












DeepMind 提出的 Rainbow 算法,可以让 AI 玩 Atari 游戏的水平提升一大截,但该算法计算成本非常高,一个主要原因是学术研究发布的标准通常是需要在大型基准测试上评估新算法。来自谷歌的研究者通过添加和移除不同组件,在有限的计算预算、中小型环境下,以小规模实验得到与 Rainbow 算法一致的结果。
人们普遍认为,将传统强化学习与深度神经网络结合的深度强化学习,始于 DQN 算法的开创性发布。DQN 的论文展示了这种组合的巨大潜力,表明它可以产生玩 Atari 2600 游戏的有效智能体。之后有多种方法改进了原始 DQN,而 Rainbow 算法结合了许多最新进展,在 ALE 基准测试上实现了 SOTA 的性能。然而这一进展带来了非常高的计算成本,拥有充足计算资源的和没有计算资源之间的差距被进一步拉大。
在 ICML 2021 的一篇论文《Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research》中,研究者首先讨论了与 Rainbow 算法相关的计算成本。研究者探讨了通过结合多种算法组件,以小规模实验得到与 Rainbow 算法一致的结果,并将该想法进一步推广到在较小的计算预算上进行的研究如何提供有价值的科学见解。

论文地址:https://arxiv.org/abs/2011.14826
