2021年7月9日,第四届人工智能大会在上海火热持续,全球AI领域产学研各界大佬在此云集,突破300家科技企业在线下深度参与。一场名为“AI时代数据开放共享”的创新论坛将数据生态新活力引入高潮。AI创新明星企业格物钛受邀出席,创始人兼CEO崔运凯发表主题演讲,从全球视野分享格物钛对于未来AI创新格局的看法,以及开源软件和开放数据对于未来格局的影响。崔运凯表示:“开源软件让科技创业变得可能,如果说在AI时代数据就相当于代码,那么开源数据之于AI的影响力和作用,丝毫不亚于开源软件之于应用的影响力和作用。”

以下为格物钛创始人兼CEO崔运凯演讲全文:
各位领导和嘉宾们,大家上午好。我是格物钛的创始人兼CEO崔运凯。很高兴受到上海白玉兰开源开放研究院的邀请,有机会跟大家分享格物钛对于未来AI创新格局的看法,和开源软件及开放数据对于这个格局的影响。
在分享开头,我想和大家讲几个创业故事。第一个创业故事就是马克·扎克伯格创立Facebook的故事。大家都知道扎克伯格是在大学的宿舍里写了第一版Facebook的程序。但是大家可能不知道的是他使用了PHP编程语言、使用了MySQL数据库,和Linux操作系统来为他的服务做托管。而这里的PHP、MySQL和Linux都是开源软件。
第二个创业故事我要分享的是一家国内非常知名的企业,张一鸣的今日头条。张一鸣创业的时候就要幸运得多,有更多的技术可以使用。比如说消息队列,他们使用了Kafka,大数据分析系统用了Hadoop,数据库用了MongoDB,内存加速使用了Redis。同样的,这些也都是开源软件。
跟大家分享上面两个故事实际上是想引出我们对于过去20年科技创新驱动力的观察,那就是开源软件让科技创业变得可能。没有开源软件,全球就不会有这么多科技公司的涌现,更不会有这么多便捷的产品,丰富我们的生活。

然而科技还在继续进步,工作和生活的组织形式还在不断进化。我们从PC互联网时代,进入到了移动互联网时代,再进而向着人工智能的时代进化。如果说软件开源是PC和移动时代创新的动力,那么什么是AI时代的创新动力呢?这是我们不断在思考并且追问自己的。我想用另外几个故事,引出我们对这个问题的答案。
第一个故事发生在计算机视觉领域。2009年斯坦福的李菲菲教授发布了一个公开数据集,这个数据叫ImageNet。它的发表推动了计算机视觉的飞速发展。这个数据集包含1400百万张图片,发布至今被引用了29000多次。而今天大家体验到的人工智能热潮,其实也是被一篇叫AlexNet的论文带起来的。通过使用卷积神经网络,它大规模地提升了计算机视觉识别算法的性能。更是比排名第二的算法的精确度高了40%。
第二个故事我想跟大家分享的发生在自然语言处理领域。斯坦福大学的科学家Jure在2013年发布了一个叫做亚马逊评论的公开数据集。这个数据集涵盖了从1994年到2013年在亚马逊网站上的一共一亿四千三百万条评论。这个数据集的发表也极大推动了自然语言处理领域的创新。图灵奖获得者Yann LeCun也将卷积神经网络模型应用在了这个数据及上,取得了非常不错的效果。他不仅推动了算法的发展,也推动了算力的发展。英伟达在2018年完成了LSTM(长短记忆模型)在整个数据集上的训练,这个训练用了分布式的显卡资源,只用了4个小时。而之前训练同样的模型,需要数月时间。
同样的故事也发生在语音处理领域。TIMIT数据集的发表,让因素识别模型的预测准确性从过去10年的78%提高到了92.85%。最近几年火热的无人驾驶也有很多类似的例子,比如说KITT数据集。KITTI数据集的诞生和基于KITTI数据集做的大量算法的研究,为今天无人驾驶的发展奠定了基础。
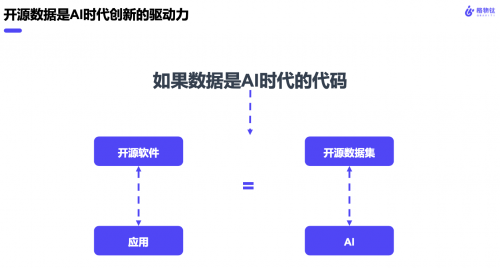
刚刚讲了这么多在AI不同领域的驱动力故事,实际上是想引出我们对于什么是AI时代创新驱动力的回答——那就是开源数据。如果说在AI时代,数据就相当于代码;那么开源数据之于AI的影响力和作用,丝毫不亚于开源软件之于应用的影响力和作用。
