协议以及更多的元数据空间。
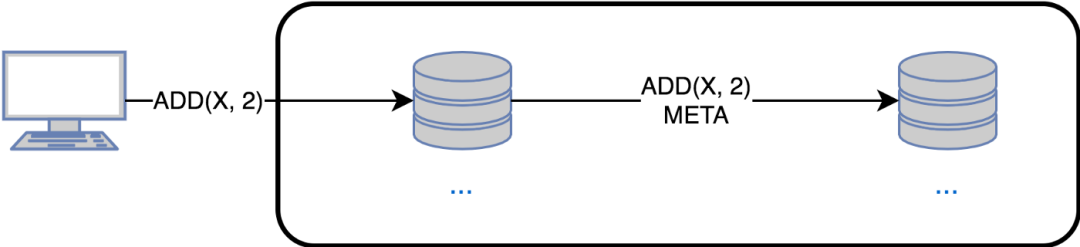
典型用法:
- 如果在系统中必须立即传播更新,基于状态的同步是一个糟糕的选择,因为它会增加整个状态的成本。然而,在这种特殊情况下,基于增量的同步是更好的选择,与基于状态更新的差别不会太大。
- 如果你需要在失败后同步副本,基于状态/基于 delta 是正确的选择。如果必须使用基于操作的同步,则必须:
- 回复所有失败后遗漏的更改
- 获取其中一个副本的完整副本并应用于所有错过的操作
3.基于操作的同步只需要将 effector ()传递给每个副本一次。通过要求effector ()具有幂等性,可以放松这一要求。实际上,前者比后者更容易实现。
基于操作和基于状态的同步之间的关系是:基于操作和基于状态的同步可以在保持 CRDT 要求的前提下相互仿真。
3. 数据一致性模型
一致性模型数据协议是分布式数据库和应用程序之间的一个协议,它定义了在写操作和读操作之间数据的清洁程度。
例如,在一个强一致性模型中,数据库保证应用程序总是读取最后一次写入的数据。使用循序一致性数据库的时候,数据库保证你读取的数据的顺序与数据写入数据库的顺序一致。在最终一致性模型中,分布式数据库承诺在幕后同步和整合数据库副本之间的数据。因此,如果将数据写入一个数据库副本并从另一个数据库副本读取数据,则可能不会读取数据的最新副本。
关于最终一致性的研究已经有了许多的研究成果。当前的趋势是从强一致性转向其他可能的一致性变化,研究什么样的数据一致性模型最适合特定的系统/场景,并需要重新考虑当前的定义。这就导致了一些矛盾,例如,当一些人考虑一个具有特殊属性的最终一致性时,同时,其他作者已经为这个特殊情况创建了一个定义。
简单地,可以从效果来重新定义最终一致性,即如果所有请求都没问题,那么它最终是一致的。
3.1 数据一致性的分类
强一致性(SC)
所有的写操作都严格按顺序执行,对任何副本的读请求都返回相同的、最后的写结果,需要实时的共识(及其所有后果) 。为了解决冲突,允许 n/2-1节点关闭。
