本文转载自微信公众号「咖啡拿铁」,作者咖啡拿铁。转载本文请联系咖啡拿铁公众号。
背景
tidb这个技术名词很多同学或多或少都曾经耳闻过,但是很多同学觉得他是分布式数据库,自己的业务是使用mysql,基本使用不上这个技术,可能不会去了解他。最近业务上有个需求使用到了tidb,于是学习了一下基本原理,会发现这些原理其实不仅仅局限于分布式数据库这一块,很多技术都是通用的,所以在这里写一下分享一下学习tidb的一些心得。
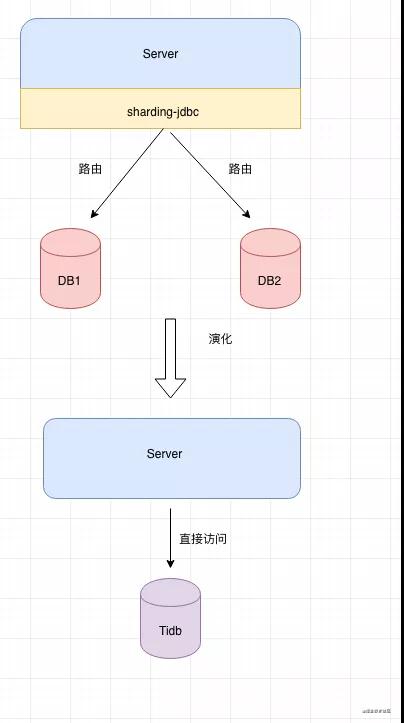
先说说为什么选择tidb吧,一般来说在咱们的业务中都是使用的mysql,但是单机数据库容量和并发性能都有限,对于一些大容量或者高并发的场景我们会选择sharding-jdbc去做,使用sharding-jdbc的确解决了问题但是增加了开发难度,我需要对我的每一个表都设置分表key,并且每个查询都得带入这个key的值,这样就增加了查询限制,如果不带key的值就得所有库表都得查询一次才行,效率极低,所以我们又异构了一份数据到es来满足其他条件。怎么解决这个问题呢?正好公司最近内部在推tidb,我看了下tidb基本兼容mysql,存储无限扩展,开发成本比较低,性能整体也不错,所以决定使用了tidb。
数据库发展历史
关系型单机数据库
关系型数据库的开始是以1970年Edgar F.Codd 提出了关系模型。在数据库发展早期阶段,出现了很多优秀的商业数据库产品,如Oracle/DB2。在1990年之后,出现了开源数据库MySQL和PostgreSQL。这些数据库不断地提升单机实例性能,再加上遵循摩尔定律的硬件提升速度,往往能够很好地支撑业务发展。
分布式数据库
随着摩尔定律的失效,单体数据库的发展很难应对更高级别的挑战,所以就出现了分布式数据库,分布式数据库拥有应对海量并发,海量存储的能力所以能应对更难的挑战。
- nosql:HBase是其中的典型代表。HBase是Hadoop生态中的重要产品,Google BigTable的开源实现,当然还有我们熟悉的redis,nosql有一些自己的特殊使用场景,所以有一些自己的弊端,BigTable不支持跨行事务,用java开发性能也跟不上,redis的话用内存存储,无法保证事务。并且nosql已经是不靠关系模型了。
- sharding: 我们依然可以通过单机数据库完成我们分布式数据库的功能,我们通过某个组件实现对sql进行分发到不同分片的功能,比如比较出名开源的有sharing-jdbc,mycat,阿里云上商业的有drds。sharing的话对于运维来说比较困难,如果需要扩容需要不断的进行手动迁移数据,还需要自己指定某一个分片key。
- newsql:在newsql中可以保证acid的事务,也维持了关系模型,并且还支持sql。比较出名的有goole的F1和Spanner,阿里的OceanBase,pingCap的tidb。
学前提问
在我们学习某个知识的时候,一般都是会带着一些问题去学习,有目的的学习会让你更快的上手,对于tidb或者分布式数据库,我在使用的时候会有这些疑问:
如何保证无限扩展?因为平时使用的大多都是sharding-jdbc那种有个sharding-key的技术,这种其实无限扩展是比较麻烦的,所以我最开始就对tidb如何保证无限扩展发出了疑问?
