摘要:本文整理自戴尔科技集团软件工程师周煜敏在 Flink Forward Asia 2020 分享的议题《Pravega Flink Connector 的过去、现在和未来》,文章内容为:
- Pravega 以及 Pravega connector 简介
- Pravega connector 的过去
- 回顾 Flink 1.11 高阶特性心得分享
- 未来展望
一、Pravega 以及 Pravega connector 简介

Pravega 项目的名字来源于梵语,意思是 good speed。项目起源于 2016 年,基于 Apache V2 协议在 Github 上开源,并且于 2020 年 11 月加入了 CNCF 的大家庭,成为了 CNCF 的 sandbox 项目。
Pravega 项目是为大规模数据流场景而设计的,弥补传统消息队列存储短板的一个新的企业级存储系统。它在保持对于流的无边界、高性能的读写上,也增加了企业级的一些特性:例如弹性伸缩以及分层存储,可以帮助企业用户降低使用和维护的成本。同时我们也在存储领域有着多年的技术沉淀,可以依托公司商用存储产品为客户提供持久化的存储。
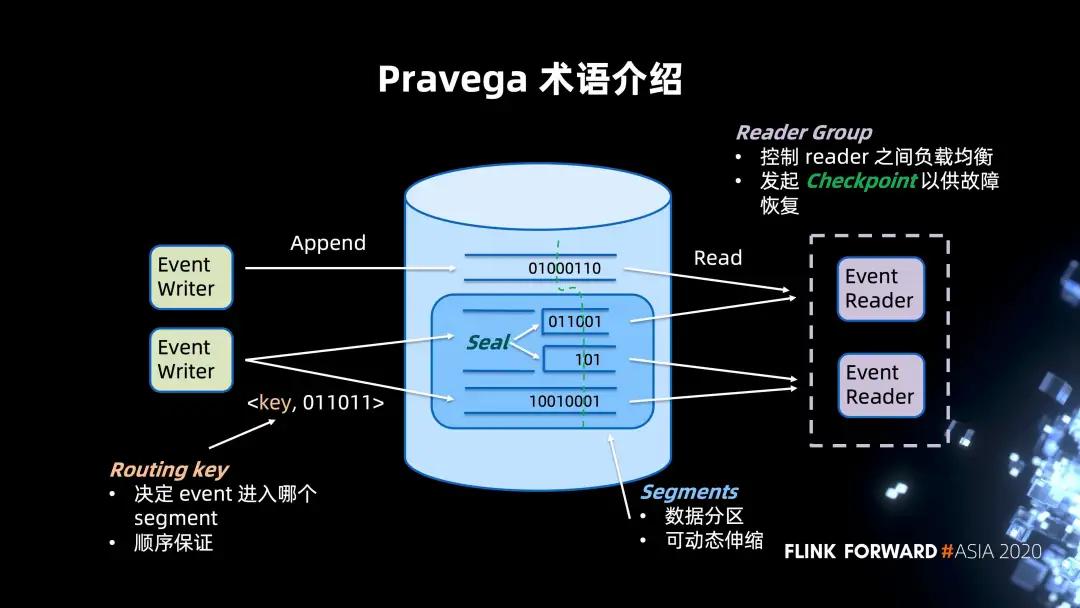
以上的架构图描述的是 Pravega 典型的读写场景,借此进行 Pravega 术语介绍以帮助大家进一步了解系统架构。
- 中间部分是一个 Pravega 的集群 ,它整体是以 stream 抽象的系统。stream 可以认为是类比 Kafka 的 topic。同样,Pravega 的 Segment 可以类比 Kafka 的 Partition,作为数据分区的概念,同时提供动态伸缩的功能。
Segment 存储二进制数据数据流,并且根据数据流量的大小,发生 merge 或者 split 的操作,以释放或者集中资源。此时 Segment 会进行 seal 操作禁止新数据写入,然后由新建的 Segment 进行新数据的接收。
- 图片左侧是数据写入的场景,支持 append only 的写入。用户可以对于每一个 event 指定 Routing key 来决定 Segment 的归属。这一点可以类比 Kafka Partitioner。单一的 Routing key 上的数据具有保序性,确保读出的顺序与写入相同。