最终一致性(EC)
在本地进行更新,然后传播更新。读取一些副本可能会返回过时的状态。回滚或以某种方式决定在发生冲突时应该做什么。也就是说,我们还需要共识,不是实时的。
强最终一致性(SEC)
EC + 复制有一个自动解决冲突的方法。因此,我们不要求达成共识,允许关闭 n-1节点。
如果放松 CAP 定理中的 SC 要求,那么 SEC 就解决了那些恼人的问题。
3.2 强一致性
两阶段提交是实现强一致性的常用技术。这里,对于本地数据库节点上的每个写操作(添加、更新、删除) ,数据库节点将更改传播到所有数据库节点,并等待所有节点确认。然后,本地节点向所有节点发送一个提交,并等待另一个确认。应用程序只能在第二次提交之后才能读取数据。当网络断开数据库之间的连接时,分布式数据库将不能进行写操作。
3.3 最终一致性的实现方法
最终一致性模型的主要优点是,即使在分布式数据库副本之间的网络连接中断的情况下,数据库也可以执行写操作。一般来说,这个模型避免了两阶段提交产生的往返时间,因此支持的每秒写操作比其他模型多得多。最终一致性必须解决的一个问题是冲突,即在不同的地方同时写同一个条目。根据如何避免或解决冲突,最终一致性可以进一步分为以下几类:
最后写入的最终一致性(Last writer wins ,LWW)
在这种策略中,分布式数据库依赖于服务器之间的时间戳同步。数据库交换每个写操作的时间戳和数据本身。如果发生冲突,使用最新时间戳的写操作获胜。
这种技术的缺点是假设所有系统时钟都是同步的。实际上,同步所有的系统时钟是困难和昂贵的。
法定人数的最终一致性(Quorum-based eventual consistency)
此技术类似于两阶段提交。然而,本地数据库并不等待所有数据库的确认; 它只是等待大多数数据库的确认。多数人的确认确定了法定人数。如果发生冲突,建立仲裁的“写”操作获胜。
另一方面,这种技术增加了写操作的网络延迟,从而降低了应用程序的可伸缩性。此外,如果本地数据库与拓扑中的其他数据库副本隔离,那么它将不能进行写操作。
