













本文转载自微信公众号「肌肉码农」,作者肌肉码农。转载本文请联系肌肉码农公众号。
Caffeine使用一个ConcurrencyHashMap来保存所有数据,那它的过期淘汰策略采用什么方式与数据结构呢?其中写过期是使用writeOrderDeque,这个比较简单无需多说,而读过期相对复杂很多,使用W-TinyLFU的结构与算法。
网络上有很多文章介绍W-TinyLFU结构的,大家可以去查一下,这里主要是从源码来分析,总的来说它使用了三个双端队列:accessOrderEdenDeque,accessOrderProbationDeque,accessOrderProtectedDeque,使用双端队列的原因是支持LRU算法比较方便。
accessOrderEdenDeque属于eden区,缓存1%的数据,其余的99%缓存在main区。
accessOrderProbationDeque属于main区,缓存main内数据的20%,这部分是属于冷数据,即将补淘汰。
accessOrderProtectedDeque属于main区,缓存main内数据的80%,这部分是属于热数据,是整个缓存的主存区。
我们先看一下淘汰方法入口:
- void evictEntries() {
- if (!evicts()) {
- return;
- }
- //先从edn区淘汰
- int candidates = evictFromEden();
- //eden淘汰后的数据进入main区,然后再从main区淘汰
- evictFromMain(candidates);
- }
accessOrderEdenDeque对应W-TinyLFU的W(window),这里保存的是最新写入数据的引用,它使用LRU淘汰,这里面的数据主要是应对突发流量的问题,淘汰后的数据进入accessOrderProbationDeque.代码如下:
- int evictFromEden() {
- int candidates = 0;
- Node<K, V> node = accessOrderEdenDeque().peek();
- while (edenWeightedSize() > edenMaximum()) {
- // The pending operations will adjust the size to reflect the correct weight
- if (node == null) {
- break;
- }
- Node<K, V> next = node.getNextInAccessOrder();
- if (node.getWeight() != 0) {
- node.makeMainProbation();
- //先从eden区移除
- accessOrderEdenDeque().remove(node);
- //移除的数据加入到main区的probation队列
- accessOrderProbationDeque().add(node);
- candidates++;
- lazySetEdenWeightedSize(edenWeightedSize() - node.getPolicyWeight());
- }
- node = next;
- }
- return candidates;
- }
数据进入probation队列后,继续执行以下代码:
- void evictFromMain(int candidates) {
- int victimQueue = PROBATION;
- Node<K, V> victim = accessOrderProbationDeque().peekFirst();
- Node<K, V> candidate = accessOrderProbationDeque().peekLast();
- while (weightedSize() > maximum()) {
- // Stop trying to evict candidates and always prefer the victim
- if (candidates == 0) {
- candidate = null;
- }
- // Try evicting from the protected and eden queues
- if ((candidate == null) && (victim == null)) {
- if (victimQueue == PROBATION) {
- victim = accessOrderProtectedDeque().peekFirst();
- victimQueue = PROTECTED;
- continue;
- } else if (victimQueue == PROTECTED) {
- victim = accessOrderEdenDeque().peekFirst();
- victimQueue = EDEN;
- continue;
- }
- // The pending operations will adjust the size to reflect the correct weight
- break;
- }
- // Skip over entries with zero weight
- if ((victim != null) && (victim.getPolicyWeight() == 0)) {
- victim = victim.getNextInAccessOrder();
- continue;
- } else if ((candidate != null) && (candidate.getPolicyWeight() == 0)) {
- candidate = candidate.getPreviousInAccessOrder();
- candidates--;
- continue;
- }
- // Evict immediately if only one of the entries is present
- if (victim == null) {
- candidates--;
- Node<K, V> evict = candidate;
- candidate = candidate.getPreviousInAccessOrder();
- evictEntry(evict, RemovalCause.SIZE, 0L);
- continue;
- } else if (candidate == null) {
- Node<K, V> evict = victim;
- victim = victim.getNextInAccessOrder();
- evictEntry(evict, RemovalCause.SIZE, 0L);
- continue;
- }
- // Evict immediately if an entry was collected
- K victimKey = victim.getKey();
- K candidateKey = candidate.getKey();
- if (victimKey == null) {
- Node<K, V> evict = victim;
- victim = victim.getNextInAccessOrder();
- evictEntry(evict, RemovalCause.COLLECTED, 0L);
- continue;
- } else if (candidateKey == null) {
- candidates--;
