【51CTO.com快译】深度神经网络(DNN)需要大量训练数据,即使微调模型也需要大量训练数据。那么您如何知道是否已用了足够的数据?如果是计算机视觉(CV)模型,您始终可以查看测试错误。但是如果微调BERT或GPT之类的大型transformer模型,又该如何?
- 评估模型的最佳度量指标是什么?
- 您如何确信已用足够的数据训练了模型?
- 您的客户如何确信?
WeightWatcher可助您一臂之力。
- pip install weightwatcher
WeightWatcher是一种开源诊断工具,用于评估(预)训练和微调的深度神经网络的性能。它基于研究深度学习为何有效的前沿成果。最近,它已在《自然》杂志上刊登。
本文介绍如何使用WeightWatcher来确定您的DNN模型是否用足够的数据加以训练。
我们在本文中考虑GPT vs GPT2这个例子。GPT是一种NLP Transformer模型,由OpenAI开发,用于生成假文本。最初开发时,OpenAI发布了GPT模型,该模型专门用小的数据集进行训练,因此无法生成假文本。后来,他们认识到假文本是个好生意,于是发布了GPT2,GPT2就像GPT 一样,但用足够的数据来加以训练,确保有用。
我们可以将WeightWatcher运用于GPT和GPT2,比较结果;我们将看到WeightWatcher log spectral norm和 alpha(幂律)这两个度量指标可以立即告诉我们GPT模型出了岔子。这在论文的图6中显示;
图 6
我们在这里将详细介绍如何针对WeightWatcher幂律(PL)alpha度量指标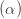 执行此操作,并解释如何解读这些图。
执行此操作,并解释如何解读这些图。
建议在Jupiter笔记本或Google Colab中运行这些计算。(作为参考,您还可以查看用于在论文中创建图解的实际笔记本,然而这里使用的是旧版本的WeightWatcher)。
出于本文需要,我们在WeightWatcher github代码存储库中提供了切实有效的笔记本。
WeightWatcher了解基本的Huggingface模型。的确,WeightWatcher支持以下:
- TF2.0/Keras
- pyTorch 1.x
- HuggingFace
- 很快会支持ONNX(当前主干中)
目前,我们支持Dense层和Conv2D层。即将支持更多层。针对我们的NLP Transformer模型,我们只需要支持Dense层。
首先,我们需要GPT和GPT2 pyTorch模型。我们将使用流行的HuggingFace transformers软件包。
- !pip install transformers
其次,我们需要导入pyTorch和weightwatcher
- Import torch
- Import weightwatcher as ww
我们还需要pandas库和matplotlib库来帮助我们解读weightwatcher度量指标。在Jupyter笔记本中,这看起来像:
- import pandas as pd
- import matplotlib
- import matplotlib.pyplot as plt
- %matplotlib inline
我们现在导入transformers软件包和2个模型类
- import transformers
- from transformers import OpenAIGPTModel,GPT2Model
我们要获取2个预训练的模型,并运行model.eval()
- gpt_model = OpenAIGPTModel.from_pretrained('openai-gpt')
- gpt_model.eval();
- gpt2_model = GPT2Model.from_pretrained('gpt2')
- gpt2_model.eval();
想使用WeightWatcher分析我们的GPT模型,只需创建一个watcher实例,然后运行 watcher.analyze()。这将返回的Pandas数据帧,附有每一层的度量指标。
- watcher = ww.WeightWatcher(model=gpt_model)
- gpt_details = watcher.analyze()
细节数据帧报告可用于分析模型性能的质量度量指标——无需访问测试数据或训练数据。最重要的度量指标是幂律度量指标 。WeightWatcher报告每一层 的
。WeightWatcher报告每一层 的 。GPT模型有近50层,因此将所有层 alpha作为直方图(使用pandas API)一次性检查显得很方便。
。GPT模型有近50层,因此将所有层 alpha作为直方图(使用pandas API)一次性检查显得很方便。
- gpt_details.alpha.plot.hist(bins=100, color='red', alpha=0.5, density=True, label='gpt')
- plt.xlabel(r"alpha $(\alpha)$ PL exponent")
- plt.legend()
这绘制了GPT模型中所有层的 值的密度。
值的密度。
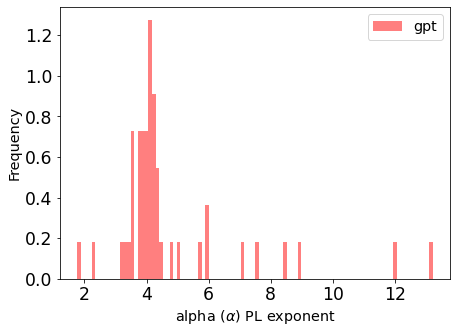
图2
从这个直方图中,我们可以立即看到模型的两个问题
•峰值 高于充分训练的模型的最佳值。
高于充分训练的模型的最佳值。
•有几个异常值是 ,表明几个层训练欠佳。
,表明几个层训练欠佳。
所以对GPT一无所知,也从未见过测试训练或训练数据,WeightWatcher告诉我们这个模型永远不该进入生产环境。
现在不妨看看GPT2,它有相同的架构,但使用更多更好的数据加以训练。我们再次使用指定的模型创建一个watcher实例,然后运行 watcher.analyze()
- watcher = ww.WeightWatcher(model=gpt2_model)
- gpt2_details = watcher.analyze()
现在不妨比较GPT和GPT2的幂律alpha度量指标。我们就创建2个直方图,每个模型1个直方图,并叠加这2个图。
- gpt_details.alpha.plot.hist(bins=100, color='red', alpha=0.5, density=True, label='gpt')
- gpt2_details.alpha.plot.hist(bins=100, color='green', density=True, label='gpt2')
- plt.xlabel(r"alpha $(\alpha)$ PL exponent")
- plt.legend()
GPT的层alpha显示红色,GPT2的层alpha显示绿色,直方图差异很大。对于GPT2,峰值$alpha\sim 3.5&bg=ffffff$,更重要的是没有异常值$latex \alpha>6&bg=ffffff$。Alpha越小越好,GPT2模型比GPT好得多,原因在于它用更多更好的数据加以训练。
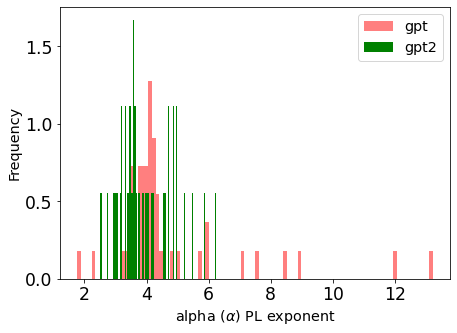
图3
WeightWatcher 有许多功能可以帮助您评估模型。它可以做这样的事情:
- 帮助您决定是否用足够的数据对其进行了训练(如图所示)
- 检测过度训练的潜在层
- 用于获取提前停止的标准(当您无法查看测试数据时)
- 针对不同的模型和超参数,预测测试精度方面的趋势
等等
不妨试一下。如果它对您有用,请告诉我。
原文标题:How to Tell if You Have Trained Your Model with Enough Data,作者:Charles Martin
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】