













要精通一门语言,熟悉其内容分配和使用机制很重要。对于编译型语言比如C,C++,内存的使用完全由程序员自己代码分配和管理,所以对C,C++程序员内存机制非常熟悉。但是对于动态语言,比如Python,内存在语言层自动管理,所以程序员无需关注太多细节,但是如果要想自己写的代码高效可靠,则也必须了解语言的内存机制。本文虫虫给大家介绍Python语言的内存机制,以及如何对其内存进行度量。

概述
考虑以下代码:
- import numpy as np
- cc= np.ones((1024, 1024, 1024, 3), dtype=np.uint8)
该代码将会创建一个3GB字节的数组,并且都用1来填充。同学们,可能会这样预想运行该代码后,进程将会自动分配3GB的内存用来使用,事实是不是如此呢?
测量内存的一种方法是使用“常驻内存”,在Python中可以使用psutil库工具获取方便的这些信息,检查当前进程的常驻内存:
- import psutil
- psutil.Process().memory_info().rss /(1024 * 1024)
- 3093
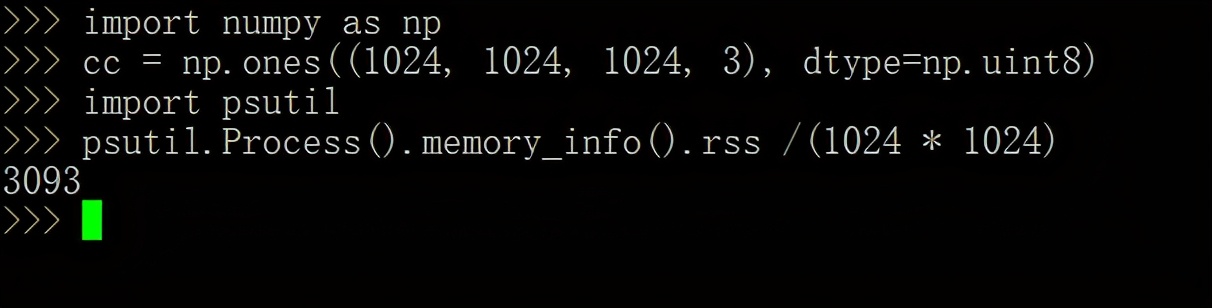
在该示例中,进程使用了3093MB或3.09GB,与数组大小的无区别,和预想的一样。
但是常驻内存实际上没那么简单。假设在机器上运行一些耗内存的任务。然后切换回解释器,再次运行完全相同的命令:
- psutil.Process().memory_info().rss / (1024 * 1024)
- 2903.12109375
这是怎么回事? 内存少了200MB。
为了解释这个现象,需要了解操作系统如何内存管理机制。
简化模型
当前正运行的程序都会分配一些内存,即从操作系统取回虚拟内存中的地址。 虚拟内存是一个特定于进程的地址空间,本质上是来自0至264-1,进程可以读取或写入字节。
在C语言中,程序员可以使用malloc()或者mmap()函数进行手动内存分配;而在Python中,我们只需创建对象,Python 解释器将在底层自动调用malloc()或者mmap()。然后该进程可以读取或写入该特定地址和连续字节。
Linux下可以用ltrace工具跟踪调用malloc(),运行下面Python代码:
- import numpy as np
- cc = np.ones((170_000,), dtype=np.uint8)
然后可以运行ltrace:
- ltrace -e malloc python ones.py
- ...
- _multiarray_umath.cpython-39-x86_64-linux-gnu.so->malloc(170000) = 0x5638862a45e0
- ...
整个过程Python 创建一个NumPy数组。
在Python引擎NumPy调用malloc()。
这样做的结果malloc()是内存中的地址:0x5638862a45e0。
然后,用于实现NumPy的C代码可以读取和写入该地址和下一个连续的169,999 个地址,每个地址代表虚拟内存中的一个字节。
这 170,000个字节存储在哪里?
它们可以存储在RAM中;这是默认设置。
它们可以存储在计算机的硬盘驱动器或磁盘上,即swap分区交换中。
一些字节可能存储在 RAM 中,一些字节可能存储在交换分区中。
常驻内存
RAM很快,而硬盘IO很慢,但RAM很贵。通常电脑硬盘驱动器空间比RAM多得多。例如,目前主流的计算机都会有2T左右的硬盘存储空间,但只会16GB的RAM。
理想情况下,程序的所有内存都将存储在内存RAM中,但计算机上运行的各种进程可能分配的内存比RAM中可用的内存多。如果发生这种情况,操作系统会将一些数据从RAM移动或“交换”到硬盘驱动器。必要时,从交换分区中获取数据,并将未积极使用的数据置换进去。
现在我们准备定义我们的第一个内存使用量度:常驻内存。常驻内存是进程分配的内存中有多少常驻或存储在RAM中。

