













本文转载自微信公众号「JavaKeeper」,作者海星。转载本文请联系JavaKeeper公众号。
干过服务端开发的应该都知道 Redis 的 ZSet 使用跳表实现的(当然还有压缩列表、哈希表),我就不从 1990 年的那个美国大佬 William Pugh 发表的那篇论文开始了,直接开跳
文章拢共两部分
- 跳表是怎么搞的
- Redis 是怎么想的
一、跳表
跳表的简历
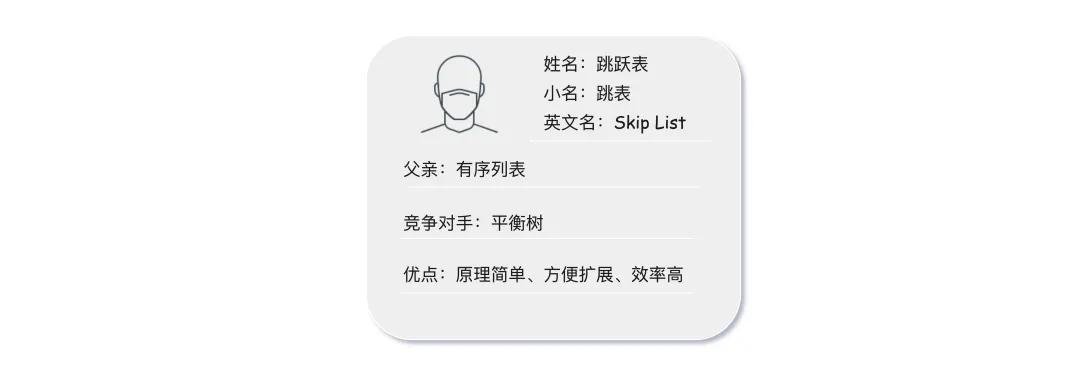
跳表,英文名:Skip List
父亲:从英文名可以看出来,它首先是个 List,实际上,它是在有序链表的基础上发展起来的
竞争对手:跳表(skip list)对标的是平衡树(AVL Tree)
优点:是一种 插入/删除/搜索 都是 的数据结构。它最大的优势是原理简单、容易实现、方便扩展、效率更高
跳表的基本思想
一如往常,采用循序渐进的手法带你窥探 William Pugh 的小心思~
前提:跳表处理的是有序的链表,所以我们先看个不能再普通了的有序列表(一般是双向链表)

如果我们想查找某个数,只能遍历链表逐个比对,时间复杂度 ,插入和删除操作都一样。
为了提高查找效率,我们对链表做个”索引“

像这样,我们每隔一个节点取一个数据作为索引节点(或者增加一个指针),比如我们要找 31 直接在索引链表就找到了(遍历 3 次),如果找 16 的话,在遍历到 31的时候,发现大于目标节点,就跳到下一层,接着遍历~ (蓝线表示搜索路径)
恩,如果你数了下遍历次数,没错,加不加索引都是 4 次遍历才能找到 16,这是因为数据量太少,
数据量多的话,我们也可以多建几层索引,如下 4 层索引,效果就比较明显了

每加一层索引,我们搜索的时间复杂度就降为原来的
加了几层索引,查找一个节点需要遍历的节点个数明线减少了,效率提高不少,bingo~
有没有似曾相识的感觉,像不像二分查找或者二叉搜索树,通过索引来跳过大量的节点,从而提高搜索效率。
这样的多层链表结构,就是『跳表』了~~
那到底提高了多少呢?
推理一番:
- 如果一个链表有 n 个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是 n/2,第二级索引的结点数大约为 n/4,以此类推第 m 级索引的节点数大约为 。
- 假如一共有 m 级索引,第 m 级的结点数为两个,通过上边我们找到的规律,那么得出 ,从而求得 m=-1。如果加上原始链表,那么整个跳表的高度就是 。
- 我们在查询跳表的时候,如果每一层都需要遍历 k 个结点,那么最终的时间复杂度就为 。
- 那这个 k 值为多少呢,按照我们每两个结点提取一个基点建立索引的情况,我们每一级最多需要遍历两个节点,所以 k=2。
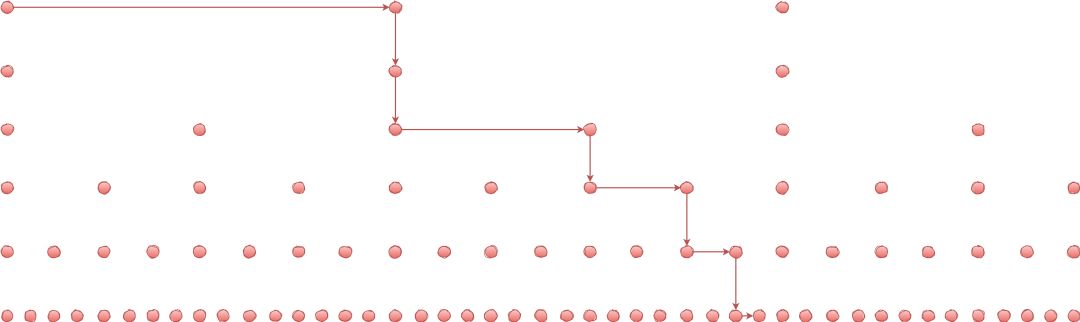
为什么每一层最多遍历两个结点呢?