合并复制(Merge replication)
在这种关系数据库中常见的传统方法中,一个集中的合并代理将所有数据合并。这种方法还提供了一些灵活性,可以实现自己解决冲突的规则。
合并复制速度太慢,无法支持实时使用的应用程序,还存在一个单点故障。由于此方法不支持冲突解决的预设规则,因此常常导致冲突解决的错误实现。
无冲突复制数据类型(Conflict-free replicated data type,CRDT)
简而言之,基于 CRDT的数据库提供无冲突的最终一致性。基于 CRDT的数据库是可用的,即使分布式数据库副本不能交换数据。它们总是将本地延迟交付给读写操作。
因此,我们希望为不稳定且经常分区的分布式系统提供一组基础数据类型。此外,希望这些数据类型为我们解决冲突,这样就不需要与用户交互或查询仲裁节点。
然而,并非所有数据库用例都受益于CRDT,而且,基于 CRDT数据库的冲突解决语义是预定义的,不能被重写。
4. CRDT 分析
4.1 CRDT 之 Counter
一个带有两个操作的整数值: inc ()和 dec (),让我们考虑一些基于操作和状态同步的实现:
4.1.1 基于操作的计数器
很明显,我们只需要传播更新。
例如,Inc () : generator (){ return function (counter){ counter + = 1}}。
4.1.2 基于状态的计数器
这是一个棘手的问题,因为我们还不清楚如何实现 merge ()函数。
增量计数器,g 计数器:
让我们使用一个具有副本数量大小的向量(又叫版本向量) ,每个副本在 inc ()操作中增加它的向量元素。Merge ()函数取相应向量项的最大值,即计数器值中所有向量元素的和。

此外,G-Set 也可以使用。
例如,社交媒体中点击/喜欢 的计数器。
加减计数器
使用两个 g 计数器,一个用于增量,另一个用于减量。
例如,P2P网络(Skype)中登录的用户数量。
非负数计数器:
不幸的是,到目前为止还没有一个现实中的应用。
4.2 CRDT之 Register
具有两个操作的存储单元:assign()和value()。问题在于assign()操作,它们不进行交换。有两种方法可以解决这个问题:
4.2.1 LWW-Register
通过在每个操作上生成惟一的 id (时间戳)来引入总顺序。
例如,基于状态的,通过元组(value,id)的更新:

现实中,cassandra 中的列和 NFS中整个文件或其中的一部分都是具体的应用场景。
4.2.2 Multi-Value Register
该方法类似于每个节点的 G-Counter+ store 的集合。Multi-Value Register的值是所有值,merge ()函数对所有向量元素应用 LWW 方法。
例如,网上商城中的购物篮。
4.3 CRDT之 Set
一个集合有两个非交换操作: add ()和 rmv () ,它是容器、映射、图等的基础类型。
考虑一个原生的集合实现,其中 add ()和 rmv ()在到达时顺序执行。首先,在第1和第2个副本上有并发的 add () ,然后 rmv ()在第1个副本上到达。
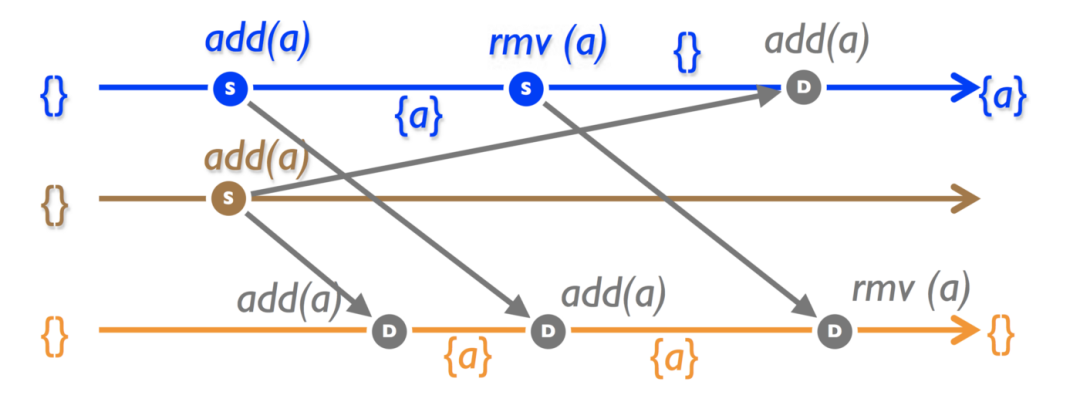
果然,在同步之后副本发生了偏移。
4.3.1 Grow-Only Set
一个非常简单的解决方案是根本不允许 rmv ()操作。Add ()操作转换,merge ()函数只是一个集合。
4.3.2 2P-Set
允许 rmv ()操作,但不能在删除元素后重新添加元素。一个附加的 g-set可以用来跟踪删除的元素(也称为墓碑集)。
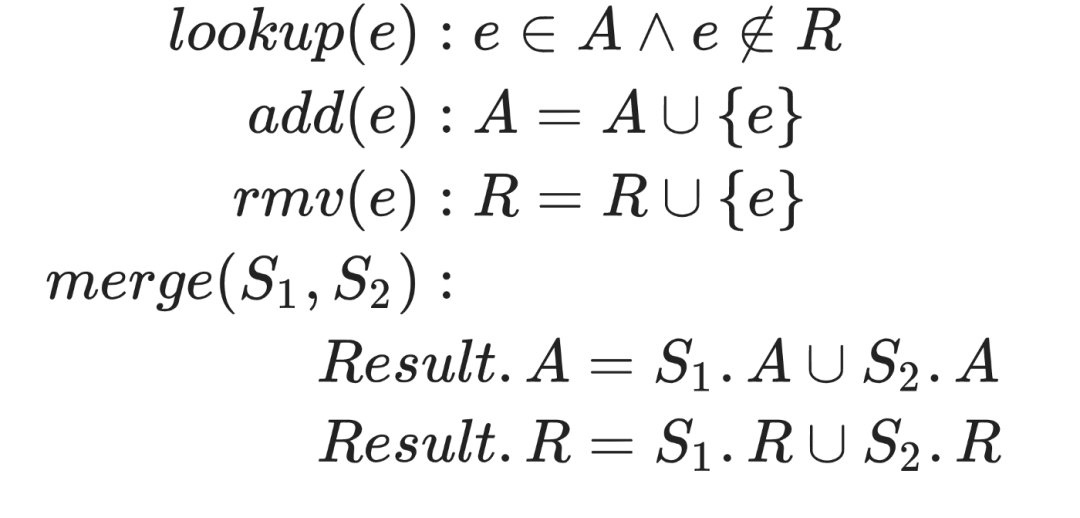
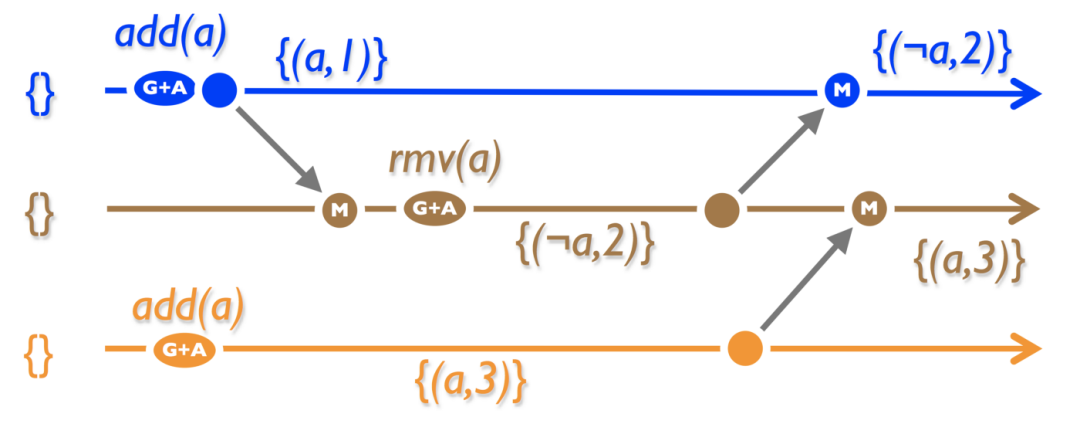
4.3.3 LWW-element Set