在第一个示例中,首先将所有3GB的已分配数组存储在RAM中。
然后,当运行一些任务时,加载这些任务需要分配很多RAM,因此操作系统会将一些数据从RAM交换到磁盘交换分区。结果,Python进程的常驻内存下降了:所有数据仍然可以访问,但其中一些已移至磁盘交换分区。

分配内存
测量分配内存会很有用,无论操作系统是将数据放在RAM中还是将其交换到磁盘,总是3GB内存,程序实际需要多少内存。
在 Python 中(如果使用的是Linux 或macOS),可以使用Fil memory profiler测量分配的内存,它专门测量峰值分配的内存。对于之前的示例:
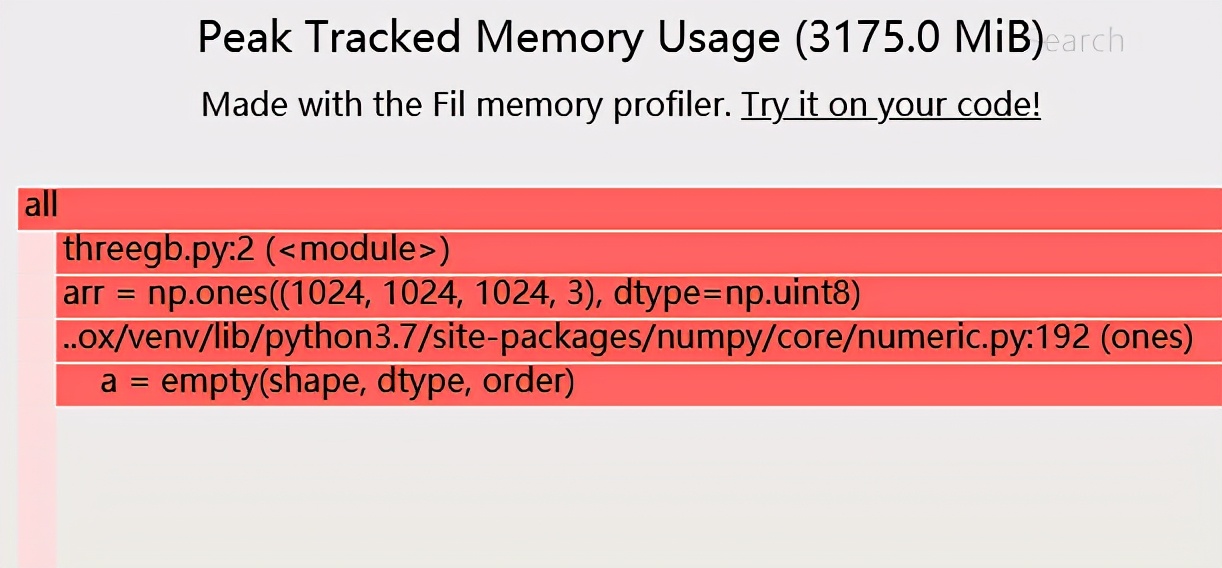
常驻内存和分配内存之间的权衡
常驻内存存在一些问题:
- 内存的使用和测量会受到其他进程的影响,由于其他进程可能会争抢常驻内存导致使用的实际使用的RAM会变化。
- 常驻内存的上限是可用的物理RAM,所以一旦达到上限,就永远不会真正了解程序要求多少内存。比如主机物理内存16GB,对需要17GB内存的程序和需要30GB 内存的程序,它们驻留内存的量都将一致,都将是16GB。
- 另一方面,分配的内存不受其他进程的影响,并告诉程序实际请求的内容。
当然,常驻内存确实比分配内存的优势:
- 交换的内存很可能永远不会被使用:想象一下创建一个数组,忘记删除引用,然后在程序的其余部分不再实际使用它。
- 更广泛地说,由于驻留内存从操作系统的角度衡量实际使用的内存,因此它可以捕获对分配的内存跟踪不可见的边缘情况。
让我们看一个这样的边缘情况的例子。
总结
到目前为止示例中,我们一直在分配充满1的数组。如果测量已分配的内存,则数组填充的内容没有区别:可以切换到创建充满零的数组,并且仍然得到完全相同的结果。
但是在Linux 上,再看一个例子:
- import numpy as np
- import psutil
- arr = np.zeros((1024, 1024, 1024, 3), dtype=np.uint8)
- psutil.Process().memory_info().rss/(1024 * 1024)
- 28.5546875
这次,还是分配了一个3GB的数组,但是给数组的元素都是零。然后测量常驻内存——数组并没有被计算到,常驻内存只有29M。数组占用的内存呢?
事实证明,Linux 不会费心将所有这些零存储在RAM中。而只是在实际访问数据时向RAM添加零块,并不会实际分配内存。
最后,需要提及的是,我们在说的内存使用模型也是理想状态的。还没有包括文件缓存、分配器中的内存碎片或其他可用指标等。
话虽如此,对于许多应用程序来说,分配的内存可能足以作为帮助优化程序内存使用的必要措施。



















