Hello,大家好。我叫“小屁孩i”。
前言
不知道大伙有没有看到过这一句话:“中国(疫苗研发)非常困难,因为在中国我们没有办法做第三期临床试验,因为没有病人了。”这句话是中国工程院院士钟南山在上海科技大学2021届毕业典礼上提出的。这句话在全网流传,被广大网友称之为“凡尔赛”发言。
今天让我们用数据来看看这句话是不是“凡尔赛”本赛。在开始之前我们先来说说今天要用到的python库吧!
1.数据获取部分
- requests lxml json openpyxl
2.数据可视化部分
- pandas pyecharts(可视化库)
以上的库都可以通过在线下载:
- pip instll xx
ps:如果下载速度太慢的话也可以用国内镜像,使用命令,例如:
- pip install xx(库名) -i https://pypi.tuna.tsinghua.edu.cn/simple gevent(清华镜像)
现在一起进入今天的代码部分吧!!!
数据获取
目标地址:
https://voice.baidu.com/act/newpneumonia/newpneumonia
进入目标地址我们可以看到如下所示:
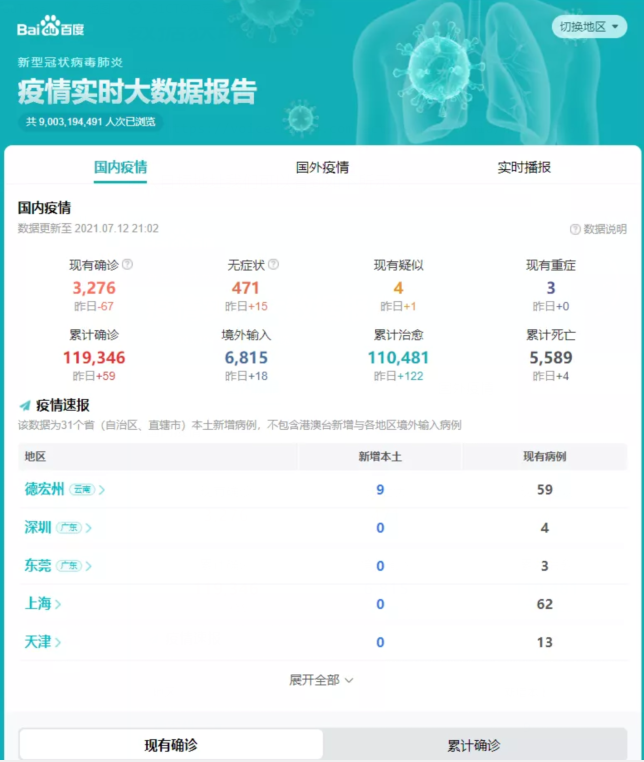
现在让我们一起去解析网页结构找到我们要爬取到的数据如下所示:
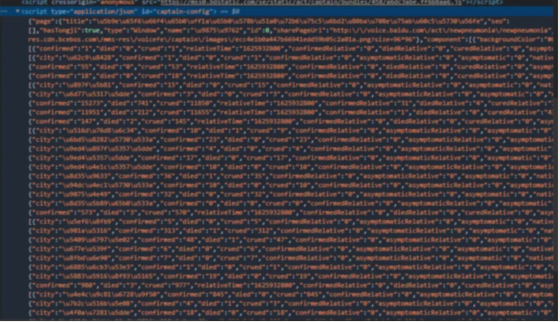
现在我们找到想要的页面数据接下来就是通过Python来获取这些数据了,上代码:
- import requests
- from lxml import etree
- import json
- import openpyxl
- #通用爬虫
- url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia'
- headers = {
- "User-Agent": ".....(换成自己的)"
- }
- response = requests.get(url=url,headers=headers).text
- #在使用xpath的时候要用树形态
- html = etree.HTML(response)
- #用xpath来获取我们之前找到的页面json数据 并打印看看
- json_text = html.xpath('//script[@type="application/json"]/text()')
- json_text = json_text[0]
- # print(json_text)
之后我们来解析一下json数据,上代码:
- #用python本地自带的库转换一下json数据
- result = json.loads(json_text)
- # print(result)
- #通过打印出转换的对象我们可以看到我们要的数据都要key为component对应的值之下 所以现在我们将值拿出来
- result = result["component"]
- #再次打印看看结果