思路是在一个集合中引入一个总顺序。例如,生成时间戳。我们需要两个集合: 添加集和删除集。Add ()将(element,unique _ id ())添加到 add-set,rmv ()将添加到 remove-set。Lookup ()检查 id 在 add-set 或 rmv-set 中的大小。
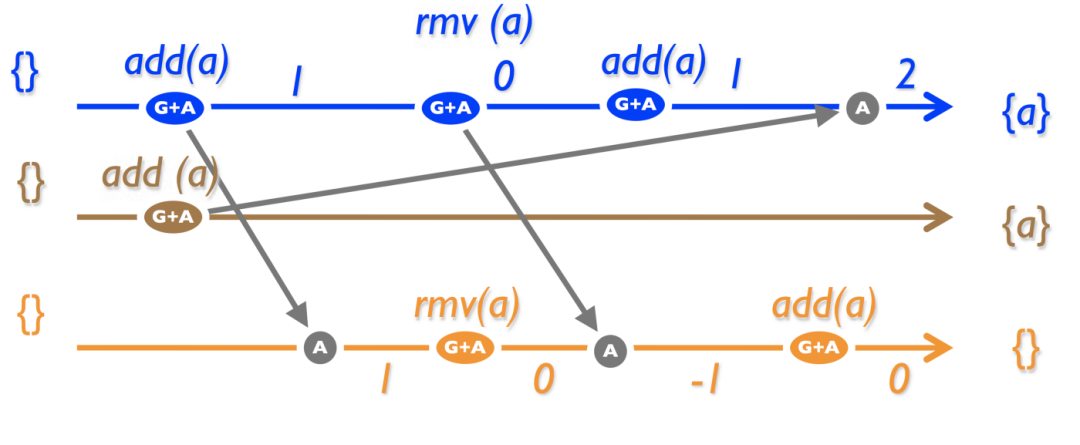
4.3.4 PN-Set
对集合进行排序的另一种方法ーー为每个元素添加一个计数器。在 add ()操作上增加它,在 rmv ()上减少它。当且仅当其计数器为正时,集合中要考虑相应的元素。
4.3.5 Observe-Remove Set, OR-Set, Add-Win Set:
在此数据类型中,add ()优先于 rmv ()。可能实现的一个例子是: 向每个新添加的元素添加唯一的标记(每个元素)。然后 rmv ()将元素的所有可见标记发送给其他副本,副本保留其他标记。
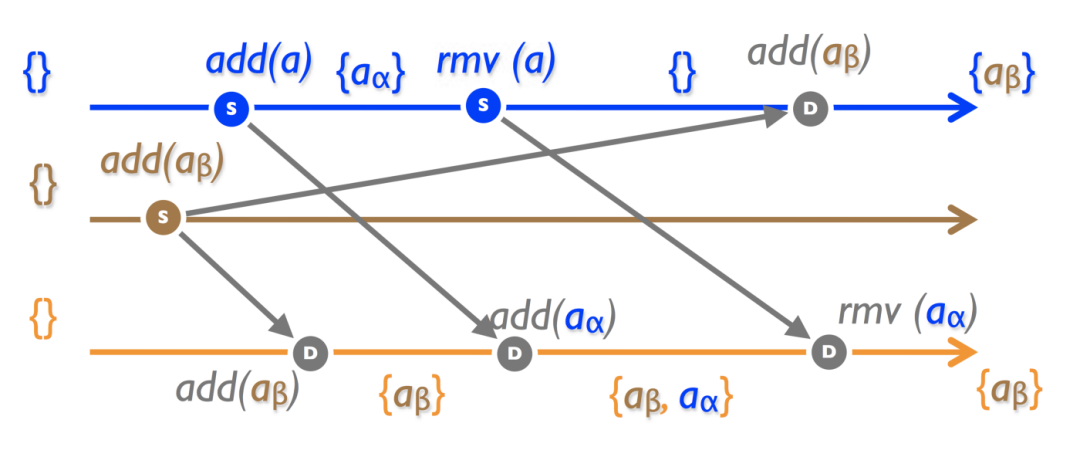
4.3.6 Remove-win Set
同上,但是 rmv ()优先于 add ().
4.4 CRDT之Graph
图类型基于集合类型。这里有以下问题: 如果有两个并发 addEdge (u,v)和 removeVertex (u)操作ー我们应该怎么做?有三种可能的策略:
- removeVertex ()具有优先级,所有关联的边都将被删除
- addEdge ()具有优先级,所有移除的顶点将被重新添加
- 延迟 removeVertex ()的执行,直到所有并发 removeVertex ()都执行为止
第一个是最容易实现的,因为可以只使用两个2p 集,得到的数据类型称为2p2p 图.
4.5 CRDT之 Map
对于map,有两个问题需要解决:
- 如何处理并发 put ()操作? 可以类比计数器,使用 LWW 或 MV 语义吗?
- 如何处理并发的 put ()/rmv ()操作?我们可以通过类比设置和使用 put-wins 或 rmv-wins 或 last-put-wins 语义么?