如何保证id唯一,分布式数据库往往会进行分片,在单机数据库中的自增id就不成立,tidb是如何保证的呢?
如何保证事务?前面我们说过newsql是需要支持acid的事务的,那么我们的tidb是如何保证的呢?
通过索引是如何查询数据的呢?单机数据库使用了索引加速查询,tidb又是如何做到用索引加速查询的呢?
tidb
架构
再回答我们上面的那些问题之前,先看一看tidb的整体架构是什么?
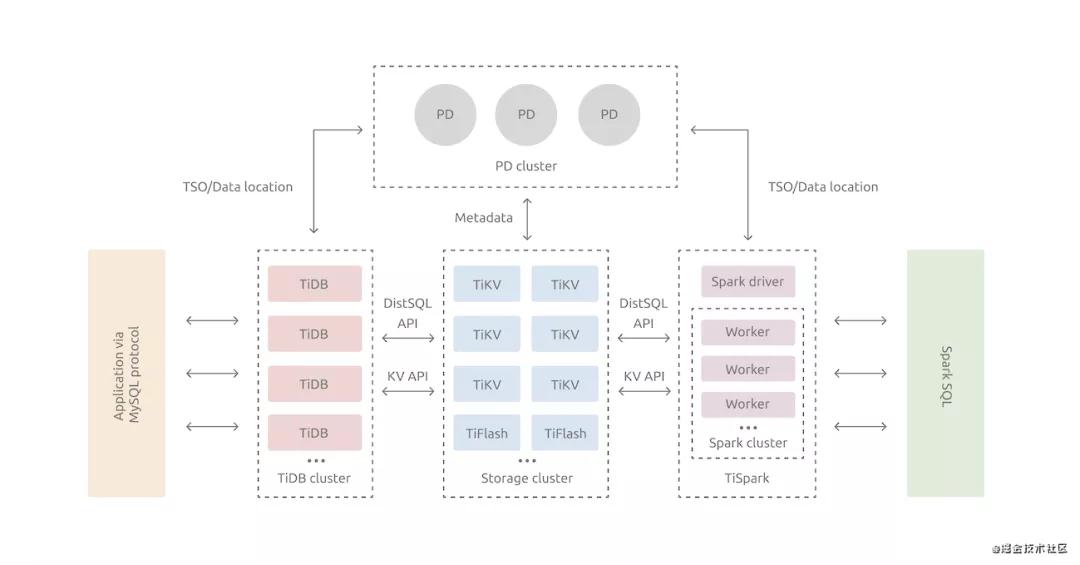
tidb其实是典型的计算分离的架构,对计算分离架构不熟悉的可以看看我之前的文章:聊聊计算与分离
TiDB Server:计算层,对外暴露协议的连接端口,负责管理客户端的连接,主要做的就是执行SQL解析以及优化,生成分布式执行计划,由于这里是计算层是没有状态的,所以是可以无限扩展。
PD Server:PD是整个集群的大脑,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,需要保持高可用。
TiKV: k-v存储引擎,在tikv内部,存储数据的基本单位是Region。
Tiflash:这个是用于列式的存储引擎
TSpark: 这是tidb对spark进行支持,所以tidb他是一个HTAP的数据库。
如何无限扩展?
我们首先来到我们的第一个问题,Tidb如何做到无限扩展?
