












对于机器学习来说,参数可以算得上算法的关键:它们是历史的输入数据,经过模型训练得来的结果,是模型的一部分。
一般来说,在NLP领域,参数数量和复杂程度之间具有正相关性。而OpenAI的GPT-3则是迄今为止最大的语言模型之一,有1750亿个参数。
那么,GPT-4会是什么样子的?
近日有网友就对GTP-4及其「开源版」GPT-NeoX进行了大胆的预测。
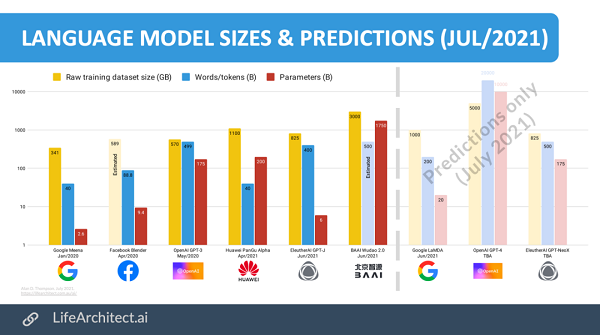
作者认为,GPT-4的参数或许可以达到10T,是现在GPT-3模型的57倍还多,而GPT-NeoX的规模则可以和GPT-3持平。
等下,如果是这样,程序员们还能不能在GPT-NeoX上愉快地调参了?
|
模型 |
发布时间 |
Tokens |
参数 |
占1.75T的百分比 |
训练文本 |
|
GPT-2 (OpenAI) |
Feb 2019 |
10B |
1.5B |
0.09% |
40GB |
|
GPT-J (EleutherAI) |
Jun 2021 |
400B |
6B |
0.34% |
800GB |
|
GPT-3 (OpenAI) |
May 2020 |
499B |
175B |
10.00% |
570GB |
|
PanGu (Chinese) |
Apr 2021 |
40B |
200B |
11.43% |
1.1TB |
|
HyperCLOVA (Korean) |
May 2021 |
560B |
204B |
11.66% |
1TB? |
|
Wudao 2.0 (Chinese) |
Jun 2021 |
500B? |
1.75T |
100.00% |
2.4TB |
|
LaMDA (Google) |
Jun 2021 |
1T? |
200B? |
11.43% |
1TB? |
|
GPT-4 (OpenAI) |
TBA |
20T? |
10T? |
571.43% |
5TB? |
|
GPT-NeoX (EleutherAI) |
TBA |
500B? |
175B? |
10.00% |
825GB? |
数据集分析
目前应用最广的GPT-3的训练语料库来自于规模巨大的结构文本。其中所有数据集都被索引,分类,过滤和加权,而且还针对重复的部分也做了大量的删减。
专门为Openai开发并由Microsoft Azure托管的世界最强超算之一完成了对GPT-3的训练 。超算系统有超过285,000个CPU核心,超过10,000个 GPU,并且以400Gbps的速度运行。

