












进一步学习自然语言处理的基本概念
在 之前的文章 里,我介绍了自然语言处理(NLP)和宾夕法尼亚大学研发的自然语言处理工具包 (NLTK)。我演示了用 Python 解析文本和定义停顿词的方法,并介绍了语料库的概念。语料库是由文本构成的数据集,通过提供现成的文本数据来辅助文本处理。在这篇文章里,我将继续用各种语料库对文本进行对比和分析。
这篇文章主要包括以下部分:
- 词网和同义词集
- 相似度比较
- 树和树库
- 命名实体识别
词网和同义词集
词网 是 NLTK 里的一个大型词汇数据库语料库。词网包含各单词的诸多认知同义词(认知同义词常被称作“同义词集”)。在词网里,名词、动词、形容词和副词,各自被组织成一个同义词的网络。
词网是一个很有用的文本分析工具。它有面向多种语言的版本(汉语、英语、日语、俄语和西班牙语等),也使用多种许可证(从开源许可证到商业许可证都有)。初代版本的词网由普林斯顿大学研发,面向英语,使用类 MIT 许可证。
因为一个词可能有多个意义或多个词性,所以可能与多个同义词集相关联。每个同义词集通常提供下列属性:
属性
定义
例子
名称
此同义词集的名称
单词
code 有 5 个同义词集,名称分别是 code.n.01、 code.n.02、 code.n.03、code.v.01 和 code.v.02
词性
此同义词集的词性
单词
code 有 3 个名词词性的同义词集和 2 个动词词性的同义词集
定义
该词作对应词性时的定义
动词
code 的一个定义是:(计算机科学)数据或计算机程序指令的象征性排列
例子
使用该词的例子
code 一词的例子:We should encode the message for security reasons
词元
与该词相关联的其他同义词集(包括那些不一定严格地是该词的同义词,但可以大体看作同义词的);词元直接与其他词元相关联,而不是直接与单词相关联
code.v.02 的词元是 code.v.02.encipher、code.v.02.cipher、code.v.02.cypher、code.v.02.encrypt、code.v.02.inscribe 和 code.v.02.write_in_code
反义词
意思相反的词
词元
encode.v.01.encode 的反义词是 decode.v.01.decode
上义词
该词所属的一个范畴更大的词
code.v.01 的一个上义词是 tag.v.01
分项词
属于该词组成部分的词
computer 的一个分项词是 chip
总项词
该词作为组成部分所属的词
window 的一个总项词是 computer screen
同义词集还有一些其他属性,在 <你的 Python 安装路径>/Lib/site-packages 下的 nltk/corpus/reader/wordnet.py,你可以找到它们。
下面的代码或许可以帮助理解。
这个函数:
from nltk.corpus import wordnetdef synset_info(synset):print("Name", synset.name())print("POS:", synset.pos())print("Definition:", synset.definition())print("Examples:", synset.examples())print("Lemmas:", synset.lemmas())print("Antonyms:", [lemma.antonyms() for lemma in synset.lemmas() if len(lemma.antonyms()) > 0])print("Hypernyms:", synset.hypernyms())print("Instance Hypernyms:", synset.instance_hypernyms())print("Part Holonyms:", synset.part_holonyms())print("Part Meronyms:", synset.part_meronyms())print()synsets = wordnet.synsets('code')print(len(synsets), "synsets:")for synset in synsets:synset_info(synset)
将会显示:
5 synsets:Name code.n.01POS: nDefinition: a set of rules or principles or laws (especially written ones)Examples: []Lemmas: [Lemma('code.n.01.code'), Lemma('code.n.01.codification')]Antonyms: []Hypernyms: [Synset('written_communication.n.01')]Instance Hpernyms: []Part Holonyms: []Part Meronyms: []...Name code.n.03POS: nDefinition: (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructionsExamples: []Lemmas: [Lemma('code.n.03.code'), Lemma('code.n.03.computer_code')]Antonyms: []Hypernyms: [Synset('coding_system.n.01')]Instance Hpernyms: []Part Holonyms: []Part Meronyms: []...Name code.v.02POS: vDefinition: convert ordinary language into codeExamples: ['We should encode the message for security reasons']Lemmas: [Lemma('code.v.02.code'), Lemma('code.v.02.encipher'), Lemma('code.v.02.cipher'), Lemma('code.v.02.cypher'), Lemma('code.v.02.encrypt'), Lemma('code.v.02.inscribe'), Lemma('code.v.02.write_in_code')]Antonyms: []Hypernyms: [Synset('encode.v.01')]Instance Hpernyms: []Part Holonyms: []Part Meronyms: []
同义词集和词元在词网里是按照树状结构组织起来的,下面的代码会给出直观的展现:
def hypernyms(synset):return synset.hypernyms()synsets = wordnet.synsets('soccer')for synset in synsets:print(synset.name() + " tree:")pprint(synset.tree(rel=hypernyms))print()
code.n.01 tree:[Synset('code.n.01'),[Synset('written_communication.n.01'),...code.n.02 tree:[Synset('code.n.02'),[Synset('coding_system.n.01'),...code.n.03 tree:[Synset('code.n.03'),...code.v.01 tree:[Synset('code.v.01'),[Synset('tag.v.01'),...code.v.02 tree:[Synset('code.v.02'),[Synset('encode.v.01'),...