Map允许嵌套其他 CRDT 类型。需要注意的是,Map不处理其值的并发更改,必须由嵌套的 CRDT 本身来处理。
4.5.1 Remove-as-recursive-reset map
在此数据类型中,rmv (k)操作“重置”给定 k 下 CRDT 对象的值,例如,对于值为零的计数器。
例如,一个共享的购物车。一个用户添加更多的面粉,另一个同时做一个检查(这导致删除所有元素)。同步之后,有一个“单元”的面粉,这似乎是合理的。
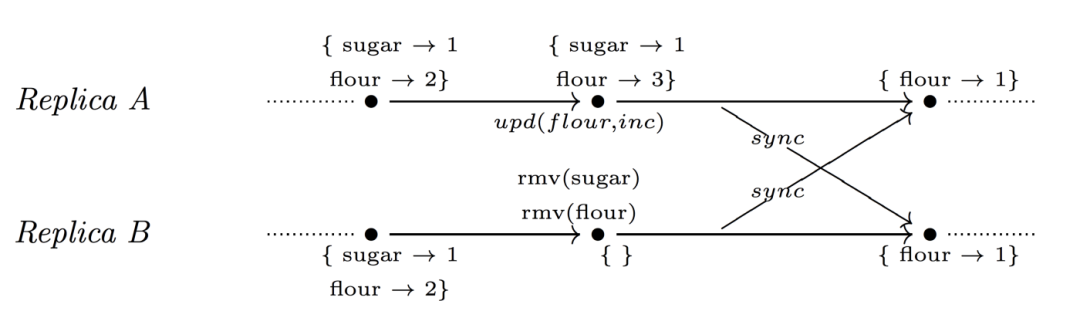
4.5.2 Remove-wins map
在这种情况下,rmv ()优先于 add ()。
例如,玩家张三在一个网络游戏中有10个硬币和一个锤子。接下来发生了两个并发操作: 在副本 a 上她发现了一个钉子,在副本 b 上 Alice 被删除(删除所有项目)。

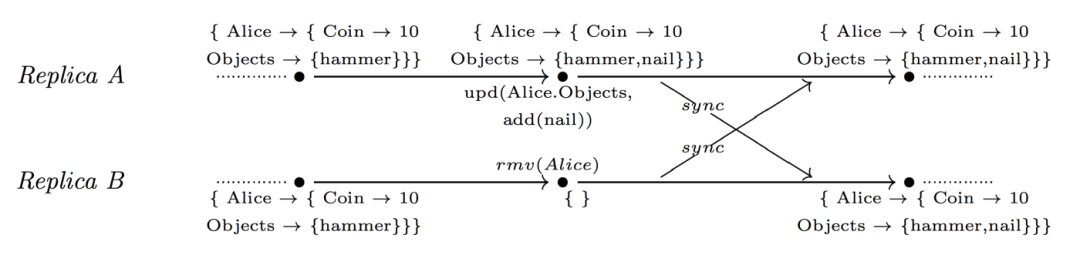
4.5.3 Update-wins map
Add ()优先于 rmv () ,更准确地说,add ()取消了以前所有的并发 rmv ()。
例如,玩家李四在一个在线游戏中在副本 a 上被删除,同时她在副本 b 上做了一些活动。很明显,rmv ()操作必须被取消。
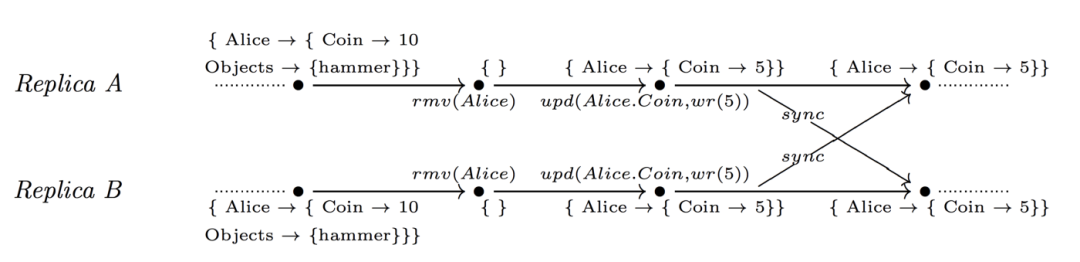
需要注意的是, 假设我们有两个副本 a 和 b,它们以 k 为单位存储一组复制品。如果 a 删除了密钥 k,b 删除了集合中的所有元素,那么最终,两个副本的密钥 k 下都会有一个空集。
然而,有时不能取消以前所有的 rmv ()操作。考虑下面的例子,如果用这种方法,同步状态将与初始状态相同,这是一个不正确的结果。
4.6 CRDT之List
这种类型的问题在于,在本地更新操作之后,不同的副本上的元素索引将会不同。为了解决这个问题,可以使用操作转换索引的方法,在应用接收到的更新操作时,必须考虑原始索引。
5 构建基于CRDT的应用
将应用程序连接到基于CRDT的数据库与将应用程序连接到任何其他数据库没有什么不同。然而,由于最终一致性的策略,应用程序需要遵循一定的规则来提供一致的用户体验,其中的三个关键点是:
1. 应用程序无状态
无状态应用程序通常是 api 驱动的。对 API 的每次调用都会导致从头重新构建完整的消息。这可以确保在任何时候获得一个干净的数据副本。基于CRDT的数据库提供的低本地延迟使得重构消息更快更容易 。
2. 选择适合场景的正确 CRDT
计数器是 crt 中最简单的。它可以应用于诸如全局投票、跟踪活动会话、计量等用例。但是,如果要合并分布式对象的状态,那么还必须考虑其他数据结构。例如,对于允许用户编辑共享文档的应用程序,您可能不仅希望保留编辑,还希望保留执行编辑的顺序。在这种情况下,将编辑保存在基于 crdt 的列表或队列数据结构中将是比将编辑保存在寄存器中更好的解决方案。了解由 crt 强制执行的冲突解决语义,以及您的解决方案符合规则也很重要
