SQL优化是优化工作中经常会涉及的问题,由于早期的开发人员往往只关注于SQL功能的实现,而忽略了性能。特别是复杂的SQL,上线之后很少修改,一旦出现问题,即使是当初的开发人员自己也很难理清其中的业务逻辑,需要花费大量的时间去理解代码之间的关系,最终可能还是感觉无从下手。因此开发人员前期应做好代码注释,避免编写过于复杂的SQL语句。本文为大家介绍一些生产环境中真实的常用索引优化方法。
遇到问题SQL时,大家可以根据各自的习惯使用不同的工具(PL/SQL、TOAD等)对SQL进行格式化,我们需要重点关注的是FROM后面的表,以及包含WHERE语句的条件,然后通过awrsqrpt或dbms_xplan获取SQL的详细执行计划和资源消耗信息,业务案例中的SQL语句如下:
- SQL> select sum(cggzl) cggzl, sum(qbgzl) qbgzl
- from (select case
- when zlxm_mc like '%2ê3?3£1??ì2é%' then
- gzl
- else
- 0
- end cggzl,
- case
- when zlxm_mc like '%?3±í?÷1ù%' then
- gzl
- else
- 0
- end qbgzl
- from dictmanage.dict_zl_pro b,
- his.pat_inpat_order_info c,
- pat_inpat_order_cost d
- where d.sfxm_id = b.zlxm_id
- and c.yzjl_id = d.dyzy_yzjl_id
- and zlxm_mc like '%2???%'
- and c.yz_zxrq >= to_date(sysdate)
- and c.yz_zxrq < to_date(sysdate + 1)
- and d.fy_status in ('1', '2')
- and sfxm_je > 0
- and c.yz_zfrq is null
- and c.zylsh = :in_zylsh)
SQL的详细执行计划如图1所示。
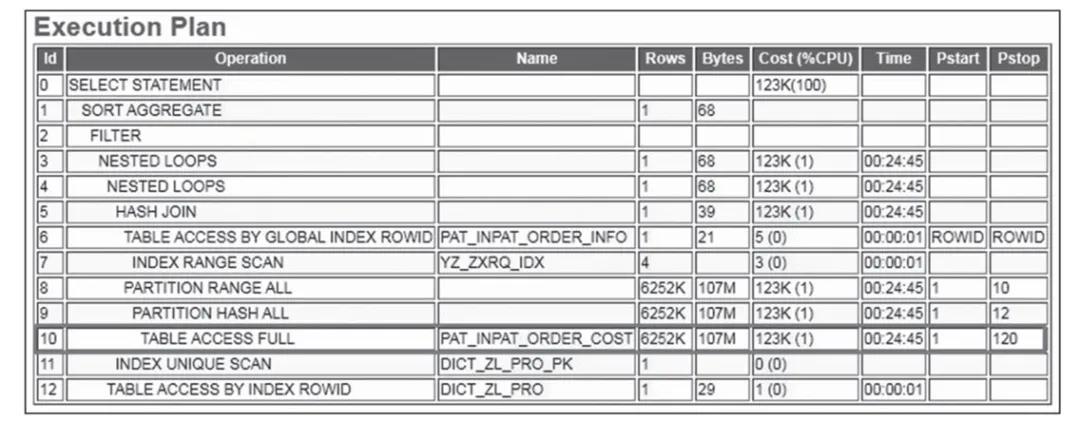
图1 SQL执行计划
AWR报告中的资源消耗信息如图2所示。
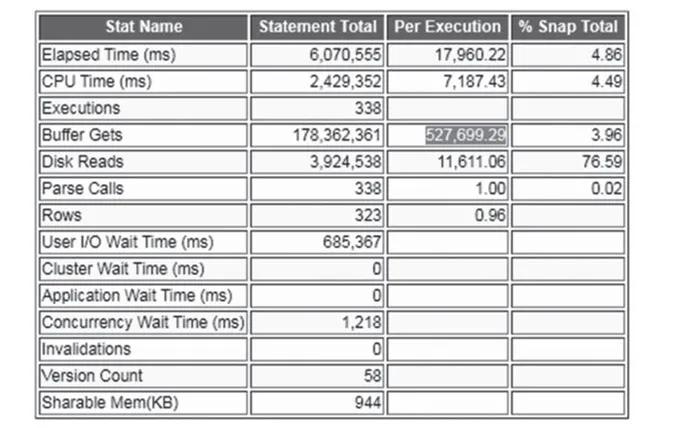
图2 AWR报告中的资源消耗信息
上述代码所示的业务SQL语句通过三张表进行关联,最终返回的行数为个位数,从执行计划中我们可以看出,Id=0,CBO计算总的COST为123K,其中绝大部分的COST是由Id=10的表pat_inpat_order_cost全表扫描所产生的。此时,我们需要重点关注 pat_inpat_order_cost与其他两张表格的关联情况,where条件中,pat_inpat_order_cost的sfxm_id和dyzy_yzjl_id除了与其他两张表的字段相关联之外,只有fy_status一个过滤条件,下面我们就来看下该列的选择性,代码如下:
- SQL> select /*+ NO_MERGE LEADING(a b) */
- b.owner,
- b.table_name,
- a.column_name,
- b.num_rows,
- a.num_distinct Cardinality,
- ROUND(A.num_distinct * 100 / B.num_rows, 1) selectivity
- from dba_tab_col_statistics a, dba_tables b
- where a.owner = b.owner
- and a.table_name = b.table_name
- and a.owner = upper('his')
- and a.table_name = upper('pat_inpat_order_cost')
- and a.column_name = upper('fy_status');
pat_inpat_order_cost表的字段信息如图3所示。