- Node<K, V> evict = candidate;
- candidate = candidate.getPreviousInAccessOrder();
- evictEntry(evict, RemovalCause.COLLECTED, 0L);
- continue;
- }
- // Evict immediately if the candidate's weight exceeds the maximum
- if (candidate.getPolicyWeight() > maximum()) {
- candidates--;
- Node<K, V> evict = candidate;
- candidate = candidate.getPreviousInAccessOrder();
- evictEntry(evict, RemovalCause.SIZE, 0L);
- continue;
- }
- // Evict the entry with the lowest frequency
- candidates--;
- //最核心算法在这里:从probation的头尾取出两个node进行比较频率,频率更小者将被remove
- if (admit(candidateKey, victimKey)) {
- Node<K, V> evict = victim;
- victim = victim.getNextInAccessOrder();
- evictEntry(evict, RemovalCause.SIZE, 0L);
- candidate = candidate.getPreviousInAccessOrder();
- } else {
- Node<K, V> evict = candidate;
- candidate = candidate.getPreviousInAccessOrder();
- evictEntry(evict, RemovalCause.SIZE, 0L);
- }
- }
- }
上面的代码逻辑是从probation的头尾取出两个node进行比较频率,频率更小者将被remove,其中尾部元素就是上一部分从eden中淘汰出来的元素,如果将两步逻辑合并起来讲是这样的:在eden队列通过lru淘汰出来的”候选者“与probation队列通过lru淘汰出来的“被驱逐者“进行频率比较,失败者将被从cache中真正移除。下面看一下它的比较逻辑admit:
- boolean admit(K candidateKey, K victimKey) {
- int victimFreq = frequencySketch().frequency(victimKey);
- int candidateFreq = frequencySketch().frequency(candidateKey);
- //如果候选者的频率高就淘汰被驱逐者
- if (candidateFreq > victimFreq) {
- return true;
- //如果被驱逐者比候选者的频率高,并且候选者频率小于等于5则淘汰者
- } else if (candidateFreq <= 5) {
- // The maximum frequency is 15 and halved to 7 after a reset to age the history. An attack
- // exploits that a hot candidate is rejected in favor of a hot victim. The threshold of a warm
- // candidate reduces the number of random acceptances to minimize the impact on the hit rate.
- return false;
- }
- //随机淘汰
- int random = ThreadLocalRandom.current().nextInt();
- return ((random & 127) == 0);
- }
从frequencySketch取出候选者与被驱逐者的频率,如果候选者的频率高就淘汰被驱逐者,如果被驱逐者比候选者的频率高,并且候选者频率小于等于5则淘汰者,如果前面两个条件都不满足则随机淘汰。
整个过程中你是不是发现protectedDeque并没有什么作用,那它是怎么作为主存区来保存大部分数据的呢?
- //onAccess方法触发该方法
- void reorderProbation(Node<K, V> node) {
- if (!accessOrderProbationDeque().contains(node)) {
- // Ignore stale accesses for an entry that is no longer present
- return;
- } else if (node.getPolicyWeight() > mainProtectedMaximum()) {
- return;
- }
- long mainProtectedWeightedSize = mainProtectedWeightedSize() + node.getPolicyWeight();
- //先从probation中移除
- accessOrderProbationDeque().remove(node);
- //加入到protected中
- accessOrderProtectedDeque().add(node);
- node.makeMainProtected();
- long mainProtectedMaximum = mainProtectedMaximum();
- //从protected中移除
- while (mainProtectedWeightedSize > mainProtectedMaximum) {
- Node<K, V> demoted = accessOrderProtectedDeque().pollFirst();
- if (demoted == null) {
- break;
- }
- demoted.makeMainProbation();
- //加入到probation中
- accessOrderProbationDeque().add(demoted);
- mainProtectedWeightedSize -= node.getPolicyWeight();
- }
- lazySetMainProtectedWeightedSize(mainProtectedWeightedSize);
- }
当数据被访问时并且该数据在probation中,这个数据就会移动到protected中去,同时通过lru从protected中淘汰一个数据进入到probation中。
这样数据流转的逻辑全部通了:新数据都会进入到eden中,通过lru淘汰到probation,并与probation中通过lru淘汰的数据进行使用频率pk,如果胜利了就继续留在probation中,如果失败了就会被直接淘汰,当这条数据被访问了,则移动到protected。当其它数据被访问了,则它可能会从protected中通过lru淘汰到probation中。
TinyLFU
传统LFU一般使用key-value形式来记录每个key的频率,优点是数据结构非常简单,并且能跟缓存本身的数据结构复用,增加一个属性记录频率就行了,它的缺点也比较明显就是频率这个属性会占用很大的空间,但如果改用压缩方式存储频率呢? 频率占用空间肯定可以减少,但会引出另外一个问题:怎么从压缩后的数据里获得对应key的频率呢?
