












曾经看到这么一个案例,有一个团队需要开发一个图片存储系统,要求这个系统能快速记录图片ID和图片存储对象ID,同时还需要能够根据图片的ID快速找到图片存储对象ID。我们假设用10位数来表示图片ID和图片存储对象ID,例如图片的ID为1101021043,它所对应的图片存储对象的ID为2301010051,可以看到图片ID和图片存储ID正好是一一对应的,是典型的key-value形式,所以首先会想到直接使用String类型来保存数据。把图片ID和图片存储ID分别作为键值对的key和value来保存。但是随着存储的数据量越来越大,Redis的内存的使用量也快速上升,结果遇到了大内存Redis实例因为生成RDB而响应变慢的问题。很显然String类型并不是一种好的选择,
那有什么办法可以降低内存消耗吗?
String类型的数据结构
首先我们得先了解为什么String保存数据时所消耗的内存空间较大。在刚才的案例中,由于图片ID和图片存储对象ID都是10位数,我们可以用两个8字节的Long类型来表示这两个ID。所以一组图片ID及其存储对象ID的记录,实际只需要16字节就可以了。但是通过对Redis内存分析,一组图片ID及其存储对象ID却占用了64字节,那为什么String类型会用64字节呢。其实,除了要记录实际的数据,String类型还需要额外的内存空间来记录数据的长度、空间使用信息等,这些信息也叫做元数据。当实际保存的数据较小时,元数据的空间开销就显的比较大了。我们先来看一下String类型是如何保存数据的。当你保存64位有符号的整数时,String类型会把它保存为一个8字节的Long类型整数,这种保存方式通常也叫作int编码方式。但是,当你保存的数据中包含字符时,String类型就会用简单动态字符串结构体(SDS)来保存。如下图所示:

-
len:4个字节,表示buf的已用长度。
-
alloc:4个字节,表示buf分配的长度,一般大于len。
-
buf:字节数组,保存实际数据。为了表示数组的结尾,Redis会自动在数组最后添加一个”\0"。
可以看到,在SDS结构体中,除了有保存实际数据的buf,还有len和alloc的额外元数据的开销。另外对于String类型来说,除了SDS的额外开销外,还有一个叫做RedisObject结构体的开销。因为Redis的数据类型有很多,不同的数据类型都有相同的元数据要记录(例如最后一次访问时间),所以Redis会采用一个叫做RedisObject结构体来统一记录这些元数据。一个RedisObject包含了一个8字节的元数据和一个8字节的指针,这个指针指向具体数据所在,例如String类型的SDS结构体所在的内存地址。如下图所示:
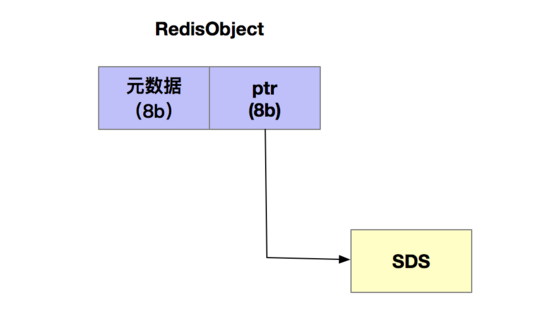
为了节省内存空间,Redis对Long类型整数和SDS的内存布局做了专门的设计。一方面,当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。另一方面,当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。当字符串大于44字节时,SDS的数据量就开始变多了,Redis 就不再把SDS 和
RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。如下图所示:
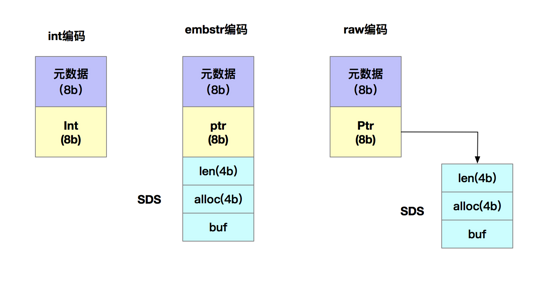
现在我们来计算一下一对图片ID和图片存储对象ID的内存的使用量。由于10位数的图片ID和图片存储对象ID是Long类型整数,所以可以直接用int编码的RedisObject保存。相对应的RedisObject元数据部分占8字节,指针部分被直接赋值为8字节的整数了。此时,每个ID会使用16字节,加起来一共是32字节。但是,另外的 32 字节去哪儿了呢?