- # print(result)
- # 获取国内当前数据
- result = result[0]['caseList']
- # print(result)
接着我们将获取到的数据保存到excel中,上代码:
- # 创建工作簿
- wb = openpyxl.Workbook()
- # 创建工作表
- ws = wb.active
- # 设置表的标题
- ws.title = "国内疫情"
- # 写入表头
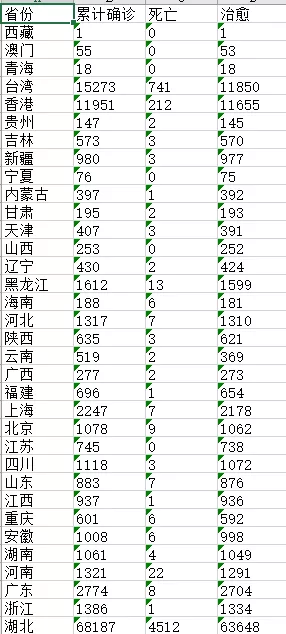
- ws.append(["省份","累计确诊","死亡","治愈"])
- #获取各省份的数据并写入
- for line in result:
- line_name = [line["area"],line["confirmed"],line["died"],line["crued"]]
- for ele in line_name:
- if ele == '':
- ele = 0
- ws.append(line_name)
- #保存到excel中
- wb.save('./china.xlsx')
最后我们查看一下获取到的数据是什么样的,如图:
emmmm,终于我们把数据获取部分完成了,第二部分的数据可视化来了!!!
数据可视化
这次我们用到的库是pyecharts里面的Map,我们先展示一下本次可视化用到的库
- #可视化部分
- import pandas as pd
- from pyecharts.charts import Map,Page
- from pyecharts import options as opts
首先我们要先通过pandas库来获取到刚才我们爬取到的数据,上代码:
- # 设置列对齐
- pd.set_option('display.unicode.ambiguous_as_wide', True)
- pd.set_option('display.unicode.east_asian_width', True)
- # 打开文件
- df = pd.read_excel('china.xlsx')
- # 对省份进行统计
- data2 = df['省份']
- data2_list = list(data2)
- data3 = df['累计确诊']
- data3_list = list(data3)
- data4 = df['死亡']
- data4_list = list(data4)
- data5 = df ['治愈']
- data5_list = list(data5)
接着我们来做数据可视化,将在我国地图上的各个省份显示出对应的数值
我们以疫情发生以来治愈数为例,上代码:
- c = (
- Map()
- .add("治愈", [list(z) for z in zip(data2_list, data5_list)], "china")
- .set_global_opts(
- title_opts=opts.TitleOpts(),