虽然开源数据将会成为未来驱动AI创新的核心驱动力,但并不意味着开源一个数据集就是一件简单的事情。我们观察到做数据开源至少有四个痛点:
1、协议痛点:数据和软件一样,都有版权,但是开源数据并不像开源软件那样有相对标准的协议;
2、运营痛点:当一个数据集开放后,运营以这个数据集为核心的社区,并吸引足够多的关注者,也是一件非常有挑战的事情;
3、数据标准:数据以什么样的格式向公众开放,方便社区成员使用,其实也没有通用的国际标准。最后数据的开放方还要开发并提供SDK,才能让用户方便使用开放的数据;
4、资金来源:ImageNet从想法到最后的发布,历时3年才最终完成,这里少不了数据的采集、清洗、标注等工作,而所有这些工作都需要资金的支持,才能完成。而如何筹措这些资金,可能会成为数据开源的影响因素。
中国的数据开源又有一些自身的独特点,其中包括但不限于:
中国的数据开源起步比较晚。现在世界知名的公开数据集基本都是海外机构发布和分享的。国内只有最近几年才开始有学术机构和企业开始做类似的尝试。比如说去年年底由我们格物钛发起的寻集令计划,就是其中的尝试之一;
虽然中国AI应用有大量的场景,但是现在国内机构和企业发布的公开数据却没有涵盖那么多场景。丰富度还是远远不足的;
同时国内的从业者,或者是场景的拥有方,对于数据开放的认识不足,或对于创新应用没有规划,也是导致现在国内开放数据不足的重要原因。
在这次活动中发布的《木兰-白玉兰开放数据许可协议》标志着一个很好的开始,也推动着中国的数据开源迈出了非常重要的一步。我们坚信开发数据协议的发布和推广,可以很好地降低数据开源的壁垒。在海外,开源软件的协议已经标准化,并整合进三个标准的协议,MIT、BSD和GPL,但是开源数据协议却没有一个统一的标注,处在多个协议并存的阶段。这为数据的开放增加了很多难度。
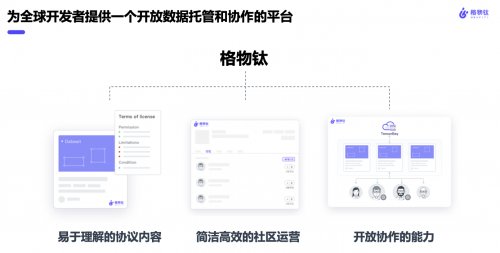
刚才讲了这么多数据开源的挑战和痛点,我也想借此机会分享格物钛在做哪些事情,如何帮助全球的AI社区解决这些痛点。格物钛为全球开发者、场景和数据的拥有者提供了一个开放数据托管和协作的平台。我们支持开源数据在我们平台上的免费托管。不仅如此,我们为数据的拥有者可以更好地运营社区,开发了很多产品的功能,包括开源数据协议结构化和可视化,方便数据集的使用者快速了解自己使用数据的权限。同时我们有很多和社区交互相关的功能和版块,方便数据集的拥有者直接并且快速地提供社区支持,和激发社区的贡献活跃。最后我们提供了团队协作能力,方便社区用户可以一起完成开源数据相关的任务。这一切的功能,都是希望将开源数据的发布和使用的门槛降低。
格物钛的产品帮助企业和数据的拥有者降低了开源数据的门槛,但是真正让企业做出开放数据决定的,还是要让企业清楚如何通过开源数据获得成功。我们分析了大量开源数据和开源软件的案例,发现开源数据至少可以在如下5个方面帮助企业获得成功:
1、帮助企业发现积累数据的新创新应用,帮助企业可以拓宽产品线或者改善现有产品,提供更好的用户体验;
2、发现新的商业机会,包括销售线索的获得;
3、帮助将企业内部的标准推动成全社区的标准,因为一个数据被使用的多了,它的组织形式就会成为事实的标准;
4、帮助企业吸引人才,优秀的人才会因为数据的应用潜力而加入一家公司,或者公司可以发现社区中最具有潜力的人才;
5、提升公司品牌,比如你在做无人驾驶,你发布的数据集中有大量的长尾场景,例如突然过马路的小动物,这些场景被识别并被追踪,会让用户体会到品牌带来的安全感。
在我演讲的最后,我想分享一些我对数据开源和AI行业未来的一点看法。AI行业正在由以模型为中心的开发模式,向着以数据为中心的开发模式迁移。在未来以数据为中心的开发模式中,数据必然会扮演越来越重要的角色。开源数据从来都不是呼吁企业开源全部数据,而是将一部分场景中的一部分数据进行开源。即便是其中很小的一部分场景化的数据被开源,也会给AI的发展带来巨大价值。
我想借此机会发出呼吁:格物钛希望和大家一起出发,通过开放更多的数据和创造更活跃的社区,来改变未来基于人工智能的全球创新。谢谢大家!