图3 pat_inpat_order_cost表的字段信息
- SQL> select count(*), FY_STATUS
- from his.pat_inpat_order_cost c
- group by FY_STATUS;
fy_status字段列的选择性如图4所示。

图4 fy_status字段列的选择性
由图4可知,fy_status的选择性并不好,而且存在严重倾斜,语句中的固定写法d.fy_status in ('1', '2')几乎包含了所有记录,因此其并不是一个很好的过滤条件。where条件中的大部分过滤条件均来自于C表pat_inpat_order_info,而且C表与D表pat_inpat_order_cost的sfxm_id字段相关联。
整个SQL语句最终返回的行数为个位数,C表通过YZ_ZXRQ_IDX索引范围扫描再回表进行过滤,获取绑定变量值,之后再进一步确认C表返回的行数,代码如下:
- SQL> select sql_Id, name, datatype_string, last_captured, value_string
- from v$sql_bind_capture
- where sql_id = '18rwad2bgcxfa';
SQL绑定变量值获取情况如图5所示。

图5 SQL绑定变量值获取情况
- SQL> select count(*)
- from his.pat_inpat_order_info c
- where c.yz_zxrq >= to_date(sysdate)
- and c.yz_zxrq < to_date(sysdate + 1)
- and c.yz_zfrq is null
- and c.zylsh = 72706;
带入绑定变量我们可以发现,这个查询返回的行数都保持在个位数,如果C表和D表采用嵌套连接的方式,C表能作为驱动表与D表pat_inpat_order_cost相关联,被驱动表只需要在关联列上创建索引,即可大幅提升整个查询的效率,做法其实很简单,只需要在sfxm_id字段上创建索引即可,命令如下:
- SQL> create index IDX_SFXM_ID on PAT_INPAT_ORDER_COST (SFXM_ID);
- Plan hash value: 408580053
- ------------------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ------------------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | | | 12 (100)| |
- | 1 | SORT AGGREGATE | | 1 | 68 | | |
- |* 2 | FILTER | | | | | |
- | 3 | NESTED LOOPS | | 1 | 68 | 12 (0)| 00:00:01 |
- | 4 | NESTED LOOPS | | 1 | 68 | 12 (0)| 00:00:01 |
- | 5 | NESTED LOOPS | | 1 | 39 | 11 (0)| 00:00:01 |
- |* 6 | TABLE ACCESS BY GLOBAL INDEX ROWID
- | PAT_INPAT_ORDER_INFO | 1 | 21 | 5 (0)| 00:00:01 |
- |* 7 | INDEX RANGE SCAN | YZ_ZXRQ_IDX | 4 | | 3 (0)| 00:00:01 |
- |* 8 | TABLE ACCESS BY GLOBAL INDEX ROWID
- | PAT_INPAT_ORDER_COST | 6 | 108 | 6 (0)| 00:00:01 |
- |* 9 | INDEX RANGE SCAN | IDX_DYZY_YZJL_ID | 6 | | 2 (0)| 00:00:01 |
- |* 10 | INDEX UNIQUE SCAN | DICT_ZL_PRO_PK | 1 | | 0 (0)| |
- |* 11 | TABLE ACCESS BY INDEX ROWID | DICT_ZL_PRO | 1 | 29 | 1 (0)| 00:00:01 |
- ------------------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter(TO_DATE(TO_CHAR(SYSDATE@!+1))>TO_DATE(TO_CHAR(SYSDATE@!)))
- 6 - filter(("C"."ZYLSH"=TO_NUMBER(:IN_ZYLSH) AND "C"."YZ_ZFRQ" IS NULL))
- 7 - access("C"."YZ_ZXRQ">=TO_DATE(TO_CHAR(SYSDATE@!)) AND "C"."YZ_ZXRQ"<TO_DATE(TO_CHAR
- (SYSDATE@!+1)))
- 8 - filter(("SFXM_JE">0 AND INTERNAL_FUNCTION("D"."FY_STATUS")))
- 9 - access("C"."YZJL_ID"="D"."DYZY_YZJL_ID")
- 10 - access("D"."SFXM_ID"="B"."ZLXM_ID")
- 11 - filter("ZLXM_MC" LIKE '%部位%')
创建索引之后,整个执行计划按照我们设想的方式进行,SQL执行时间也从原来的24分钟缩短到1秒,速度提升了上千倍。
上述案例介绍了一种最简单的SQL优化方式,在大多数情况下,我们很难让开发商修改应用,因此索引的优化在SQL优化工作中显得尤为重要。
本文摘编于《DBA攻坚指南:左手Oracle,右手MySQL》,经出版方授权发布。