- visualmap_opts=opts.VisualMapOpts(max_=200),
- )
- )
- c.render()
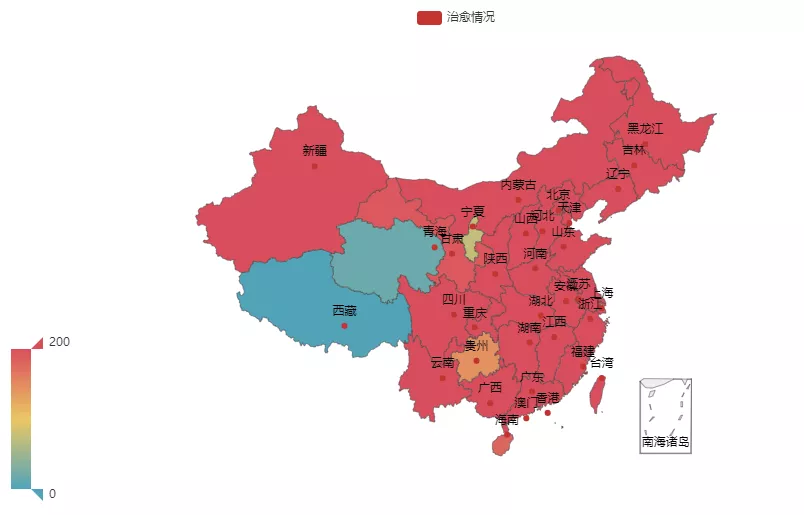
当然仅仅一个治愈情况当然说明不了什么,所以我们将三种情况都以这种形式显示出来,上代码:
- a = (
- Map()
- .add("累计确诊", [list(z) for z in zip(data2_list, data3_list)], "china")
- .set_global_opts(
- title_opts=opts.TitleOpts(),
- visualmap_opts=opts.VisualMapOpts(max_=200),
- )
- )
- b = (
- Map()
- .add("死亡", [list(z) for z in zip(data2_list, data4_list)], "china")
- .set_global_opts(
- title_opts=opts.TitleOpts(),
- visualmap_opts=opts.VisualMapOpts(max_=200),
- )
- )
- c = (
- Map()
- .add("治愈", [list(z) for z in zip(data2_list, data5_list)], "china")
- .set_global_opts(
- title_opts=opts.TitleOpts(),
- visualmap_opts=opts.VisualMapOpts(max_=200),
- )
- )
- page = Page(layout=Page.DraggablePageLayout)
- page.add(
- a,
- b,
- c,
- )
- # 先生成render.html文件
- page.render()
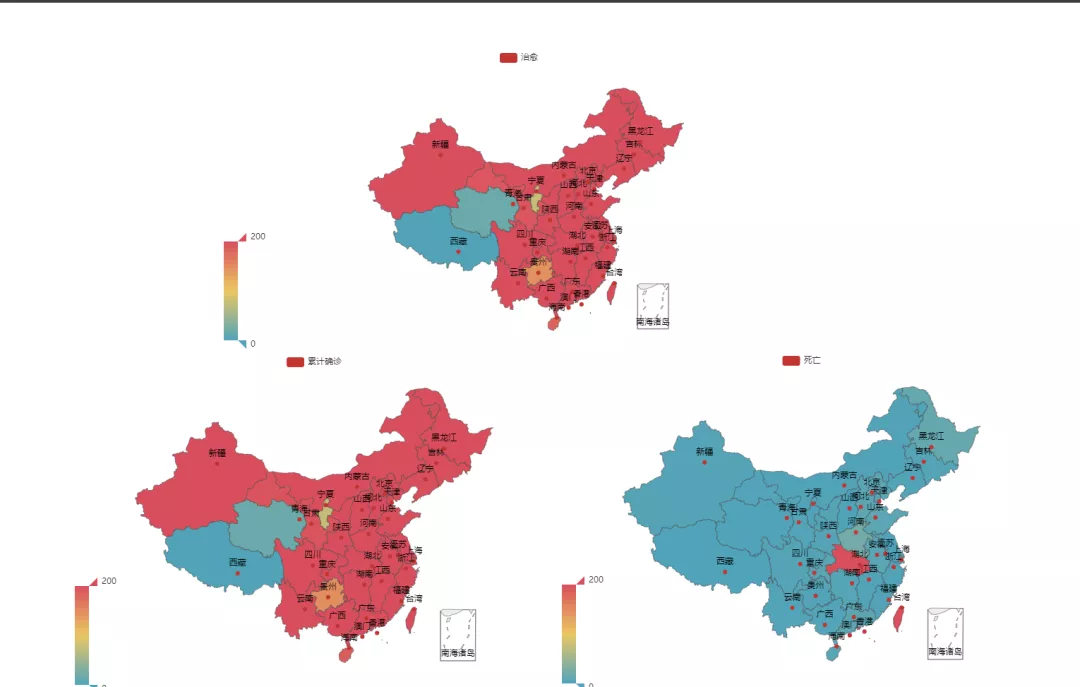
当然如果是直接运行代码的话展现出来的地图不是这样的,这个是通过后期的排版来完成的。那么在最后我们来说说是怎么排版的吧。
首先你先将上面的代码运行之后会产生一个render.html的文件然后你打开文件之后可以调整整个页面的布局,根据自己的喜欢来调整,接着点击左上角的“Save Config”将这个json文件保存到跟render.html这个文件同一个路径之下,最后运行一下代码:
- #完成上一步之后把 page.render()这行注释掉
- # 然后循行这下面
- Page.save_resize_html("render.html",
- cfg_file="chart_config.json",
- dest="my_test.html")
这样以后会产生一个my_test.html这个文件就是我们上面展示的那样啦。
结束语
以上就是我们这次的结果。从数据的获取到数据可视化,怎么说呢pyecharts还具有其他强大的可视化功能。