- 图片右侧是数据读取的场景,多个 reader 会有一个 Reader Group 进行管控。Reader Group 控制着 reader 之间的负载均衡的,来保证所有的 Segment 能在 reader 之间均匀分布。同时也提供 Checkpoint 机制形成一致的 stream 切分来保证数据的故障恢复。对于 "读",我们支持批和流两种语义。对于流的场景,我们支持尾读;对于批的场景,我们会更多的考虑高并发来达到高吞吐。
二、Pravega Flink connector 的过去
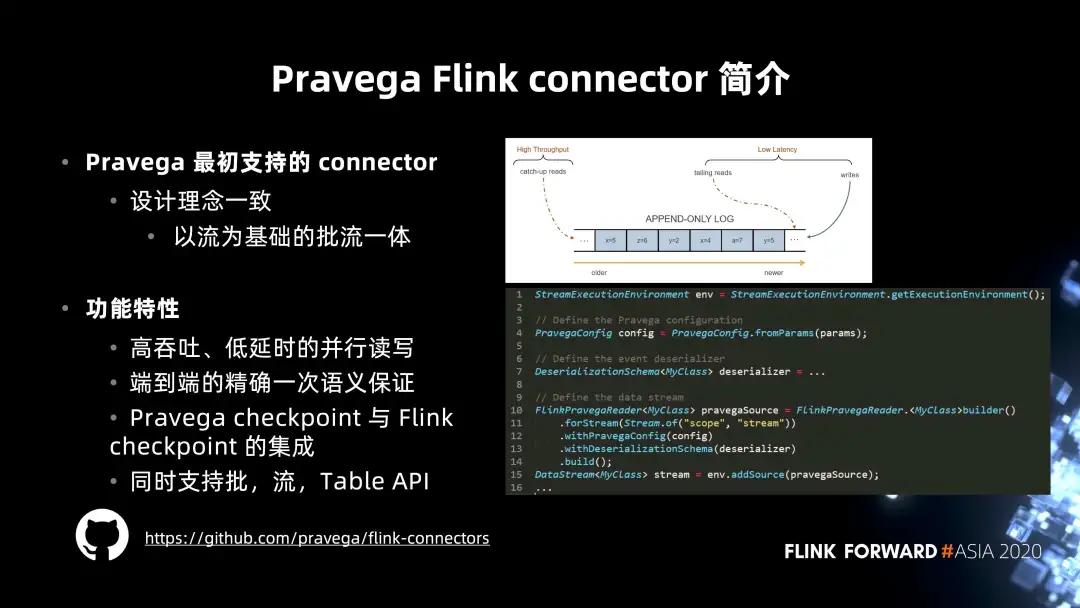
Pravega Flink connector 是 Pravega 最初支持的 connector,这也是因为 Pravega 与 Flink 的设计理念非常一致,都是以流为基础的批流一体的系统,能够组成存储加计算的完整解决方案。
1. Pravega 发展历程
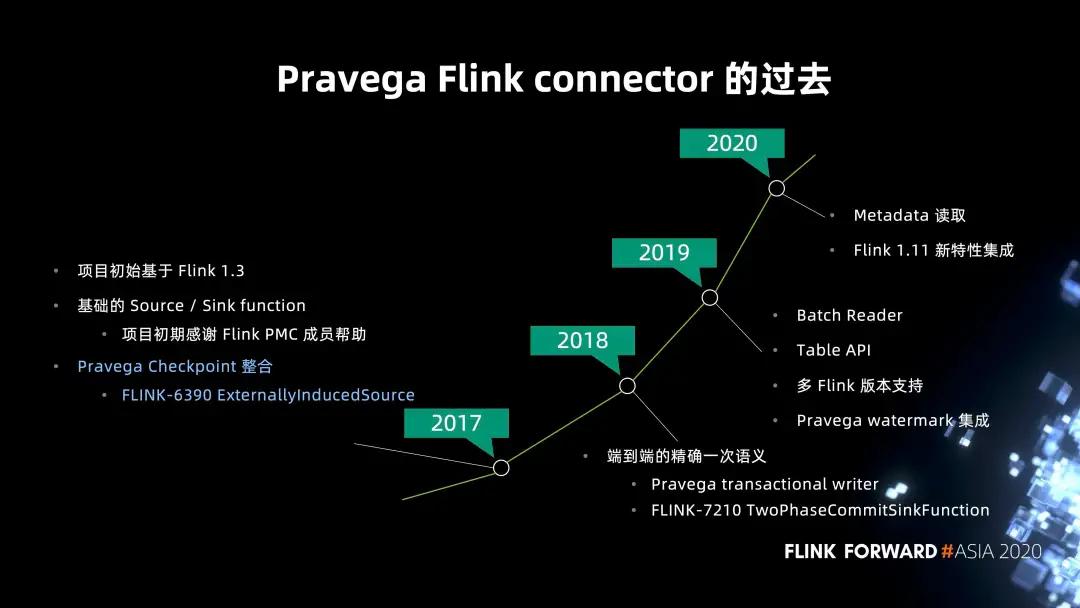
- connector 从 2017 年开始成为独立的 Github 项目。2017 年,我们基于 Flink 1.3 版本进行开发,当时有包括 Stephan Ewen 在内的 Flink PMC 成员加入,合作构建了最基础的 Source / Sink function,支持最基础的读写,同时也包括 Pravega Checkpoint 的集成,这点会在后面进行介绍。
- 2018 年最重要的一个亮点功能就是端到端的精确一次性语义支持。当时团队和 Flink 社区有非常多的讨论,Pravega 首先支持了事务性写客户端的特性,社区在此基础上合作,以 Sink function 为基础,通过一套两阶段提交的语义实现了基于 checkpoint 的分布式事务功能。后来,Flink 也进一步抽象出了两阶段提交的 API,也就是为大家熟知的 TwoPhaseCommitSinkFunction 接口,并且也被 Kafka connector 采用。社区有博客来专门介绍这一接口,以及端到端的一次性语义。
- 2019 年更多的是 connector 对其它 API 的一些补完,包括对批的读取以及 Table API 都有了支持。
- 2020 年的主要关注点是对 Flink 1.11 的集成,其中的重点是 FLIP-27 以及 FLIP-95 的新特性集成。