词网并没有涵盖所有的单词和其信息(现今英语有约 17,0000 个单词,最新版的 词网 涵盖了约 15,5000 个),但它开了个好头。掌握了“词网”的各个概念后,如果你觉得它词汇少,不能满足你的需要,可以转而使用其他工具。或者,你也可以打造自己的“词网”!
自主尝试
使用 Python 库,下载维基百科的 “open source” 页面,并列出该页面所有单词的同义词集和词元。
相似度比较
相似度比较的目的是识别出两篇文本的相似度,在搜索引擎、聊天机器人等方面有很多应用。
比如,相似度比较可以识别 football 和 soccer 是否有相似性。
syn1 = wordnet.synsets('football')syn2 = wordnet.synsets('soccer')# 一个单词可能有多个 同义词集,需要把 word1 的每个同义词集和 word2 的每个同义词集分别比较for s1 in syn1:for s2 in syn2:print("Path similarity of: ")print(s1, '(', s1.pos(), ')', '[', s1.definition(), ']')print(s2, '(', s2.pos(), ')', '[', s2.definition(), ']')print(" is", s1.path_similarity(s2))print()
Path similarity of:Synset('football.n.01') ( n ) [ any of various games played with a ball (round or oval) in which two teams try to kick or carry or propel the ball into each other's goal ]Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]is 0.5Path similarity of:Synset('football.n.02') ( n ) [ the inflated oblong ball used in playing American football ]Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]is 0.05
两个词各个同义词集之间路径相似度最大的是 0.5,表明它们关联性很大(路径相似度指两个词的意义在上下义关系的词汇分类结构中的最短距离)。
那么 code 和 bug 呢?这两个计算机领域的词的相似度是:
Path similarity of:Synset('code.n.01') ( n ) [ a set of rules or principles or laws (especially written ones) ]Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.1111111111111111...Path similarity of:Synset('code.n.02') ( n ) [ a coding system used for transmitting messages requiring brevity or secrecy ]Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.09090909090909091...Path similarity of:Synset('code.n.03') ( n ) [ (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions ]Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]is 0.09090909090909091
这些是这两个词各同义词集之间路径相似度的最大值,这些值表明两个词是有关联性的。
NLTK 提供多种相似度计分器,比如:
- path_similarity
- lch_similarity
- wup_similarity
- res_similarity
- jcn_similarity
- lin_similarity
要进一步了解这些相似度计分器,请查看 WordNet Interface 的 Similarity 部分。
自主尝试
使用 Python 库,从维基百科的 Category: Lists of computer terms 生成一个术语列表,然后计算各术语之间的相似度。
树和树库
使用 NLTK,你可以把文本表示成树状结构以便进行分析。
这里有一个例子:
这是一份简短的文本,对其做预处理和词性标注:
import nltktext = "I love open source"# Tokenize to wordswords = nltk.tokenize.word_tokenize(text)# POS tag the wordswords_tagged = nltk.pos_tag(words)
要把文本转换成树状结构,你必须定义一个语法。这个例子里用的是一个基于 Penn Treebank tags 的简单语法。
# A simple grammar to create treegrammar = "NP: {<JJ><NN>}"
然后用这个语法创建一颗树:
# Create treeparser = nltk.RegexpParser(grammar)tree = parser.parse(words_tagged)pprint(tree)
运行上面的代码,将得到:
Tree('S', [('I', 'PRP'), ('love', 'VBP'), Tree('NP', [('open', 'JJ'), ('source', 'NN')])])
你也可以图形化地显示结果。
tree.draw()
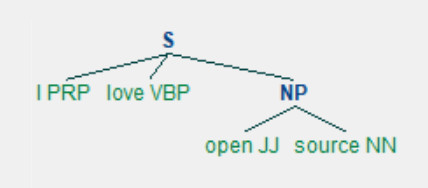
NLTK Tree
这个树状结构有助于准确解读文本的意思。比如,用它可以找到文本的 主语:
subject_tags = ["NN", "NNS", "NP", "NNP", "NNPS", "PRP", "PRP$"]def subject(sentence_tree):for tagged_word in sentence_tree:# A crude logic for this case - first word with these tags is considered subjectif tagged_word[1] in subject_tags:return tagged_word[0]print("Subject:", subject(tree))
结果显示主语是 I:
Subject: I
这是一个比较基础的文本分析步骤,可以用到更广泛的应用场景中。 比如,在聊天机器人方面,如果用户告诉机器人:“给我妈妈 Jane 预订一张机票,1 月 1 号伦敦飞纽约的”,机器人可以用这种分析方法解读这个指令:
动作: 预订
动作的对象: 机票
乘客: Jane
出发地: 伦敦
目的地: 纽约
日期: (明年)1 月 1 号
树库指由许多预先标注好的树构成的语料库。现在已经有面向多种语言的树库,既有开源的,也有限定条件下才能免费使用的,以及商用的。其中使用最广泛的是面向英语的宾州树库。宾州树库取材于华尔街日报。NLTK 也包含了宾州树库作为一个子语料库。下面是一些使用树库的方法:
words = nltk.corpus.treebank.words()print(len(words), "words:")print(words)tagged_sents = nltk.corpus.treebank.tagged_sents()print(len(tagged_sents), "sentences:")print(tagged_sents)
100676 words:['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', ...]3914 sentences:[[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ...]