首先我们来看看计算层: tidb-server,我们刚才说过在计算层中,是无状态的,所以就可以进行无限扩展,如果你的场景并发度很高或者数据库连接很多,可以考虑多扩展tidb-server。
然后我们来看看存储层,有一类数据云数据库通常也会被误认为是分布式数据库,也就是aws的auroradb和阿里云的polardb,这两个数据库也是采用的计算与存储分离的架构,在计算层也可以无限扩展,但是在存储层他们使用的是一份数据,这个也就是shared-storage架构,这两个数据库依靠这大容量磁盘,来支撑更高容量的数据。
在tidb中是shared-nothing架构,存储层也是分离的:
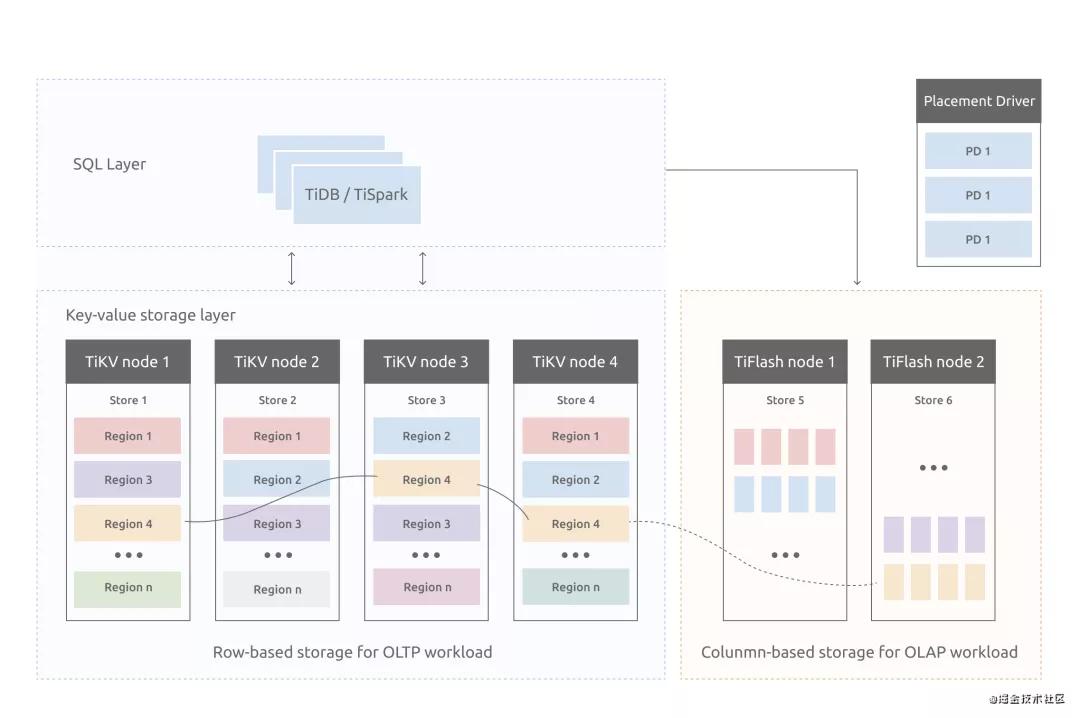
在每个tikv上会划分出多个Region,这个也就是我们的基本存储单位,大家见这个图是不是发现这个架构似曾相识呢?
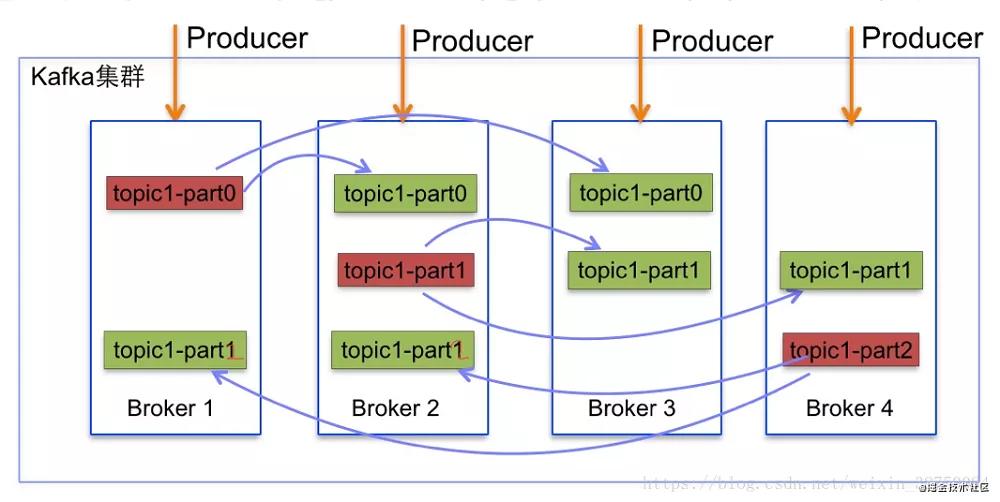
从上面看,region就对应这kafka下的partition,partition在kafka中的作用也是用来将topic的压力打散到不同broker上,同样的在tidb的region上也是一样的,我们通过region为最小单位进行存储。
再详细介绍region之前先说一下存储引擎为什么叫tikv呢?原因就是这个存储引擎就是保存的就是一个key-value,你可以理解成java里面的hashmap,在tikv中没有选择自己研发如何将这个map数据去落地,而是通过一个非常优秀的kv存储引擎——rocksdb去进行磁盘落地。RocksDB是Facebook开源的一个KV高性能单机数据库,很多公司基于rocksdb做了很多优秀的存储产品,后面也会详细的写一篇介绍rocksdb的文章。
rocksdb是一个单机的存储引擎那么我们是需要保证数据在分布式环境下是不丢失的,在kafka中有其他partition的副本会不断的拉取leader副本,并且通过一个ISR的机制去维护。在tikv中,直接使用的raft协议去做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。不过在实际写入中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
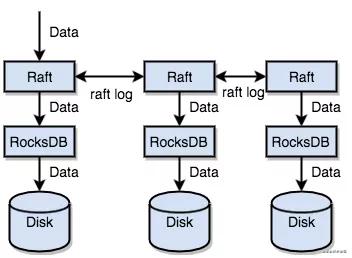
可以发现其实这里是写的raft,通过raft接口再写的rocksdb。
我们这里回到region,region还有一个partition不一样的点在于,partition一般不会自动去扩容,在业务开发中他往往是一个恒定得值,而region不一样,region的大小默认是96MB,再实际得业务中,我们的region的个数会随着我们数据量而变多,当然如果我们的数据量变小,他也会自动合并。
如何确定某个数据是在哪个region上呢?一般来说有hash(key)和range(key)的方案,在tikv中选择的是rangekey,因为对于region分裂是比较方便的,每一个region其实就是一个[StartKey,EndKey) 的表示:
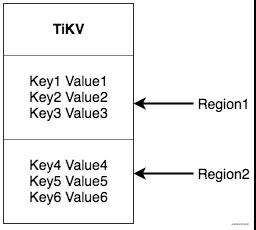
出现region的分裂的时候,只需要新增一个region,将老region的数据拿出一部分到新region, 譬如 [a, b) -> [a, ab) + [ab, b),如果是hash来做的话,他会将所有region的数据都会重新hash,所以在tikv中选的是range(key)的方式,合并也是一样。
所以对于tidb来说无论是存储层还是计算层,我们都可以无限扩展。
如何保证id唯一
在mysql中我们可以对于主键直接设置 AUTO_INCREMENT来达到自增列的效果,mysql是怎么做到自增的呢?
在MySQL5.7及之前的版本:InnoDB引擎的自增值,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+步长作为这个表当前的自增值。
在MySQL8.0版本:将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值。
在单机中这些都好做,但是在分布式数据库中,我们就没法保证id的唯一了,我之前有写过相关的文章:如果再有人问你分布式ID,这篇文章丢给他。我们在使用sharding-jdbc的时候就是使用的文章介绍的leaf这个ID生成中间件,来完成ID生成。
在Tidb中同样支持 AUTO_INCREMENT,实现的原理和leaf中的号段模式一样,不能保证严格递增,只能保证趋势递增,具体原理是:,对于每一个自增列,都使用一个全局可见的键值对用于记录当前已分配的最大 ID。由于分布式环境下的节点通信存在一定开销,为了避免写请求放大的问题,每个 TiDB 节点在分配 ID 时,都申请一段 ID 作为缓存,用完之后再去取下一段,而不是每次分配都向存储节点申请。
tidb还支持 AUTO_RANDOM,可以用于解决大批量写数据入 TiDB 时因含有整型自增主键列的表而产生的热点问题。因为region是有序的如果一段时间大量有序的数据产生有可能会在同一个region上,所以我们可以使用AUTO_RANDOM来将我们的主键数据打散。
如何保证事务
这里我们先回顾一下事务的四大特性ACID,我们来想想在mysql的innodb中这个是怎么做的呢?
- A:原子性,指一个事务中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节,原子性在mysql中我们是依赖redolog和undolog共同完成
- C:一致性,指在事务开始之前和结束以后,数据库的完整性没有被破坏。一致性是依靠其他几个特性来保证的。
- I:隔离性,指数据库允许多个并发事务同时对其数据进行读写和修改的能力。隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致,主要用于处理并发场景。mysql隔离性依靠的是锁和mvcc,在mysql里面锁的种类很丰富,mysql支持多种隔离性。
- D:持久性,事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失,持久性是依靠redolog和mysql的刷盘机制。
在tidb中ACID是什么做到的呢?