2. Checkpoint 集成实现
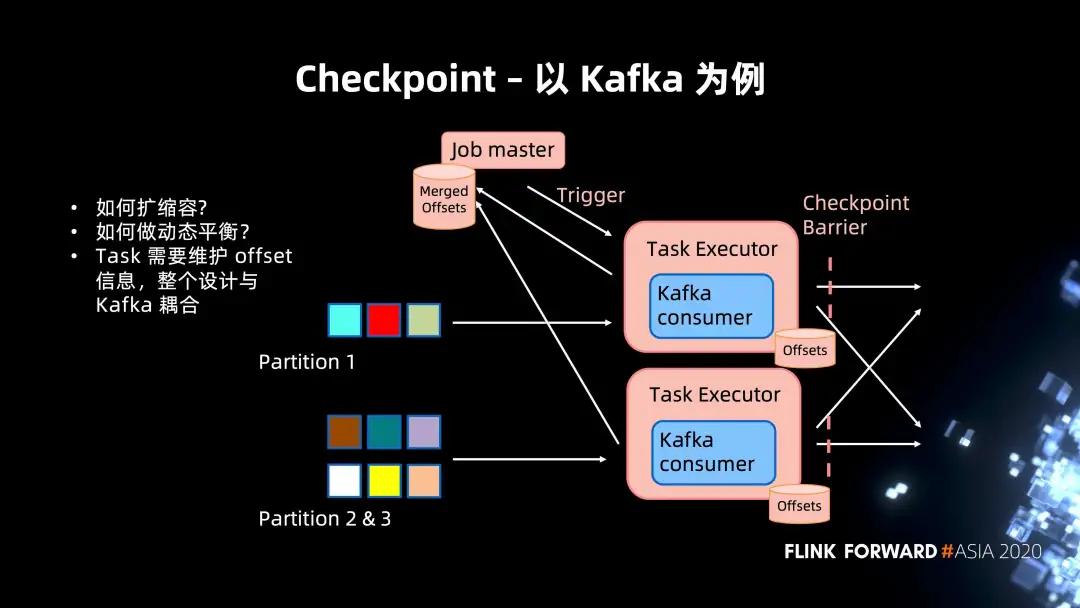
以 Kafka 为例,可以首先来看一下 Kafka 是如何做到 Flink Checkpoint 的集成的。
上图所示是一个典型的 Kafka "读" 的架构。基于 Chandy-Lamport 算法的 Flink checkpoint 实现,当 Job master Trigger 一个 Checkpoint 时,会往 Task Executor 发送 RPC 请求。其接收到之后会把自身状态存储中的 Kafka commit offset 合并回 Job Manager 形成一个 Checkpoint Metadata。
仔细思考后,其实可以发现其中的一些小问题:
- 扩缩容以及动态的平衡支持。当 Partition 进行调整的时候,或者说对 Pravega 而言,在 Partition 动态扩容和缩容的时候,如何进行 Merge 一致性的保证。
- 还有一点就是 Task 需要维护一个 offset 的信息,整个设计会与 Kafka 的内部抽象 offset 耦合。
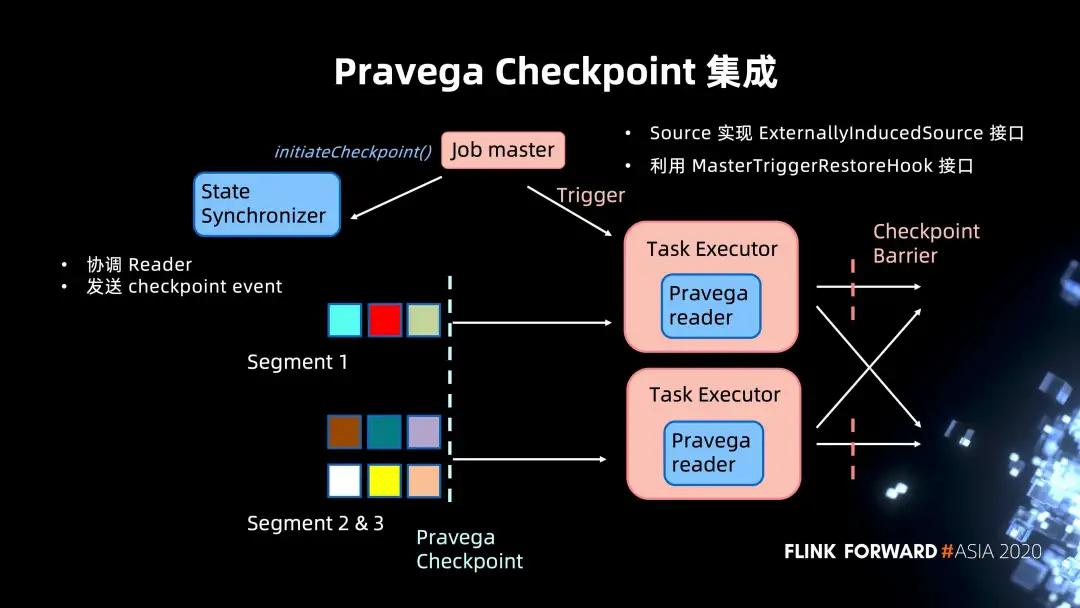
基于这些不足之处,Pravega 有自己内部设计的 Checkpoint 机制,我们来看一下它是怎么和 Flink 的 Checkpoint 进行集成的。
同样读取 Pravega Stream。开始 Checkpoint 这里就有不同,Job master 不再向 Task Executor 发送 RPC 请求,转而以 ExternallyInducedSource 的接口,向 Pravega 发送一个 Checkpoint 的请求。
同时,Pravega 内部会利用 StateSynchronizer 组件来同步和协调所有的 reader,并且会在所有的 reader 之间,发送 Checkpoint 的 event。当 Task Executor 读到 Checkpoint Event 之后,整个 Pravega 会标志着这个 Checkpoint 完成,然后返回的 Pravega Checkpoint 会存到 Job master state 当中,从而完成 Checkpoint。