Rainbow 计算成本高的一个主要原因是学术研究发布的标准通常是需要在大型基准测试(例如 ALE,其中包含 57 款强化学习智能体能够学会玩 Atari 2600 游戏)上评估新算法。通常使用 Tesla P100 GPU 训练模型学会玩一个游戏大约需要五天时间。此外,如果想要建立有意义的置信边界,通常至少执行 5 次运行。
因此,在全套 57 款游戏上训练 Rainbow 需要大约 34,200 个 GPU hour(约 1425 天)才能提供令人信服的性能实验数据。这样的实验只有能够在多个 GPU 上并行训练时才可行,这使得较小的研究小组望而却步。
Rainbow 算法
与原始 Rainbow 算法的论文一样,在 ICML 2021 的这篇论文中,研究者评估了在原始 DQN 算法中添加以下组件的效果:双 Q 学习(double Q-learning)、优先经验回放(prioritized experience replay,PER)、竞争网络、多步学习、分布式强化学习和嘈杂网络。
该研究在四个经典控制环境中进行评估。需要注意的是,相比于 ALE 游戏需要 5 天,这些环境在 10-20 分钟内就可以完成完全训练:
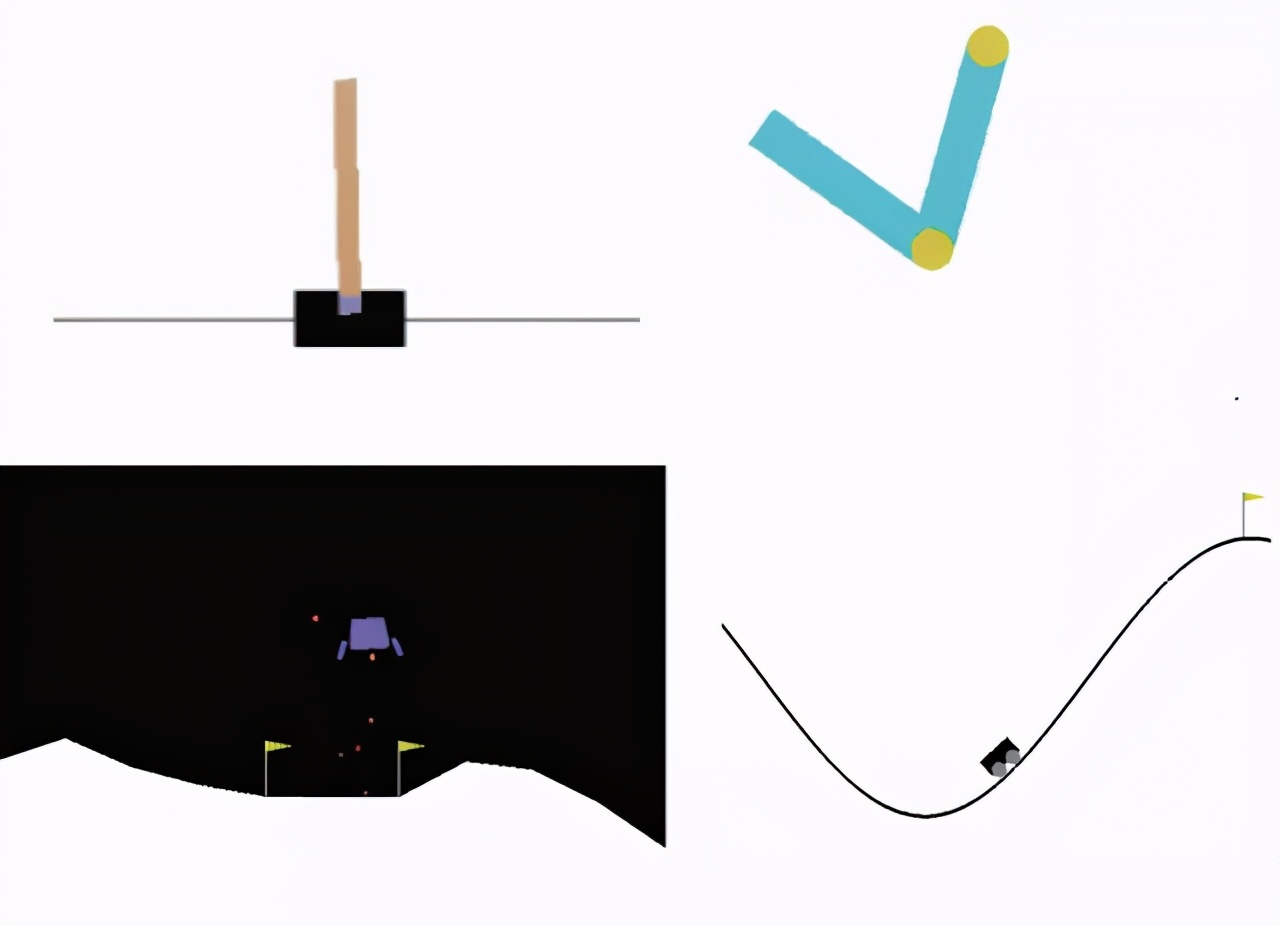
左上:在 CartPole 中,游戏任务是智能体通过左右移动平衡推车上的一根杆子;右上:在 Acrobot 中,有两个杠杆和两个连接点,智能体需要向两个杠杆之间的连接点施加力以抬高下面的杠杆使其高于某个高度要求。左下:在 LunarLander 中,智能体的任务是将飞船降落在两个旗帜之间;右下:在 MountainCar 中,智能体需要在两座山丘之间借助一定的动力将车开到右边的山顶。