- A:通过 Primary Key 所在 Region 的原子性来保证分布式事务的原子。
- C:TiDB 在写入数据之前,会校验数据的一致性,校验通过才会写入内存并返回成功。
- I:也是通过锁和mvcc来完成隔离性,但是在tidb只支持RR(可重复读)级别,RC隔离级别在4.0之后乐观模式下也能支持。
- D:事务一旦提交成功,数据全部持久化存储到 TiKV,并且还有多副本机制,如果发生宕机数据也不会丢失。
在mysql中的事务模型都是悲观事务模型,而在tidb中事务模型提供了乐观和悲观两种,怎么去理解悲观和乐观两种模型呢:
- 悲观模型:其实和名字一样,只要在事务执行的时候认为每一条被你修改的数据都很大概率被其他事务修改(悲观的看法)。在mysql里面,如果你在事务中你对某一行修改是会给你加上行锁的,如果此时有其他事务想对这个数据进行修改,那么其他事务会被阻塞等待住。可以简单理解成边执行边检测冲突。
- 乐观模型:我们认为我们修改的数据很大概率不会和其他事务产生冲突,所以不需要边执行边进行冲突检测,而是最后提交的时候进行冲突检测。如果冲突比较少这样就可以获得较高的性能。
在tidb中是如何实现这两种模式的呢?因为我们是分布式数据库,两阶段提交一般是分布式事务的通用解决方案,之前我写过很多分布式事务相关的文章大家可以自行查阅一下。
乐观模式
tidb同样使用两阶段提交来保证分布式事务的原子性,分为 Prewrite 和 Commit 两个阶段:
- Prewrite:对事务修改的每个 Key 检测冲突并写入 lock 防止其他事务修改。对于每个事务,TiDB 会从涉及到改动的所有 Key 中选中一个作为当前事务的 Primary Key,事务提交或回滚都需要先修改 Primary Key,以它的提交与否作为整个事务执行结果的标识。
- Commit:Prewrite 全部成功后,先同步提交 Primary Key,成功后事务提交成功,其他 Secondary Keys 会异步提交。
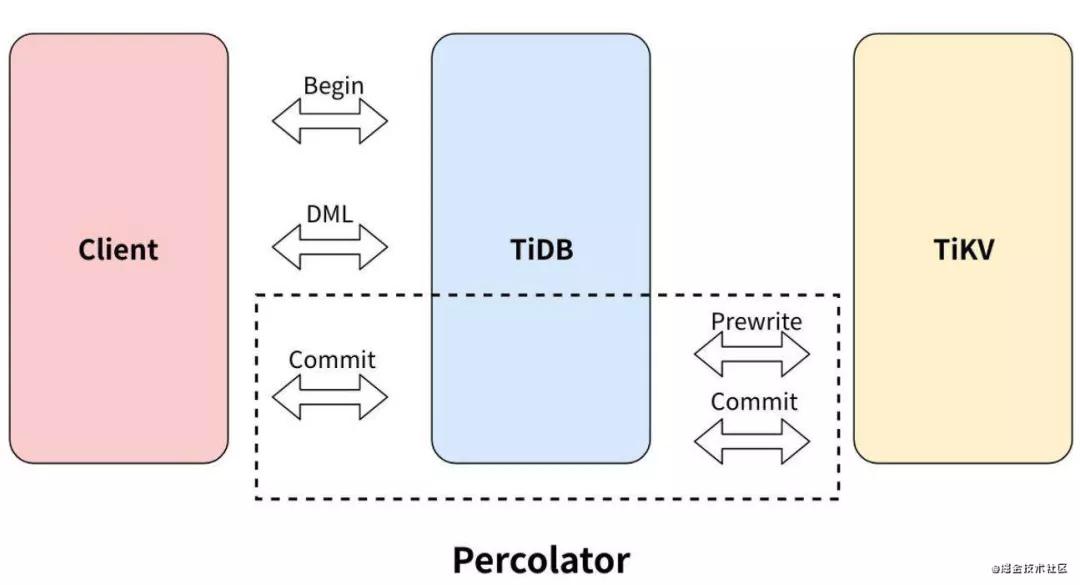
整个事务步骤如下:
- Step 1: 客户端开启事务,类似我们在mysql里面的 begintrasaction;
- Step 2: TiDB 向 PD 获取全局时间,可以知道这个事务的全局顺序,用于后续mvcc的处理
- Step 3: 发起DML,比如update xxx; 这个时候不会有冲突检测,只会在tidb内存中进行保存;
- Step 4: 提交事务,类似我们在mysql里面的commit,这个时候tidb会在commit阶段完成两阶段提交,先进行prewrite 各种加锁检测之后如果没有问题再进行commit。这里举个例子:
- begin; //step1
- insert into xx; // step3
- update xx; // step3
- update xx; // step3
- commit;// step4
在上面的例子中如果是悲观模式step3的时候就会进行加锁检测了,乐观模式下所有的工作都放在了commit中,所以会出现commit出现异常的状态,所以我们使用乐观模式需要更好的处理commit阶段的异常行为,这和我们一般的编程不一样。但是如果数据的竞争不是太激烈的话是可以使用乐观模式来提升性能的。
悲观模式

悲观模式把lock进行了提前,每个 DML 都会加悲观锁,锁写到 TiKV 里,同样会通过 raft 同步,在加悲观锁时检查各种约束,如 Write Conflict、key 唯一性约束等。