这样的实现其实对于 Flink 来说是更干净的,因为它没有耦合外部系统的实现细节,整个 Checkpoint 的工作是交给 Pravega 来实现并完成的。
三、回顾 Flink 1.11 高阶特性心得分享
Flink1.11 是 2020 年的一个重要发布版本,对 connector 而言其实也有非常多的挑战,主要集中在两个 FLIP 的实现:FLIP-27 以及 FLIP-95。对于这两个全新功能,团队也花了很多时间去集成,在过程中也遇到了一些问题和挑战。下面我们来向大家分享一下我们是如何踩坑和填坑的。本文会以 FLIP-95 为例展开。
1. FLIP-95 集成

FLIP-95 是新的 Table API,其动机和 FLIP-27 类似,也是为了实现批流一体的接口,同时也能更好地支持 CDC 的集成。针对冗长的配置键,也提出了相应的 FLIP-122 来简化配置键的设定。
- 1.1 Pravega 旧的 Table API

从上图可以看到 Pravega 在 Flink 1.10 之前的一个 Table API,并且从图中建表的 DDL 可以看到:
- 以 update mode 和 append 去进行区分批和流,而且批流的数据这样的区分并不直观。
- 配置件也非常的冗长和复杂,读取的 Stream 需要通过 connector.reader.stream-info.0 这样非常长的配置键来配置。
- 在代码层面,和 DataStream API 也有非常多的耦合难以维护。
针对这些问题,我们也就有了非常大的动力去实现这样一套新的 API,让用户更好的去使用表的抽象。整个框架如图所示,借由整个新框架的帮助,所有的配置项通过 ConfigOption 接口定义,并且都集中在 PravegaOptions 类管理。

- 1.2 Pravega 全新 Table API
下图是最新 Table API 建表的实现,和之前的相比有非常大的简化,同时在功能上也有了不少优化,例如企业级安全选项的配置,多 stream 以及起始 streamcut 的指定功能。

2. Flink-18641 解决过程心得分享

接下来,我想在此分享 Flink 1.11 集成的一个小的心得,是关于一个 issue 解决过程的分享。Flink-18641 是我们在集成 1.11.0 版本时碰到的问题。升级的过程中,在单元测试中会报 CheckpointException。接下来是我们完整的 debug 过程。