TinyLFU的解决方案是类似位图的方法,将key取hash值获得它的位下标,然后用这个下标来找频率,但位图只有0、1两个值,那频率明显可能会非常大,这要怎么处理呢? 另外使用位图需要预占非常大的空间,这个问题怎么解决呢?
TinyLFU根据最大数据量设置生成一个long数组,然后将频率值保存在其中的四个long的4个bit位中(4个bit位不会大于15),取频率值时则取四个中的最小一个。
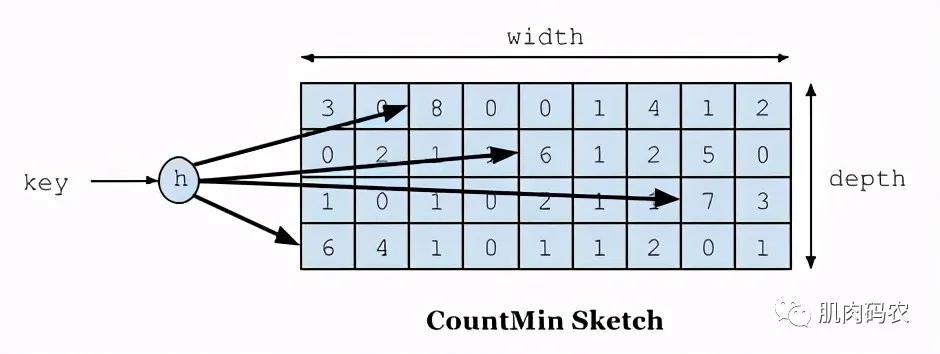
Caffeine认为频率大于15已经很高了,是属于热数据,所以它只需要4个bit位来保存,long有8个字节64位,这样可以保存16个频率。取hash值的后左移两位,然后加上hash四次,这样可以利用到16个中的13个,利用率挺高的,或许有更好的算法能将16个都利用到。
- public void increment(@Nonnull E e) {
- if (isNotInitialized()) {
- return;
- }
- int hash = spread(e.hashCode());
- int start = (hash & 3) << 2;
- // Loop unrolling improves throughput by 5m ops/s
- int index0 = indexOf(hash, 0); //indexOf也是一种hash方法,不过会通过tableMask来限制范围
- int index1 = indexOf(hash, 1);
- int index2 = indexOf(hash, 2);
- int index3 = indexOf(hash, 3);
- boolean added = incrementAt(index0, start);
- added |= incrementAt(index1, start + 1);
- added |= incrementAt(index2, start + 2);
- added |= incrementAt(index3, start + 3);
- //当数据写入次数达到数据长度时就重置
- if (added && (++size == sampleSize)) {
- reset();
- }
- }
给对应位置的bit位四位的Int值加1:
- boolean incrementAt(int i, int j) {
- int offset = j << 2;
- long mask = (0xfL << offset);
- //当已达到15时,次数不再增加
- if ((table[i] & mask) != mask) {
- table[i] += (1L << offset);
- return true;
- }
- return false;
- }
获得值的方法也是通过四次hash来获得,然后取最小值:
- public int frequency(@Nonnull E e) {
- if (isNotInitialized()) {
- return 0;
- }
- int hash = spread(e.hashCode());
- int start = (hash & 3) << 2;
- int frequency = Integer.MAX_VALUE;
- //四次hash
- for (int i = 0; i < 4; i++) {
- int index = indexOf(hash, i);
- //获得bit位四位的Int值
- int count = (int) ((table[index] >>> ((start + i) << 2)) & 0xfL);
- //取最小值
- frequency = Math.min(frequency, count);
- }
- return frequency;
- }
当数据写入次数达到数据长度时就会将次数减半,一些冷数据在这个过程中将归0,这样会使hash冲突降低:
- void reset() {
- int count = 0;
- for (int i = 0; i < table.length; i++) {
- count += Long.bitCount(table[i] & ONE_MASK);
- table[i] = (table[i] >>> 1) & RESET_MASK;
- }
- size = (size >>> 1) - (count >>> 2);
- }




















