一 前言
FlatBuffers 是一个开源的、跨平台的、高效的、提供了多种语言接口的序列化工具库。实现了与 Protocal Buffers 类似的序列化格式。主要由 Wouter van Oortmerssen 编写,并由 Google 开源。Oortmerssen 最初为 Android 游戏和注重性能的应用而开发了 FlatBuffers,现在它具有 C ++、C#、C、Go、Java、PHP、Python 和 JavaScript 的接口。
高德地图数据编译增量发布使用了FlatBuffers序列化工具,借此契机对FlatBuffers原理进行研究并分享于此。本文简单介绍 FlatBuffers Scheme,通过剖析 FlatBuffers 序列化与反序列化原理,重点回答以下问题:
问题1:FlatBuffers 如何做到反序列化速度极快的(或者说无需解码)。
问题2:FlatBuffers 如何做到默认值不占存储空间的(Table 结构内的变量)。
问题3:FlatBuffers 如何做到字节对齐的。
问题4:FlatBuffers 如何做到向前向后兼容的(Struct 结构除外)。
问题5:FlatBuffers 在 add 字段时有没有顺序要求(Table 结构)。
问题6:FlatBuffers 如何根据 Scheme 自动生成编解码器。
问题7:FlatBuffers 如何根据 Scheme 自动生成 Json。
二 FlatBuffers Scheme
FlatBuffers 通过 Scheme 文件定义数据结构,Schema 定义与其他框架使用的IDL(Interface description language)语言类似简单易懂,FlatBuffers 的 Scheme 是一种类 C 的语言(尽管 FlatBuffers 有自己的接口定义语言 Scheme 来定义要与之序列化的数据,但它也支持 Protocol Buffers 中的 .proto 格式)。下面以官方 Tutorial 中的 monster.fbs 为例进行说明:
// Example IDL file for our monster's schema.namespace MyGame.Sample;enum Color:byte { Red = 0, Green, Blue = 2 }union Equipment { Weapon } // Optionally add more tables.struct Vec3 { x:float; y:float; z:float;}table Monster { pos:Vec3; mana:short = 150; hp:short = 100; name:string; friendly:bool = false (deprecated); inventory:[ubyte]; color:Color = Blue; weapons:[Weapon]; equipped:Equipment; path:[Vec3];}table Weapon { name:string; damage:short;}root_type Monster;
namespace MyGame.Sample;
namespace 定义命名空间,可以定义嵌套的命名空间,用 . 分割。
enum Color:byte { Red = 0, Green, Blue = 2 };
enum 定义枚举类型。和常规的枚举类稍有不同的地方是可以定义类型。比如这里的 Color 是 byte 类型。enum 字段只能新增,不能废弃。
union Equipment {Weapon} // Optionally add more tables
union 类似 C/C++ 中的概念,一个 union 中可以放置多种类型,共同使用一个内存区域。这里的使用是互斥的,即这块内存区域只能由其中一种类型使用。相对 struct 来说比较节省内存。union 跟 enum 比较类似,但是 union 包含的是 table,enum 包含的是 scalar 或者 struct。union 也只能作为 table 的一部分,不能作 root type。
struct Vect3{ x : float; y : float; z : float;};
struct 所有字段都是必填的,因此没有默认值。字段也不能添加或者废弃,且只能包含标量或者其他 struct。struct 主要用于数据结构不会发生改变的场景,相对 table 使用更少的内存,lookup 的时候速度更快(struct 保存在父 table 中,不需要使用 vtable)。
table Monster{};