研究者探究了将每个组件单独添加到 DQN 以及从完整 Rainbow 算法中删除每个组件的效果,并发现总的来说每一个算法组件的添加都确实改进了基础 DQN 的学习效果。然而,该研究也发现了一些重要的差异,例如通常被认为能起到改进作用的分布式 RL 自身并不总是能够产生改进。实际上,与 Rainbow 论文中的 ALE 结果相反,在经典控制环境中,分布式 RL 仅在与其他组件结合时才会产生改进。
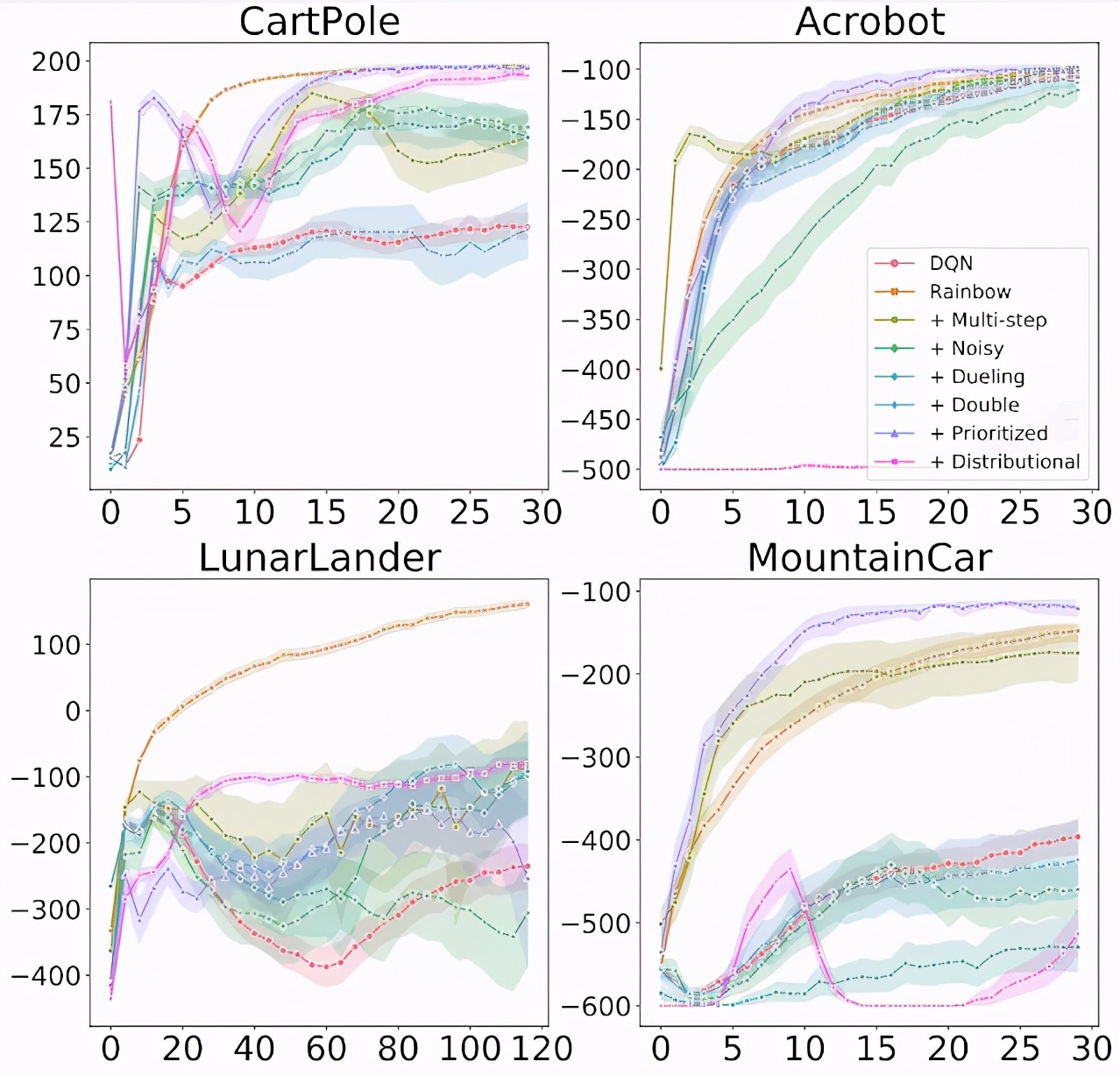
上图显示了在 4 个经典控制环境中,向 DQN 添加不同组件时的训练进度。x 轴为训练 step,y 轴为性能(越高越好)。
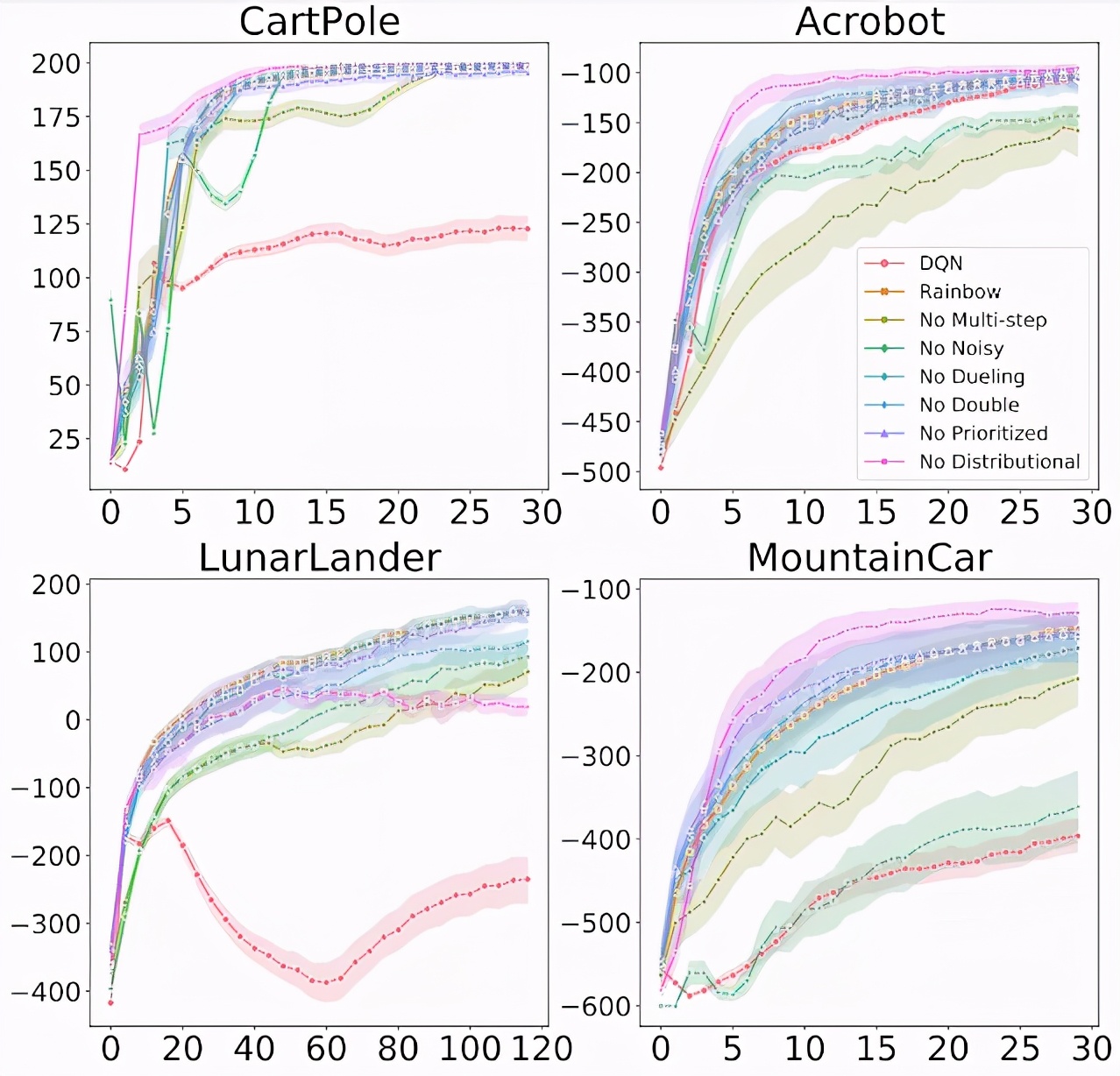
上图显示了在 4 个经典控制环境中,从 Rainbow 中移除各种组件时的训练进度。x 轴为训练 step,y 轴为性能(越高越好)。
研究者还在 MinAtar 环境中重新运行了 Rainbow 实验,MinAtar 环境由一组五个小型化的 Atari 游戏组成,实验结果与原 Rainbow 论文类似。MinAtar 游戏的训练速度大约是常规 Atari 2600 游戏的 10 倍,其中后者的训练速度是在最初的 Rainbow 算法上评估的。此外,该研究的实验结果还有一些有趣的方面,例如游戏动态和给智能体添加基于像素的输入。因此,该研究提供了一个具有挑战性的中级环境,介于经典控制和完整的 Atari 2600 游戏之间。