3. CRDT 不是一个万能的解决方案 !
为了实现更快的上线应用,建议拥有一致的开发、测试、阶段化和生产设置。除此之外,这意味着开发和测试设置必须有一个小型化的模型。检查基于CRDT的数据库是可用的 Docker 容器还是可用的虚拟设备。将数据库副本部署到不同的子网上,这样就可以模拟已连接和断开连接的集群设置。
使用分布式多leader数据库测试应用程序可能听起来很复杂。但是在大多数情况下,需要测试的是数据一致性和应用程序可用性,这两种情况分别是: 连接分布式数据库时,以及数据库之间存在网络划分时。
通常,可以在开发环境中设置一个三节点的测试用分布式数据库,就可以覆盖单元测试中的大多数测试场景。以下是测试应用的基本准则:
(1)网络连接和节点间延迟低的测试用例
测试用例必须更加强调模拟冲突。通常,可以通过多次跨不同节点更新相同的数据来实现这一点,在所有节点上合并暂停并验证数据的步骤。即使数据库副本是连续同步的,测试最终一致性数据库也需要暂停测试并检查数据。
对于验证,要验证两件事: 所有数据库副本具有相同的数据,以及每当发生冲突时,冲突解决将按照设计进行。
(2)分区网络的测试用例
这里,通常执行与前面相同的测试用例,但是分为两个步骤。在第一步中,使用分区网络测试应用程序,也就是说,数据库无法彼此同步的情况。当网络被拆分时,数据库不会合并所有数据。因此,测试用例必须假设只读取数据的本地副本。在第二步中,重新连接所有网络以测试合并是如何发生的。如果遵循与前一节相同的测试用例,那么最终的数据必须与前一组步骤中的数据相同。
6. CRDT的应用示例
6.1 CRDT 用例: 投票,喜欢,爱心,表情符号等的计数
计数器有许多应用程序。作为一个分布式的应用程序,它可以收集选票,衡量一篇文章中“赞”的数量,或者跟踪一条信息的表情符号反应数量。例如,每个地理位置的本地应用程序连接到最近的数据库集群,更新计数器并用本地延迟读取计数器。
可以使用 PN-Counter 的CRDT,示意代码如下:
void countVote(String pollId){
// CRDT Command: COUNTER_INCREMENT poll:[pollId]:counter
}
long getVoteCount(String pollId){
// CRDT Command: COUNTER_GET poll:[pollId]:counter
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
6.2 CRDT 用例: 分布式缓存
分布式缓存的缓存机制与本地缓存中使用的机制相同: 应用程序尝试从缓存中获取对象。如果对象不存在,则应用程序从主存储区检索并将其保存在缓存中,并设置适当的过期时间。如果将缓存对象存储在基于CRDT的数据库中,该数据库将自动在所有区域中提供缓存。例如,将每个电影的海报缓存到本地环境。
采用register的CRDT,示意代码如下:
void cacheString(String objectId, String cacheData, int ttl){
// CRDT command: REGISTER_SET object:[objectId] [cacheData] ex [ttl]
}
String getFromCache(String objectId){
// CRDT command: REGISTER_GET object:[objectId]
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
6.3 CRDT 用例: 使用共享会话数据进行协作
CRDT最初是为支持多用户文档编辑而开发的。共享会话用于游戏、电子商务、社交网络、聊天、协作、应急响应和许多其他应用程序。例如,一个简单的婚礼祝福应用,在这个应用中,新婚夫妇的所有祝福者都将他们的礼物添加到购物车中,该购物车作为共享会话进行管理。
婚礼祝福的应用程序是一个分布式应用,每个实例都连接到本地数据库。在开始一个会话时,应用的所有者邀请他们来自世界各地的朋友。一旦被邀请者接受邀请,他们就可以访问会话对象。然后,他们购物并将商品添加到购物车中。
2P-Set 和一个 PN-counter 用于存放购物车中的物品,另外还有一个2P-Set 用于存储活动会话,示意代码如下:
void joinSession(String sharedSessionID, sessionID){