table 是在 FlatBuffers 中定义对象的主要方式,由一个名称(这里是 Monster)和一个字段列表组成。可以包含上面定义的所有类型。每个字段(Field)包括名称、类型和默认值三部分;每个字段都有默认值,如果没有明确写出则默认为 0 或者 null。每个字段都不是必须的,可以为每个对象选择要省略的字段,这是 FlatBuffers 向前和向后兼容的机制。
root_type Monster;
用于指定序列化后的数据的 root table。

Scheme 设计需要特别注意的:
新字段只能加在 table 的后面。旧代码会忽略这个字段,仍然可以正常执行。新代码读取旧的数据,会取到新增字段的默认值。
即使字段不再使用了也不能从 Scheme 中删除。可以标记为 deprecated,在生成代码的时候不会生成该字段的访问器。
如果需要嵌套的 vector,可以将 vector 包装在 table 中。string 对于其他编码可以使用 [byte] 或者 [ubyte] 支持。
三 FlatBuffers 的序列化
简单来说 FlatBuffers 就是把对象数据,保存在一个一维的数组中,将数据都缓存在一个 ByteBuffer 中,每个对象在数组中被分为两部分。元数据部分:负责存放索引。真实数据部分:存放实际的值。然而 FlatBuffers 与大多数内存中的数据结构不同,它使用严格的对齐规则和字节顺序来确保 buffer 是跨平台的。此外,对于 table 对象,FlatBuffers 提供前向/后向兼容性和 optional 字段,以支持大多数格式的演变。除了解析效率以外,二进制格式还带来了另一个优势,数据的二进制表示通常更具有效率。我们可以使用 4 字节的 UInt 而不是 10 个字符来存储 10 位数字的整数。
FlatBuffers 对序列化基本使用原则:
小端模式。FlatBuffers 对各种基本数据的存储都是按照小端模式来进行的,因为这种模式目前和大部分处理器的存储模式是一致的,可以加快数据读写的数据。
写入数据方向和读取数据方向不同。
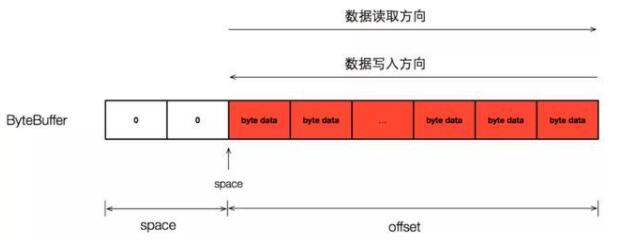
FlatBuffers 向 ByteBuffer 中写入数据的顺序是从 ByteBuffer 的尾部向头部填充,由于这种增长方向和 ByteBuffer 默认的增长方向不同,因此 FlatBuffers 在向 ByteBuffer 中写入数据的时候就不能依赖 ByteBuffer 的 position 来标记有效数据位置,而是自己维护了一个 space 变量来指明有效数据的位置,在分析 FlatBuffersBuilder 的时候要特别注意这个变量的增长特点。但是,和数据的写入方向不同的是,FlatBuffers 从 ByteBuffer 中解析数据的时候又是按照 ByteBuffer 正常的顺序来进行的。FlatBuffers 这样组织数据存储的好处是,在从左到右解析数据的时候,能够保证最先读取到的就是整个 ByteBuffer 的概要信息(例如 Table 类型的 vtable 字段),方便解析。
对于每种数据类型的序列化:
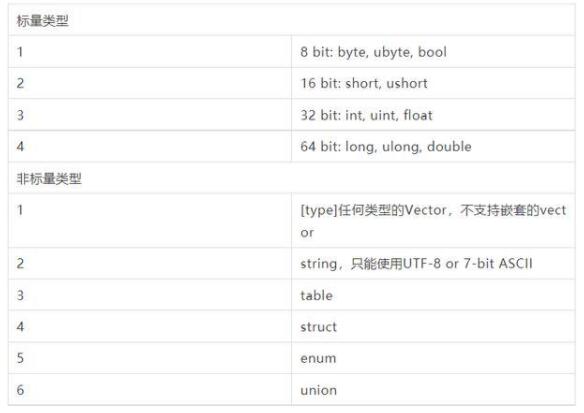
1 标量类型
标量类型即基本类型,如:int,double,bool等,标量类型使用直接寻址进行数据访问。
示例:short mana = 150; 12个字节,存储结构如下:
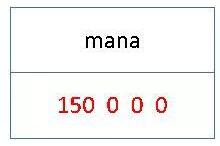
schema 中定义标量可以设置默认值。文章最初提到 FlatBuffers 的默认值不占存储空间的,对于 table 内部的标量,是可以做到默认值不存储的,如果变量的值不需要改变,该字段在 vtable 中对应的 offset 的值设置为 0 即可,默认值被记录在解码接口内,解码时获取该字段的 offset 为 0 时,解码接口则返回默认值。对于 struct 结构因为没有使用 vtable 结构,因此内部的标量没有默认值,必须存储(struct 类型和 table 类型的序列化原理在下文会详细说明)。
// Computes how many bytes you'd have to pad to be able to write an// "scalar_size" scalar if the buffer had grown to "buf_size" (downwards in// memory).inline size_t PaddingBytes(size_t buf_size, size_t scalar_size) { return ((~buf_size) + 1) & (scalar_size - 1);}
- 1.
