【51CTO.com快译】Elasticsearch是一种非常强大的搜索和分析引擎,具有极强的扩展性。有了这个工具,您就有了可化视大量数据的基础。但当您开始扩展Elasticsearch以满足大数据的需求时,需要使用不止一台服务器。当开始扩展规模以满足企业需求时,单单一台服务器会因大量数据而被卡住。
所以,您该如何是好?可以部署一个Elasticsearch服务器集群。我会向您介绍如何做到这一点。部署完毕后,您就有必要的能力开始构建令人难以置信的数据可视化工具,能够处理大量数据。
您需要什么?
我将在Ubuntu Server 20.04的两个实例上演示这一点,但您可以根据需要将其部署到尽可能大的集群。除了Ubuntu Server的两个实例外,还需要一个拥有sudo权限的用户。就是这样。不妨部署吧。
如何安装 Java?
您至少需要在每台服务器上安装Java 8,因此我们将使用以下命令安装默认的JRE:
- sudo apt-get install default-jre -y
一旦我们在两台测试机器上都安装了它,就可以安装Elasticsearch了。
如何安装Elasticsearch?
这在两台机器上都需要完成。先安装Elasticsearch GPG密钥:
- wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
接下来,使用以下命令安装apt-transport-https:
- sudo apt-get install apt-transport-https
使用以下命令添加必要的存储库:
- echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tree -a /etc/apt/sources.list.d/elastic-6.x.list
最后,更新apt并安装Elasticsearch:
- sudo apt-get update
- sudo apt-get install elasticsearch -y
运行并启用Elasticsearch:
- sudo systemctl start elasticsearch
- sudo systemctl enable elasticsearch
如何配置Elasticsearch?
您将在两台服务器上执行此操作,务必要确保更改配置以适合每台机器。我们称第一台机器为controller-1、称第二台机器为node-1。使用以下命令打开配置文件:
- sudo nano /etc/elasticsearch/elasticsearch.yml
在该文件中,您需要编辑以下几行。其中一些行将被注释掉,因此您需要先删除前导的#字符。要编辑的几行是(粗体显示的内容都应根据需要加以编辑):
- cluster.name: elkcluster
- node.name: "controller-1"
- network.host: 192.168.1.80
- http.port: 9200
- discovery.zen.ping.unicast.hosts: ["192.168.1.80", "192.168.1.81"]
在本文例子中,控制器使用192.168.1.80,节点使用192.168.1.81。
保存并关闭文件。在两台机器上都重启Elasticsearch:
- sudo systemctl restart elasticsearch
如何测试集群?
您需要给Elasticsearch几分钟的时间来启动。可以使用以下命令来测试它:
- curl -XGET 'http://192.168.1.80:9200/_cluster/state?pretty'
确保根据您的控制器或节点来编辑上述的IP地址。如果您测试控制器,使用控制器IP;如果测试节点,就使用节点IP。
Elasticsearch最终运行后,您应该会看到许多输出结果,包括如下:
- {
- "cluster_name" : "monkeypantz",
- "cluster_uuid" : "rGzNNmm_Rteel0Xg3xqw9w",
- "version" : 6,
- "state_uuid" : "WVx5O6Q7SfOqZf_wxaPOKQ",
- "master_node" : "2NI9_pDYS1WvJYQz-XY3KQ",
- "blocks" : { },
- "nodes" : {
- "yV2TBoxVTvKbh7E1ZngpbA" : {
- "name" : "node-1",
- "ephemeral_id" : "pkb3vapLTd2yFLrXO64ENA",
- "transport_address" : "192.168.1.81:9300",
- "attributes" : {
- "ml.machine_memory" : "3137888256",
- "ml.max_open_jobs" : "20",
- "xpack.installed" : "true",
- "ml.enabled" : "true"
- }
- },
一旦控制器和节点都正常运行起来,使用以下命令测试集群:
- curl -XGET '192.168.1.80:9200/_cluster/health?pretty'
务必要编辑IP地址,以便与您运行命令所在的那台机器的IP地址相匹配。输出应包括如下:
- {
- "cluster_name" : "monkeypantz",
- "status" : "green",
- "timed_out" : false,
- "number_of_nodes" : 2,
- "number_of_data_nodes" : 2,
- "active_primary_shards" : 0,
- "active_shards" : 0,
- "relocating_shards" : 0,
- "initializing_shards" : 0,
- "unassigned_shards" : 0,
- "delayed_unassigned_shards" : 0,
- "number_of_pending_tasks" : 0,
- "number_of_in_flight_fetch" : 0,
- "task_max_waiting_in_queue_millis" : 0,
- "active_shards_percent_as_number" : 100.0
- }
要留意的重要行如下:
- "status" : "green",
- "timed_out" : false,
- "number_of_nodes" : 2,
- "number_of_data_nodes" : 2,
您还可以使用以下命令(在控制器上运行),从控制器来检查节点:
- curl -XGET '192.168.1.81:9200/_nodes/?pretty
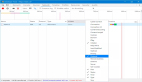
务必要把上述的IP地址换成Elasticsearch节点的IP地址。您还可以将浏览器指向http://SERVER:9200(其中Server是您控制器的IP地址),应该会看到类似图A的输出。
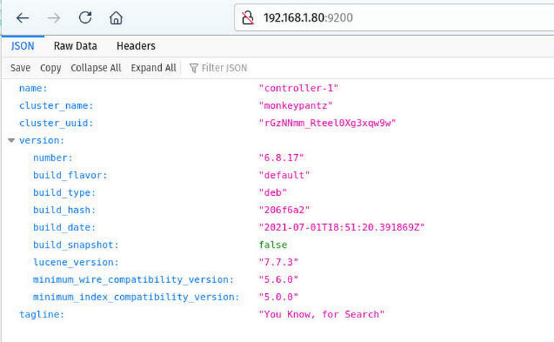
图A. Elasticsearch集群正常运行起来
恭喜,您现在有了正常运行起来的Elasticsearch集群,已准备好供您的开发人员用来可视化数据。
原文标题:How to deploy an Elasticsearch cluster on Ubuntu Server 20.04,作者:Jack Wallen
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】