综合来看,研究者发现现在的结果与原始 Rainbow 论文的结果一致——每个算法组件产生的影响可能因环境而异。研究者建议使用单一智能体来平衡不同算法组件之间的权衡,该研究的 Rainbow 版本可能与原始版本高度一致,这是因为将所有组件组合在一起会产生整体性能更好的智能体。然而,在不同算法组件之间,有一些重要的细节变化值得进行更彻底的探究。
「优化器 - 损失函数」不同组合实验
DQN 被提出时,同时采用了 Huber 损失和 RMSProp 优化器。对于研究者而言,在构建 DQN 时使用相同的选择是一种常见的做法,因为研究者将大部分时间用在了其他算法设计上。
而该研究重新讨论了 DQN 在低成本、小规模经典控制和 MinAtar 环境中使用的损失函数和优化器。研究者使用 Adam 优化器进行了一些初始实验,目前 Adam 优化器是最流行的优化器,并在实验中结合使用了一个更简单的损失函数,即均方误差损失 (MSE)。由于在开发新算法时,优化器和损失函数的选择往往被忽略,而该研究发现在所有的经典控制和 MinAtar 环境中,这二者的改变都能让实验结果有显著的改进。
因此,研究者将两个优化器(RMSProp、Adam 优化器)与两个损失函数(Huber、MSE 损失)进行了不同的组合,并在整个 ALE 平台(包含 60 款 Atari 2600 游戏)上进行了评估。结果发现 Adam+MSE 组合优于 RMSProp+Huber 组合。
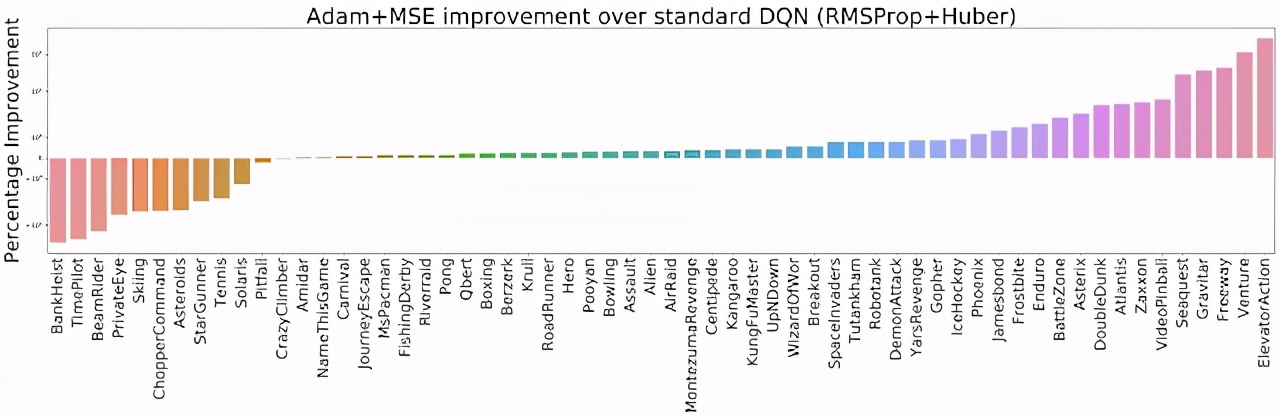
在默认 DQN 设置下(RMSProp + Huber),评估 Adam+MSE 组合带来的改进(越高越好)。
此外,在比较各种「优化器 - 损失函数」组合的过程中,研究者发现当使用 RMSProp 时,Huber 损失往往比 MSE 表现得更好(实线和橙色虚线之间的间隙可以说明这一点)。
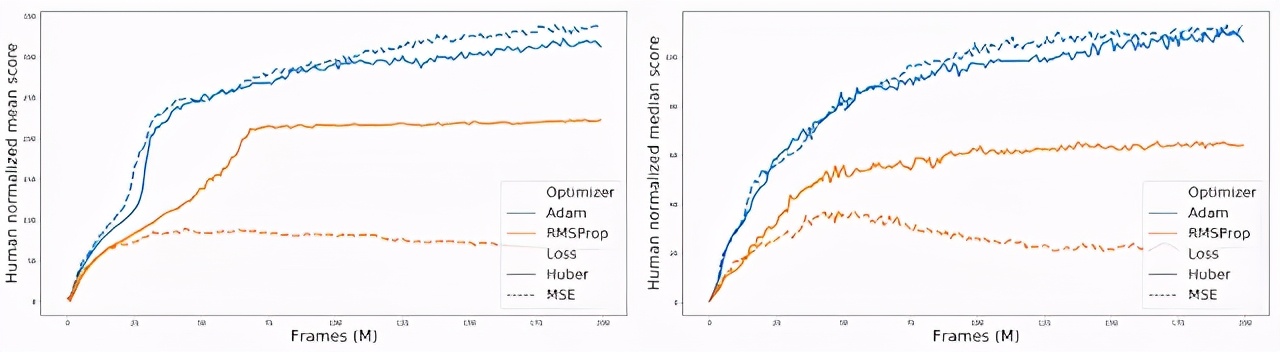
对 60 款 Atari 2600 游戏的标准化得分进行汇总,比较不同的「优化器 - 损失函数」组合。
在有限的计算预算下,该研究研究者能够在高层次上复现论文《Rainbow: Combining Improvements in Deep Reinforcement Learning》的研究,并且发现新的、有趣的现象。显然,重新审视某事物比首次发现更容易。然而,研究者开展这项工作的目的是为了论证中小型环境实证研究的相关性和重要性。研究者相信,这些计算强度较低的环境能够很好地对新算法的性能、行为和复杂性进行更关键和彻底的分析。该研究希望 AI 研究人员能够把小规模环境作为一种有价值的工具,评审人员也要避免忽视那些专注于小规模环境的实验工作。