标量数据类型是按其本身字节数大小进行对齐。通过 PaddingBytes 函数计算,所有标量都会调用这个函数,进行字节对齐。
2 Struct 类型
除了基本类型之外,FlatBuffers 中只有 Struct 类型使用直接寻址进行数据访问。FlatBuffers 规定 Struct 类型用于存储那些约定成俗、永不改变的数据,这种类型的数据结构一旦确定便永远不会改变,没有任何字段是可选的(也没有默认值),字段可能不会被添加或被弃用,所以 structs 不提供前向/后向兼容性。在这个规定之下,为了提高数据访问速度,FlatBuffers 单独对 Struct 使用了直接寻址的方式。字段的顺序即为存储的顺序。struct 有的特性一般不作为 schema 文件的根。
示例:struct Vec3(16, 17, 18); 12个字节
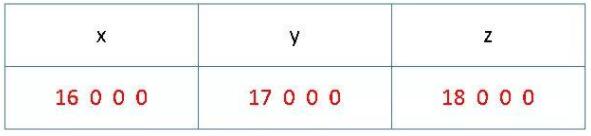
struct 定义了一个固定的内存布局,其中所有字段都与其大小对齐,并且 struct 与其最大标量成员对齐。
3 vector 类型
vector 类型实际上就是 schema 中声明的数组类型,FlatBuffers 中也没有单独的类型和它对应,但是它却有自己独立的一套存储结构,在序列化数据时先会从高位到低位依次存储 vector 内部的数据,然后再在数据序列化完毕后写入 Vector 的成员个数。数据存储结构如下:
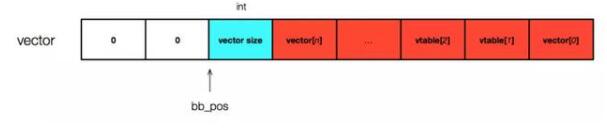
示例:byte[] treasure = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };

vector size 的类型为 int,因此在初始化申请内存时 vector 进行四字节字节对齐。
4 String 类型
FlatBuffers 字符串按照 utf-8 的方式进行了编码,在实现字符串写入的时候将字符串的编码数组当做了一维的 vector 来实现。string 本质上也可以看做是 byte 的 vector ,因此创建过程和 vector 基本一致,唯一的区别就是字符串是以null结尾,即最后一位是 0。string 写入数据的结构如下:

示例:string name = “Sword”;

vector size 的类型为 int,因此在初始化申请内存时字符串进行四字节字节对齐。
5 Union 类型
Union 类型比较特殊,FlatBuffers 规定这个类型在使用上具有如下两个限制:
Union 类型的成员只能是 Table 类型。
Union 类型不能是一个 schema 文件的根。
FlatBuffers 中没有特定类型表示 union,而是会生成一个单独的类对应 union 的成员类型。与其他类型的主要区别是需要先指定类型,在序列化 Union 的时候一般先写入 Union 的 type,然后再写入 Union 的数据偏移;在反序列化 Union 的时候一般先
析出 Union 的 type,然后再按照 type 对应的 Table 类型来解析 Union 对应的数据。
6 Enum 类型
FlatBuffers 中的 enum 类型在数据存储的时候是和 byte 类型存储的方式一样的。因为和 Union 类型相似,enum 类型在 FlatBuffers 中也没有单独的类与它对应,在 schema 中声明为 enum 的类会被编译生成单独的类。
enum 类型不能是一个 schema 文件的根。
7 Table 类型
table 是 FlatBuffers 的基石,为了解决数据结构变更的问题,table 通过 vtable 间接访问字段。每个 table 都带有一个 vtable(可以在具有相同布局的多个 table 之间共享),并且包含存储此特定类型 vtable 实例的字段的信息。vtable 还可能表明该字段不存在(因为此 FlatBuffers 是使用旧版本的代码编写的,仅仅因为信息对于此实例不是必需的,或者被视为已弃用),在这种情况下会返回默认值。
table 的内存开销很小(因为 vtables 很小并且共享)访问成本也很小(间接访问),但是提供了很大的灵活性。table 在特殊情况下可能比等价的 struct 花费更少的内存,因为字段在等于默认值时不需要存储在 buffer 中。这样的结构决定了一些复杂类型的成员都是使用相对寻址进行数据访问的,即先从Table 中取到成员常量的偏移,然后根据这个偏移再去常量真正存储的地址去取真实数据。