悲观事务下能保证我们的commit成功,这种模式比较符合我们的编程模式,所以tidb默认的模式也是悲观模式。
如何做的索引查询
为什么我会想到这个索引查询这个问题呢?当时是在看到了rocksdb是tidb的底层存储介质之后,我想到了在innodb中我们的索引是B+树,如果tidb的索引是b+树的话,那么rocksdb应该怎么去构造呢?
事实上在tidb中的索引也是使用的k-v形式去做的,我们先看看对于每一行的数据是怎么存储的:
- 为了保证同一个表的数据放在一起,方便查找,TiDB 会为每个表分配一个表 ID,用 TableID 表示。表 ID 是一个整数,在整个集群内唯一。
- TiDB 会为表中每行数据分配一个行 ID,用 RowID 表示。行 ID 也是一个整数,在表内唯一。对于行 ID,TiDB 做了一个小优化,如果某个表有整数型的主键,TiDB 会使用主键的值当做这一行数据的行 ID。每行数据按照如下规则编码成 (Key, Value) 键值对:
- Key: tablePrefix{TableID}_recordPrefixSep{RowID}
- Value: [col1, col2, col3, col4]
假定我们的tablePrefix是常量字符t,recordPrefixSep是常量字符r,我们的tableId是1,rowID在这里是我们的主键假定是100,如果有一个用户表的数据,如下:
- Key: t1_r100
- Value: [100, "zhangsan"]
如果我们的主键为整数的情况下,那么上面也可以看作是我们的主键索引,如果我们的主键不为整型或者说在唯一索引的情况下,规则编码如下:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
- Value: RowID
indexId是tidb为每个索引分配的ID,所以上面那个情况下一个indexedColumnsValue只能对应一条数据满足唯一性,如果是非唯一索引,我们可以有:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowId
- Value: null
这样一个indexedColumnsValue就可以有多行数据,所以其实我们region中的数据的索引并不会和region的数据再一起,而是有自己的region分片,同样的我们查询数据的时候需要依靠我们的tidb-server分析出来我们应该用什么样的索引,先根据索引数据查询出来rowId再根据rowId查询出来我们对应的数据。
总结
不管是tidb还是分布式数据库,要学习的知识还有非常的多,上面只是对tidb做了一些粗解的分析,如果大家要学习可以看看下面的一些资料:
pingcap文档: https://docs.pingcap.com, ping cap的文档是我见过做得算是比较顶级的文档了,他可以说不叫做文档,其实是一个文章知识库,我的文章很多图和内容都是借鉴而来。
极客时间《分布式数据库》:极客时间有一个课叫分布式数据库,不会局限于讲tidb,主要讲解的是分布式数据库的各种知识,并且会列举市场上的分布式数据库做对比。
《数据库系统内幕》:豆瓣评分8.5,这本书讲解了很多数据库理论基本知识,不论上分布式数据库还是单机数据库都会使用到,稍微有一点难懂,但是还是会有不少收获。