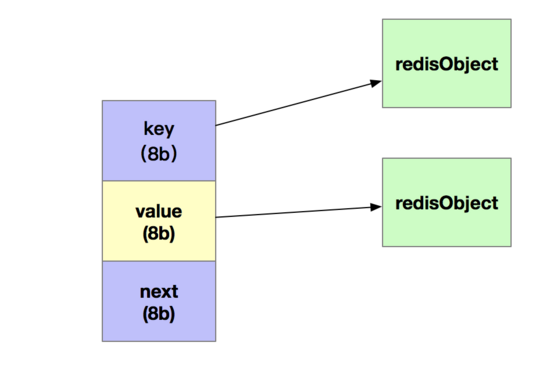
由于Redis是使用全局哈希表来保存所有的键值对,哈希表的每一项是一个dictEntity的结构体来指向一个键值对。dictEntity由三个8字节的指针组成,分别来指向key、value以及下一个dictEntity。如下图所示。
由于Redis使用的内存分配库为jemalloc,jemalloc在分配内存时,会根据申请的字节数N,找一个比N大的,最接近N的2的幂次数作为分配的空间。
所以申请一个24字节的dictEntity,实际会分配32个字节。
到目前位置,你应该明白了为什么String类型来保存图片ID和图片存储对象ID会占用64个字节了。一个有效信息只有16个字节,在使用String类型保存时,却要占用64个字节内存空间,有48个字节用来保存元数据信息了,这是不是极大的浪费了内存空间。那么有没有更加节省内存的方法呢?
用压缩列表节省内存
Redis里有一种叫做压缩列表的结构,非常节省内存。我们先回顾一下压缩列表的构成。表头有三个字段zlbytes、zllen和zltail,分别表示列表的长度、列表尾的偏移量以及列表中entry的个数。压缩列表表尾有一个zlend,表示列表结束。如下图所示。
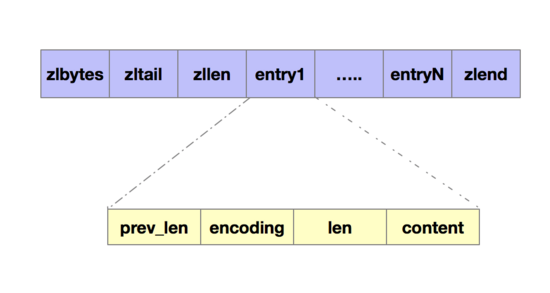
由于压缩列表采用一系列的entry保存数据,这些entry会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。每个entry由以下几部分组成。
-
pre_len:表示前一个entry的长度。prev_len有两种取值情况:1 字节或 5 字节。当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
-
len:表示自身的长度,占4个字节。
-
encoding:表示编码方式,占1个字节。
-
content:保存实际数据。
假设我们使用entry来保存图片存储对象ID(占8个字节),此时,每个entry的prev_len占用1个字节就行,因为每一个entry的前一个entry的长度小于264字节。这样一来,一个图片对象ID所占用的内存大小是14(1+4+1+8)个字节,实际上会分配16个字节。
Redis里基于压缩列表实现了List、Hash和Sorted Set集合类型,这样做的最大好处就是节省了dictEntity的内存开销。对于String类型来说,一个键值对就有一个dictEntity,占用32个字节。对于集合类型来说,一个key对应了很多数据,却只是占用了一个dictEntity,这样就节省了内存空间。
如何用集合类型存储单值的键值对的数据
在保存单值键值对的数据时,我们可以使用基于Hash类型的二级编码方式。这里所说的二级编码,是指把单值的数据拆成两部分,前一部分作为Hash的key,后一部分作为Hash的value。 以图片的ID为1101021043,它所对应的图片存储对象的ID为2301010051为例,我们将图片的ID的前7位(1101021)作为Hash类型的键,后3位(043)和图片存储对象ID为2301010051作为Hash类型的key和value。我们按照这种设计,在Redis中插入一条记录,只占用了16字节,所以和使用String类型占用64字节对比,节省了很多空间。 最后,我们再思考一个问题,为什么要把图片ID的前7位作为Hash类型的键,后3位作为Hash类型的key呢。我们在 Redis存储结构 里介绍过Redis的Hash类型的两种底层实现结构,分别是压缩列表和哈希表。Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。这两个阈值分别对应以下两个配置项:-
hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
-
hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
在内存节省空间方面,哈希表就没有压缩列表那么高效。我们只用后3位作为Hash类型的key,也就保证哈希集合中元素的个数不会超过1000,同时我们通过设置hash-max-ziplist-entries=1000,来确保Hash类型底层使用的是压缩列表这种数据结构。


