GPT-3
Wikipedia DataSet是来自于Wikipedia的英文内容。由于其质量,写作风格和广度,它是语言建模的高质量文本的标准来源。
WebText数据集(以及扩展版本WebText2)是来自从Reddit出站的大于4500万个网页的文本,其中相关的帖子会有两个以上的支持率(upvotess)。
由于具有大于4.3亿的月活用户,因此数据集中的内容可以被认为是最 「流行 」网站的观点。
Books1和Books2是两个基于互联网的书籍数据集。类似的数据集包括:
- BookCorpus,是由未发表的作者撰写的免费小说书籍的集合,包含了至少10,000本书。
- Library Genesis (Libgen),一个非常大的科学论文、小说和非小说类书籍的集合。
Common Crawl是一个包含了超过50亿份网页元数据和提取文本的开源存档开放的数据平台:
- 八年来PB级的数据(数以千计的TB,数以百万计的GB)。
- 25B个网站。
- 数以万亿计的链接。
- 75%英语,3%中文,2.5%西班牙语,2.5%德语等。
- 排名前10域名的内容:Facebook、谷歌、Twitter、Youtube、Instagram、LinkedIn。
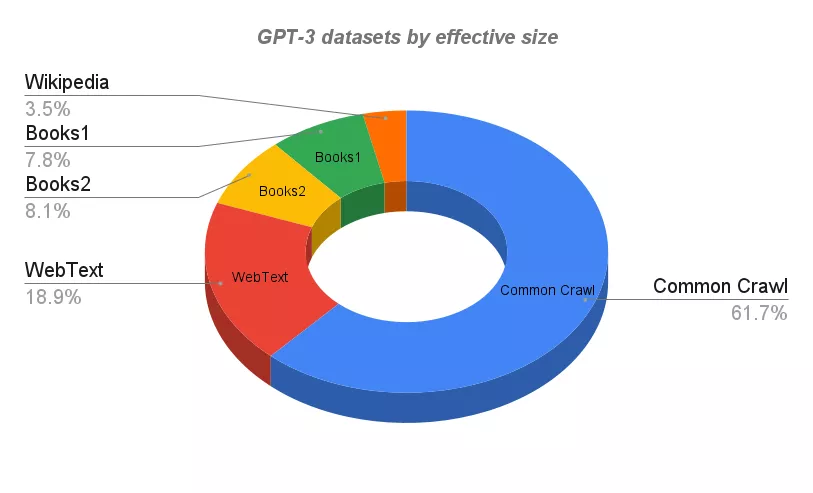
GPT-3使用的数据集
GPT-Neo和GPT-J
今年3月,Eleuther AI在GitHub上推出了GPT-Neo开源项目,可以在Colab上进行微调。
虽然GPT-Neo与GPT-3比,参数量仍然很小(1.3B和2.7B),但开源又免费,仍然得到了「同性好友们」的认可。
今年6月Eleuther AI再次推出GPT-J-6B,它可以说是GPT-Neo的增强版本,顾名思义,模型的参数量增加到了6B。
GPT-J的训练也是基于The Pile数据库——一个825GB的多样化开源语言建模数据集,由22个较小的、高质量的数据集合组成。
The Pile除了专业论坛和知识库,如HackerNews、Github和Stack Exchange,论文预印本网站ArXiv以外,还包括如Youtube字幕,甚至安然邮件(Enron Emails)语料库。
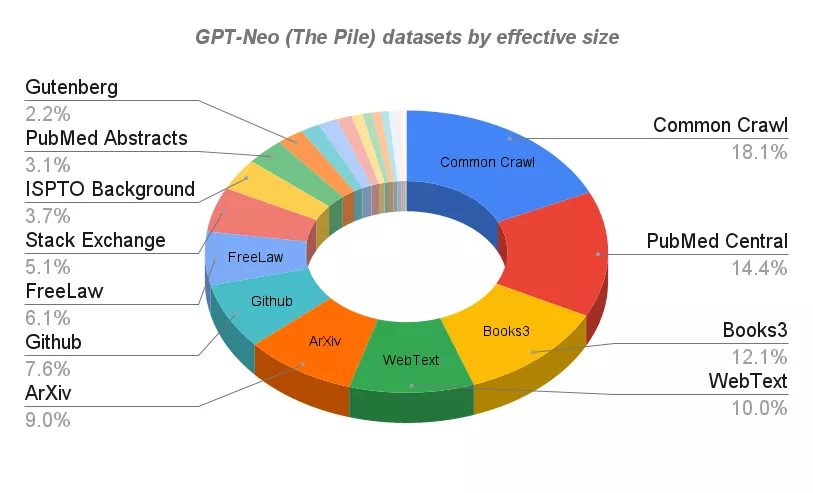
GPT-Neo和GPT-J使用的数据集
在zero-shot任务上,GPT-J性能和67亿参数的GPT-3相当,也是目前公开可用的Transformer语言模型中,在各种下游zero-shot任务上表现最好的。
这么看来,确实可以期待一下和GPT-3相同规模的GPT-NeoX的表现了。
网友评论
GPT-4怎么这么大?
「GPT-3已经接近理论上每个token的最大效率了。如果OpenAI模型的工作方式是正确的,更大的模型只是对算力的浪费。」

有网友解答说:「规模确实可以带来改善。因为本质上是一种关系隐喻模型,『了解更多的关系 』意味着能够对更多的事情或以更细微的方式做出反应。当然,这也同时是一个营销的方式。」





