因为我们是每两个节点提取一个节点建立索引,最高一级索引只有两个节点,然后下一层索引比上一层索引两个结点之间增加了一个结点,也就是上一层索引两结点的中值,看到这里是不是想起了二分查找,每次我们只需要判断要找的值在不在当前节点和下一个节点之间就可以了。
不信,你照着下图比划比划,看看同一层能画出 3 条线不~~
5.既然知道了每一层最多遍历两个节点,那跳表查询数据的时间复杂度就是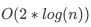 ,常数 2 忽略不计,就是
,常数 2 忽略不计,就是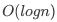 了。
了。
空间换时间
跳表的效率比链表高了,但是跳表需要额外存储多级索引,所以需要更多的内存空间。
跳表的空间复杂度分析并不难,如果一个链表有 n 个节点,每两个节点抽取出一个节点建立索引的话,那么第一级索引的节点数大约就是 n/2,第二级索引的节点数大约为 n/4,以此类推第 m 级索引的节点数大约为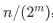 ,我们可以看出来这是一个等比数列。
,我们可以看出来这是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2,所以跳表的空间复杂度为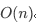 。
。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
插入数据
其实插入数据和查找一样,先找到元素要插入的位置,时间复杂度也是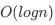 ,但有个问题就是如果一直往原始列表里加数据,不更新我们的索引层,极端情况下就会出现两个索引节点中间数据非常多,相当于退化成了单链表,查找效率直接变成
,但有个问题就是如果一直往原始列表里加数据,不更新我们的索引层,极端情况下就会出现两个索引节点中间数据非常多,相当于退化成了单链表,查找效率直接变成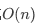

跳表索引动态更新
我们上边建立索引层都是下层节点个数的 1/2,最高层索引的节点数就是 2 个,但是我们随意插入或者删除一个原有链表的节点,这个比例就肯定会被破坏。
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中节点多了,索引节点就相应地增加一些,避免复杂度退化。
如果重建索引的话,效率就不能保证了。
如果你了解红黑树、AVL 树这样平衡二叉树,你就知道它们是通过左右旋的方式保持左右子树的大小平衡,而跳表是通过随机函数来维护前面提到的“平衡性”。
所以跳表(skip list)索性就不强制要求 1:2 了,一个节点要不要被索引,建几层的索引,就随意点吧,都在节点插入时由抛硬币决定。
比如我们要插入新节点 X,那要不要为 X 向上建索引呢,就是抛硬币决定的,正面的话建索引,否则就不建了,就是这么随意(比如一个节点随机出的层数是 3,那就把它链入到第1 层到第 3 层链表中,也就是我们除了原链表的之外再往上 2 层索引都加上)。
其实是因为我们不能预测跳表的添加和删除操作,很难用一种有效的算法保证索引部分始终均匀。学过概率论的我们都知道抛硬币虽然不能让索引位置绝对均匀,当数量足够多的时候最起码可以保证大体上相对均匀。
删除节点相对来说就容易很多了,在索引层找到节点的话,就顺藤摸瓜逐个往下删除该索引节点和原链表上的节点,如果哪一层索引节点被删的就剩 1 个节点的话,直接把这一层搞掉就可以了。
其实跳表的思想很容易理解,可是架不住实战,我们接着看实战
跳表的实现
差不多了解了跳表,其实就是加了几层索引的链表,一共有 N 层,以 0 ~ N 层表示,设第 0 层是原链表,抽取其中部分元素,在第 1 层形成新的链表,上下层的相同元素之间连起来;再抽取第 1 层部分元素,构成第 2 层,以此类推。
Leetcode 的题目:设计跳表(https://leetcode-cn.com/problems/design-skiplist/)
既然是链表结构,先搞个 Node
- class Node{
- Integer value; //节点值
- Node[] next; // 节点在不同层的下一个节点
- public Node(Integer value,int size) { // 用size表示当前节点在跳表中索引几层
- this.value = value;
- this.next = new Node[size];
- }
- }
增删改查来一套,先看下增加节点,上边我们已经知道了,新增时候会随机生成一个层数,看下网上大佬的解释
执行插入操作时计算随机数的过程,是一个很关键的过程,它对 skiplist 的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
首先,每个节点肯定都有第 1 层指针(每个节点都在第 1 层链表里)。
如果一个节点有第 i 层(i>=1)指针(即节点已经在第 1 层到第 i 层链表中),那么它有第(i+1)层指针的概率为 p。
节点最大的层数不允许超过一个最大值,记为 MaxLevel。
这个计算随机层数的代码如下所示:
- int randomLevel()
- int level = 1;
