













【51CTO.com快译】关于现代数据分析员在分布式计算环境中的有效性,引起了人们很久的争论。分析师习惯 SQL 在短时间内可以查询到问题的答案。当查询在几个小时内没有返回结果时,RDBMS 用户通常会无法理解根本原因。
Hive 和 Spark 等查询引擎对于高级工程师来说是很复杂的,但是有的并不这样认为。在 Acceldata上,我们可以看到完整的表扫描在多 Tera Byte 表上运行从而获取行数,这在 Hadoop中至少是不允许操作的。实际上,数据需要转化为洞察力才能做出业务决策。值得一提的是,大数据的价值需要实时获取。
Hadoop 管理员/工程师准备阐释大量的度量指标,并分析性能不佳和从集群中拿走资源的原因,从而导致:
• 失控的资源问题
• 失控的时间问题
• 导致停机的泄漏
在开始纠正步骤之前必须提供以下详细信息:
• 历史查询性能(查询是重复的前提下)
• 执行视图——Mappers(映射器)、Reducer(减速器)、连接效率
• 数据视图 - 哪些表(事实维度)
• 纱线容器的效率
• 执行计划——(逻辑和物理计划)
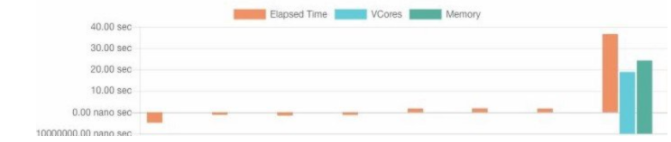
历史查询性能: Acceldata APM 对在交互式 BI 队列上运行的每个 SQL 进行指纹识别。这是通过解析 AST 来完成的,并记住经常使用的查询的参数进行不断变化,例如,在每日报告的情况下。在下一次运行 SQL 时,Acceldata 能够将该查询的过去性能与最近的运行相关联。查询执行参数中的异常(如下所示)在视觉上表示异常:
• 经过的持续时间
• 从 HDFS 读取数据
• 数据写入 HDFS
• VCore的使用
• 内存利用率
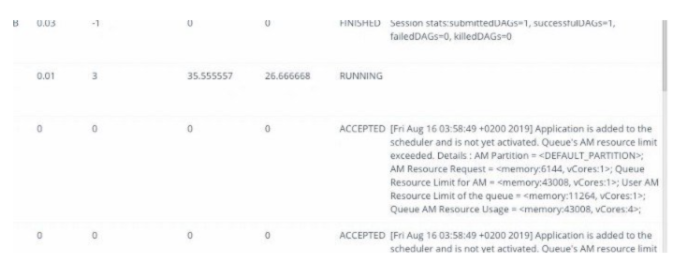
执行视图: 在某些情况下,当一个Reducers需要花费很长时间时,查询则需要很长的持续时间,就好像一个“掉队者”,消耗超过 90% 的持续时间。这种识别有助于整改;然而,如果要实现这一点,不登录多个服务器,并且没跨层的横截面视图的帮助,是非常具有挑战性的。Acceldata 结合纱线诊断日志,将Mappers和Reducers的持续时间、顺序可视化。

以下是纱线诊断数据,显示纱线应用程序从开始到结束的执行阶段。这提供了一个清晰的概念,假如 Yarn 应用程序被抢占,那么内存和 VCore 的分配是什么,在这些应用程序中可以处理作业的容器的数量是多少。同时还提供了诊断消息,允许用户在作业失败的情况下识别异常,而无需离开UI。
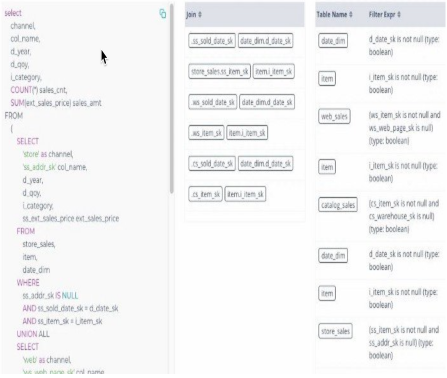
SQL 和数据视图
Acceldata Query 360 的提供了 SQL、被查询的表和正在运行的连接的视图。除此之外,还有关于过滤条件的详细信息、过滤谓词是否准确,以及特定连接是否对查询产生了不利影响,这是 SQL 诊断最重要的方面之一。
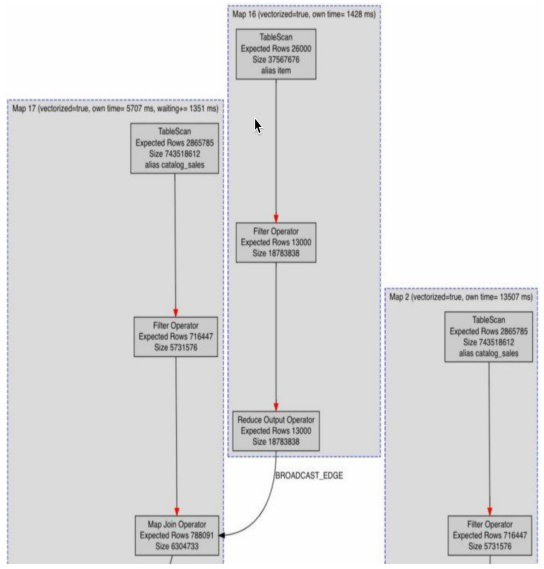
查询计划
对任何查询的最终诊断都需要知晓查询计划。Acceldata 支持所有类型的 Hive和Map Reduce-Tez、MapReduce和LLAP的查询计划。这为管理员和数据工程师提供了一种简单的方法来了解——TableScans ,操作行为是有意的还是偶然的,广播连接在哪里发生,CBO 是否已启动,是否为特定查询设置了 PPD ,以及可以完成哪些连接优化。
表
Hive 表的布局对查询性能的影响是显著的。在没有数据压缩或准确分区的情况下,很可能会对表进行端到端扫描,或者称为 TableScan,因此Mappers器将花费更长的时间来完成,尽管有过滤谓词。

但是,为了对分区策略做出明确的决定,需要了解表和列的使用组合。分析员运行的不是一个查询,而是几个查询的组合,以确定哪个是理想的分区键,以及表是否可以静态分区或动态分区。视图如下所示:
结论
Hive 和 Spark 用户和管理员很难获得一个表示查询/作业执行横截面的视图。在分布式计算领域,可见性仍然是一个挑战,尤其是在 Hive 和 Spark 工作负载上。Acceldata 支持 360 度视图以进行决策。通过以上部分,我们可以清楚地看到 管理员/工程师拥有所有可用于识别和纠正的信息:
• 相同查询的当前运行和过去运行的历史比较
• 执行查询的时间
• 有问题的表及其连接
• Mapper 和 reducer 性能异常
• 物理文件系统上的数据布局,用于分区策略
• 查询计划可快速轻松地做出决策
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】