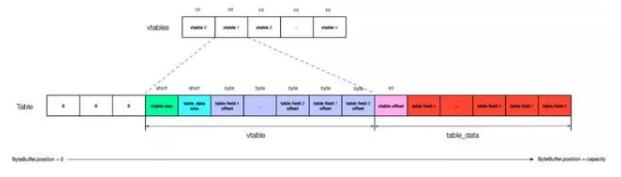
单就结构来讲:首先可以将 Table 分为两个部分,第一部分是存储 Table 中各个成员变量的概要,这里命名为 vtable,第二部分是 Table 的数据部分,存储 Table 中各个成员的值,这里命名为 table_data。注意 Table 中的成员如果是简单类型或者 Struct 类型,那么这个成员的具体数值就直接存储在 table_data中;如果成员是复杂类型,那么 table_data 中存储的只是这个成员数据相对于写入地址的偏移,也就是说要获得这个成员的真正数据还要取出 table_data 中的数据进行一次相对寻址。

vtable 是一个 short 类型的数组,其长度为(字段个数+2)*2字节,第一个字段是 vtable 的大小,包括这个大小本身;第二个字段是 vtable 对应的对象的大小,包括到 vtable 的 offset;接下来是每个字段相对于对象开始位置的 offset。
table_data 的开头是 vtable 开始位置减去当前table对象开始位置的 INT 型 offset,由于 vtable 可能在任意的地方,这个值有可能是负值。table_data开始用int存储了vtable的offset,因此进行了四字节对齐的。
add 的操作是添加 table_data,由于 Table 数据结构的是通过 vtable - table_data 机制存储的,这个操作没有强制要求字段的先后顺序,对顺序没有要求,因为vtable在记录每个字段相对于对象开始位置的 offset 时是按照 schema 中定义的顺序进行存储的,所以在add字段的时候即使没有顺序也可以根据 offset 获取正确的值。需要注意的是,每次add字段时 FlatBuffers 都会做字节对齐处理。
std::string e_poiId = "1234567890";double e_coord_x = 0.1; double e_coord_y = 0.2;int e_minZoom = 10;int e_maxZoom = 200;//addfeatureBuilder.add_poiId(nameData);featureBuilder.add_x(e_coord_x);featureBuilder.add_y(e_coord_y);featureBuilder.add_maxZoom(e_maxZoom);featureBuilder.add_minZoom(e_minZoom);auto rootData = featurePoiBuilder.Finish();flatBufferBuilder.Finish(rootData);blob = flatBufferBuilder.GetBufferPointer();blobSize = flatBufferBuilder.GetSize();
- 1.
add 顺序 1:最终二进制的大小为 72 字节。
std::string e_poiId = "1234567890";double e_coord_x = 0.1; double e_coord_y = 0.2;int e_minZoom = 10;int e_maxZoom = 200;//addfeatureBuilder.add_poiId(nameData);featureBuilder.add_x(e_coord_x);featureBuilder.add_minZoom(e_minZoom);featureBuilder.add_y(e_coord_y);featureBuilder.add_maxZoom(e_maxZoom);auto rootData = featurePoiBuilder.Finish();flatBufferBuilder.Finish(rootData);blob = flatBufferBuilder.GetBufferPointer();blobSize = flatBufferBuilder.GetSize();
- 1.