- while (Math.random()<p && level<MaxLevel){
- level ++ ;
- }
- return level;
randomLevel() 包含两个参数,一个是 p,一个是 MaxLevel。在 Redis 的 skiplist 实现中,这两个参数的取值为:
- p = 1/4
- MaxLevel = 32(5.0版本以后是64)
所以我们和 Redis 一样的设置
- /**
- * 最大层数
- */
- private static int DEFAULT_MAX_LEVEL = 32;
- /**
- * 随机层数概率,也就是随机出的层数,在 第1层以上(不包括第一层)的概率,层数不超过maxLevel,层数的起始号为1
- */
- private static double DEFAULT_P_FACTOR = 0.25;
- /**
- * 头节点
- */
- Node head = new Node(null, DEFAULT_MAX_LEVEL);
- /**
- * 表示当前nodes的实际层数,它从1开始
- */
- int currentLevel = 1;
增
我觉得我写的注释还挺通俗易懂的(代码参考了 leetcode 和 王争老师的实现)
- public void add(int num) {
- int level = randomLevel();
- Node newNode = new Node(num,level);
- Node updateNode = head;
- // 计算出当前num 索引的实际层数,从该层开始添加索引,逐步向下
- for (int i = currentLevel-1; i>=0; i--) {
- //找到本层最近离num最近的节点(刚好比它小的节点)
- while ((updateNode.next[i])!=null && updateNode.next[i].value < num){
- updateNode = updateNode.next[i];
- }
- //本次随机的最高层才设值,如果是最后一个直接指向newNode,否则将newNode 链入链表
- if (i<level){
- if (updateNode.next[i]==null){
- updateNode.next[i] = newNode;
- }else{
- Node temp = updateNode.next[i];
- updateNode.next[i] = newNode;
- newNode.next[i] = temp;
- }
- }
- }
- //如果随机出来的层数比当前的层数还大,那么超过currentLevel的head 直接指向newNode
- if (level > currentLevel){
- for (int i = currentLevel; i < level; i++) {
- head.next[i] = newNode;
- }
- //更新层数
- currentLevel = level;
- }
- }
删
- public boolean erase(int num) {
- boolean flag = false;
- Node searchNode = head;
- //从最高层开始遍历找
- for (int i = currentLevel-1; i >=0; i--) {
- //和新增一样也需要找到离要删除节点最近的辣个
- while ((searchNode.next[i])!=null && searchNode.next[i].value < num){
- searchNode = searchNode.next[i];
- }
- //如果有这样的数值
- if (searchNode.next[i]!=null && searchNode.next[i].value == num){
- //找到该层中该节点,把下一个节点过来,就删除了
- searchNode.next[i] = searchNode.next[i].next[i];
- flag = true;
- }
- }
- return flag;
- }
查
- public Node search(int target) {
- Node searchNode = head;
- for (int i = currentLevel - 1; i >= 0; i--) {
- while ((head.next[i]) != null && searchNode.next[i].value < target) {
- searchNode = searchNode.next[i];
- }
- }
- if (searchNode.next[0] != null && searchNode.next[0].value == target) {
- return searchNode.next[0];
- } else {
- return null;
- }
- }
二、Redis 为什么选择跳表?
跳表本质上也是一种查找结构,我们经常遇到的查找问题最常见的就是哈希表,还有就是各种平衡树,跳表又不属于这两大阵营,那问题来了:
为什么 Redis 要用跳表来实现有序集合,而不是哈希表或者平衡树(AVL、红黑树等)?