// CRDT command: SET_ADD sharedSession:[sharedSessionId] [sessionID]
}
void addToCart(String sharedSessionId, String productId, int count){
// CRDT command:
// ZSET_ADD sharedSession:[sharedSessionId] productId count
}
getCartItems(String sharedSessionId){
// CRDT command:
// ZSET_RANGE sharedSession:sessionSessionId 0 -1
}
6.4 CRDT 应用: 多
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
6.4 CRDT 应用: 多区域数据摄取
List或队列在许多应用程序中使用。例如,订单处理系统在基于 CRDT的 List 数据结构中维护活动作业。这个解决方案在不同的地点收集任务。每个位置的分布式应用程序连接到最近的数据库副本。这减少了写操作的网络延迟,从而允许应用程序支持大量作业提交。这些作业是从一个集群的 List 数据结构中弹出的。这保证了作业只被处理一次。
基于 CRDT的List,列表数据结构用作 FIFO 队列的示意代码如下:
pushJob(String jobQueueId, String job){
// CRDT command: LIST_LEFT_PUSH job:[jobQueueId] [job]
}
popJob(String jobQueueId){
// CRDT command: LIST_RIGHT_POP job:[jobQueueId]
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
小结
CRDT 对于许多用例来说确实是一个很好的工具,通过在这些场景和其他场景中利用基于 crdt 的数据库,您可以专注于业务逻辑,而不用担心区域之间的数据同步。最重要的是,基于 crdt 的数据库可以提供本地的应用延迟,同时承诺即使在数据中心之间出现网络故障时也可以提供强大的最终一致性。
但是,它可能不是所有用例(例如 ACID 事务)的最佳工具。基于 CRDT的数据库通常非常适合微服务体系结构,其中每个微服务都有一个专门的数据库。当然,区块链或许是使用CRDT 的又一主要场景。
【参考资料与关联阅读】
- https://www.infoq.com/presentations/CRDT
- Strong Eventual Consistency and Conflict-free Replicated Data Types
- Key-CRDT Stores https://run.unl.pt/bitstream/10362/7802/1/Sousa_2012.pdf
- Conflict-free Replicated Data Types: An Overview https://arxiv.org/pdf/1806.10254.pdf
- A Conflict-Free Replicated JSON Datatype https://arxiv.org/abs/1608.03960
- A comprehensive study of Convergent and Commutative Replicated Data Types https://hal.inria.fr/inria-00555588/document
- Convergent and Commutative Replicated Data Type https://core.ac.uk/download/pdf/55634119.pdf
- Conflict-free replicated data type https://en.wikipedia.org/wiki/Conflict-freereplicateddata_type
- CRDTs: An UPDATE (or just a PUT) https://speakerdeck.com/lenary/crdts-an-update-or-just-a-put
- https://medium.com/@amberovsky/crdt-conflict-free-replicated-data-types-b4bfc8459d26