add 顺序 2:最终二进制的大小为 80 字节。
add 顺序 1 和 add 顺序 2 对应的 schema 文件一样,表达的数据也一样,Table 结构在 add 字段时有没有顺序要求。序列化后的数据大小差8个字节,原因就是字节对齐导致的。因此 add 字段的时候,尽量把相同类型的字段放在一起进行 add,这样会避免不必要的字节对齐,获取更小的序列化结果。
FlatBuffers 的向前向后兼容指的是 table 结构。table 结构每个字段都有默认值,如果没有明确写出则默认为 0 或者 null。每个字段都不是必须的,可以为每个对象选择要省略的字段,这是 FlatBuffers 向前和向后兼容的机制。需要注意的是:
新的字段只能加在 table 的后面。旧的代码会忽略这个字段,仍然可以正常执行。新的代码读取旧的数据,新增的字段会返回默认值。
即使字段不再使用了也不能从 schema 中删除。可以标记为 deprecated,在生成代码的时候该字段不会生成该字段的接口。
四 FlatBuffers 的反序列化
FlatBuffers 反序列化的过程就很简单了。由于序列化的时候保存好了各个字段的 offset,反序列化的过程其实就是把数据从指定的 offset 中读取出来。反序列化的过程是把二进制流从 root table 往后读。从 vtable 中读取对应的 offset,然后在对应的 object 中找到对应的字段,如果是引用类型,string / vector / table,读取出 offset,再次寻找 offset 对应的值,读取出来。如果是非引用类型,根据 vtable 中的 offset ,找到对应的位置直接读取即可。对于标量,分 2 种情况,默认值和非默认值。默认值的字段,在读取的时候,会直接从 flatc 编译后的文件中记录的默认值中读取出来。非默认值字段,二进制流中就会记录该字段的 offset,值也会存储在二进制流中,反序列化时直接根据offset读取字段值即可。
整个反序列化的过程零拷贝,不消耗占用任何内存资源。并且 FlatBuffers 可以读取任意字段,而不是像 Json 和 protocol buffer 需要读取整个对象以后才能获取某个字段。FlatBuffers 的主要优势就在反序列化这里了。所以 FlatBuffers 可以做到解码速度极快,或者说无需解码直接读取。
五 FlatBuffers 的自动化
FlatBuffers 的自动化包括自动生成编码解码接口和自动生成 Json,自动化生成编解码接口和自动生成 Json,都依赖 schem 的解析。
1 schema 描述文件解析
FlatBuffers 描述文件解析器按游标的方式顺序进行识别 FlatBuffers 支持的数据结构。获取字段名称、字段类型、字段默认值、是否弃用等属性。支持关键字:标量类型、非标量类型、include、namespace、root_type。
如果需要嵌套的vector,可以将vector包装在table中。
2 自动生成编码解码接口
FlatBuffers 使用模板编程,编码解码接口仅生成h文件。实现数据结构的定义,并特化出变量的Add函数、Get函数,校验函数接口。对应的文件名为filename_generated.h。
3 自动生成Json
FlatBuffers 的主要目标是避免反序列化。通过定义二进制数据协议来实现的,一种将定义好的将数据转换为二进制数据的方法。由该协议创建的二进制结构无需进一步解码即可读取。因此在自动生成json时,只需要提供二进制数据流和二进制定义结构就可以读物数据,转换成json。
Json结构与 FlatBuffers 结构保持一致。
默认值不输出 Json。
六 FlatBuffers 的优缺点
FlatBuffers 通过 Scheme 文件定义数据结构,Schema 定义与其他框架使用的IDL(Interface description language)语言类似简单易懂,FlatBuffers 的 Scheme 是一种类C的语言(尽管 FlatBuffers 有自己的接口定义语言Scheme来定义要与之序列化的数据,但它也支持 Protocol Buffers 中的 .proto 格式)。下面以官方 Tutorial 中的 monster.fbs 为例进行说明:
1 优点
解码速度极快,将序列化数据存储在缓存中,这些数据既可以写出至文件中,又可以通过网络原样传输,也可直接读取而没有任何解析开销,访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。
扩展性、灵活性:它支持的可选字段意味着具有很好的前向/后向兼容。FlatBuffers 支持选择性地写入数据成员,这不仅为某一个数据结构在应用的不同版本之间提供了兼容性,同时还能使程序员灵活地选择是否写入某些字段及灵活地设计传输的数据结构。
跨平台:支持 C++11、Java,而不需要任何依赖库,在最新的 gcc、clang、vs2010 等编辑器上也工作良好。使用简单方便 ,仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中,生成的 C++ 代码提供了简单的访问和构造接口,可以兼容 Json 等其他格式的解析。
2 缺点
数据无可读性,必须进行数据可视化才能理解数据。
向后兼容性局限,在 schema 中添加或删除字段必须小心。
七 总结
相比其它的序列化工具,FlatBuffers 最大的优势是反序列化速度极快,或者说无需解码。如果使用场景是需要经常解码序列化的数据,则有可能从 FlatBuffers 的特性获得一定的好处。