Redis 中的有序集合是通过跳表来实现的,严格点讲,其实还用到了压缩列表、哈希表。
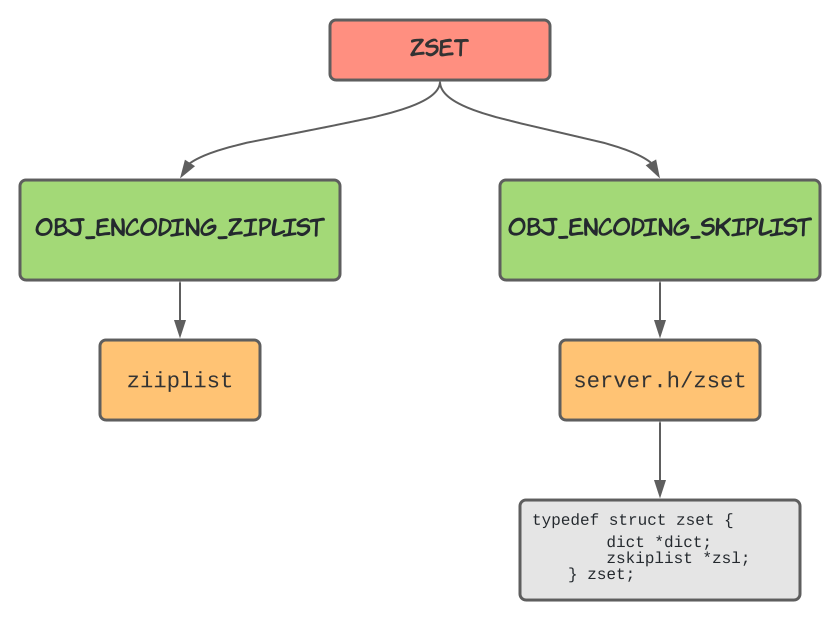
Redis 提供了两种编码的选择,根据数据量的多少进行对应的转化 (源码地址 )
- 当数据较少时,ZSet 是由一个 ziplist 来实现的
- 当数据多的时候,ZSet 是由一个 dict + 一个 skiplist 来实现的。简单来讲,dict 用来查询数据到分数的对应关系,而 skiplist 用来根据分数查询数据(可能是范围查找)。
Redis 的跳跃表做了些修改
- 允许有重复的分值
- 对元素的比对不仅要比对他们的分值,还要比对他们的对象
- 每个跳跃表节点都带有一个后退指针,它允许程序在执行像 ZREVRANGE 这样的命令时,从表尾向表头遍历跳跃表。
我们先看下 ZSet 常用的一些命令
| 命令 | 描述 |
|---|---|
| ZADD | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZCARD | 返回有序集 key 的基数 |
| ZREM | 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略 |
| ZSCAN | 迭代有序集合中的元素(包括元素成员和元素分值) |
| ZREVRANGE | 返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减(从大到小)来排列 |
主要操作就是增删查一个数据,迭代数据、按区间查数据,看下原因
- 哈希表是无序的,且只能查找单个 key,不适宜范围查找
- 插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高(跳表只需要定位区间的起点,然后遍历就行了)
- Redis 选跳表实现有序集合,还有其他各种原因,比如代码实现相对简单些,且更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
扯点别的 | 这又是为什么?
有序集合的英文全称明明是sorted sets,为啥叫 zset 呢?
Redis官网上没有解释,但是在 Github 上有人向作者提问了。作者是这么回答的哈哈哈
Hello. Z is as in XYZ, so the idea is, sets with another dimension: the order. It’s a far association… I know ??
原来前面的 Z 代表的是 XYZ 中的Z,最后一个英文字母,zset 是在说这是比 set 有更多一个维度的 set ??
是不没道理?
更没道理的还有,Redis 默认端口 6379 ,因为作者喜欢的一个叫 Merz 的女明星,其名字在手机上输入正好对应号码 6379,索性就把 Redis 的默认端口叫 6379 了…
小结
跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。
跳表是一种动态数据结构,支持快速地插入、删除、查找操作,时间复杂度都是 。
Redis 的 zset 是一个复合结构,一方面它需要一个 hash 结构来存储 value 和 score 的对应关系,另一方面需要提供按照 score 来排序的功能,还需要能够指定 score 的范围来获取 value 列表的功能
Redis 中的有序集合是通过压缩列表、哈希表和跳表的组合来实现的,当数据较少时,ZSet 是由一个 ziplist 来实现的。当数据多的时候,ZSet 是由一个dict + 一个 skiplist 来实现的
后续:MySQL 的 Innodb ,为什么不用 skiplist,而用 B+ Tree ?
参考
ftp://ftp.cs.umd.edu/pub/skipLists/skiplists.pdf 原论文
Redis内部数据结构详解(6)——skiplist 图文并茂讲解 skip list
https://leetcode-cn.com/problems/design-skiplist/
https://lotabout.me/2018/skip-list/
https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html
https://redisbook.readthedocs.io/en/latest/datatype/sorted_set.html#sorted-set-chapter




