- 首先会自己去逐步断点调试,通过查看 error 的报错日志,分析相关的 Pravega 以及 Flink 的源码,确定它是 Flink CheckpointCoordinator 相关的一些问题;
- 然后我们也查看了社区的一些提交记录,发现 Flink 1.10 之后, CheckpointCoordinator 线程模型,由原来锁控制的模型变成了 Mailbox 模型。这个模型导致了我们原来同步串型化执行的一些逻辑,错误的被并行化运行了,于是导致该错误;
- 进一步看了这一个改动的 pull request,也通过邮件和相关的一些 Committer 取得了联系。最后在 dev 邮件列表上确认问题,并且开了这个 JIRA ticket。
我们也总结了以下一些注意事项给到在做开源社区的同胞们:
- 在邮件列表和 JIRA 中搜索是否有其他人已经提出了类似问题;
- 完整的描述问题,提供详细的版本信息,报错日志和重现步骤;
- 得到社区成员反馈之后,可以进一步会议沟通商讨解决方案;
- 在非中文环境需要使用英语。
其实作为中国的开发人员,有除了像 mailing list 和 JIRA 之外。我们也有钉钉群以及视频的方式可以联系到非常多的 Committer。其实更多的就是一个交流的过程,做开源就是要和社区多交流,可以促进项目之间的共同成长。
四、未来展望
- 在未来比较大的工作就是 Pravega schema registry 集成。Pravega schema registry 提供了对 Pravega stream 的元数据的管理,包括数据 schema 以及序列化方式,并进行存储。这个功能伴随着 Pravega 0.8 版本发布了该项目的第一个开源版本。我们将在之后的 0.10 版本中基于这一项目实现 Pravega 的Catalog,使得 Flink table API 的使用更加简单;
- 其次,我们也时刻关注 Flink 社区的新动向,对于社区的新版本、新功能也会积极集成,目前的计划包括 FLIP-143 和 FLIP-129;
- 社区也在逐步完成基于 docker 容器的新的 Test Framework 的转换,我们也在关注并进行集成。
最后也希望社区的小伙伴可以多多的关注 Pravega 项目,促进 Pravega connector 与 Flink 的共同发展。