查看一个句子里的各个标签:
sent0 = tagged_sents[0]pprint(sent0)
[('Pierre', 'NNP'),('Vinken', 'NNP'),(',', ','),('61', 'CD'),('years', 'NNS'),...
定义一个语法来把这个句子转换成树状结构:
grammar = '''Subject: {<NNP><NNP>}SubjectInfo: {<CD><NNS><JJ>}Action: {<MD><VB>}Object: {<DT><NN>}Stopwords: {<IN><DT>}ObjectInfo: {<JJ><NN>}When: {<NNP><CD>}'''parser = nltk.RegexpParser(grammar)tree = parser.parse(sent0)print(tree)
(S(Subject Pierre/NNP Vinken/NNP),/,(SubjectInfo 61/CD years/NNS old/JJ),/,(Action will/MD join/VB)(Object the/DT board/NN)as/INa/DT(ObjectInfo nonexecutive/JJ director/NN)(Subject Nov./NNP)29/CD./.)
图形化地显示:
tree.draw()

NLP Treebank image
树和树库的概念是文本分析的一个强大的组成部分。
自主尝试
使用 Python 库,下载维基百科的 “open source” 页面,将得到的文本以图形化的树状结构展现出来。
命名实体识别
无论口语还是书面语都包含着重要数据。文本处理的主要目标之一,就是提取出关键数据。几乎所有应用场景所需要提取关键数据,比如航空公司的订票机器人或者问答机器人。 NLTK 为此提供了一个命名实体识别的功能。
这里有一个代码示例:
sentence = 'Peterson first suggested the name "open source" at Palo Alto, California'
验证这个句子里的人名和地名有没有被识别出来。照例先预处理:
import nltkwords = nltk.word_tokenize(sentence)pos_tagged = nltk.pos_tag(words)
运行命名实体标注器:
ne_tagged = nltk.ne_chunk(pos_tagged)print("NE tagged text:")print(ne_tagged)print()
NE tagged text:(S(PERSON Peterson/NNP)first/RBsuggested/VBDthe/DTname/NN``/``open/JJsource/NN''/''at/IN(FACILITY Palo/NNP Alto/NNP),/,(GPE California/NNP))
上面的结果里,命名实体被识别出来并做了标注;只提取这个树里的命名实体:
print("Recognized named entities:")for ne in ne_tagged:if hasattr(ne, "label"):print(ne.label(), ne[0:])
Recognized named entities:PERSON [('Peterson', 'NNP')]FACILITY [('Palo', 'NNP'), ('Alto', 'NNP')]GPE [('California', 'NNP')]
图形化地显示:
ne_tagged.draw()

NLTK Treebank tree
NLTK 内置的命名实体标注器,使用的是宾州法尼亚大学的 Automatic Content Extraction(ACE)程序。该标注器能够识别组织机构、人名、地名、设施和地缘政治实体等常见实体。
NLTK 也可以使用其他标注器,比如 Stanford Named Entity Recognizer. 这个经过训练的标注器用 Java 写成,但 NLTK 提供了一个使用它的接口(详情请查看 nltk.parse.stanford 或 nltk.tag.stanford)。
自主尝试
使用 Python 库,下载维基百科的 “open source” 页面,并识别出对开源有影响力的人的名字,以及他们为开源做贡献的时间和地点。
高级实践
如果你准备好了,尝试用这篇文章以及此前的文章介绍的知识构建一个超级结构。
使用 Python 库,下载维基百科的 “Category: Computer science page”,然后:
- 找出其中频率最高的单词、二元搭配和三元搭配,将它们作为一个关键词列表或者技术列表。相关领域的学生或者工程师需要了解这样一份列表里的内容。
- 图形化地显示这个领域里重要的人名、技术、日期和地点。这会是一份很棒的信息图。
- 构建一个搜索引擎。你的搜索引擎性能能够超过维基百科吗?
下一步?
自然语言处理是应用构建的典型支柱。NLTK 是经典、丰富且强大的工具集,提供了为现实世界构建有吸引力、目标明确的应用的工作坊。
在这个系列的文章里,我用 NLTK 作为例子,展示了自然语言处理可以做什么。自然语言处理和 NLTK 还有太多东西值得探索,这个系列的文章只是帮助你探索它们的切入点。
如果你的需求增长到 NLTK 已经满足不了了,你可以训练新的模型或者向 NLTK 添加新的功能。基于 NLTK 构建的新的自然语言处理库正在不断涌现,机器学习也正被深度用于自然语言处理。
















