本文转载自微信公众号「Python中文社区」,作者巩庆奎。转载本文请联系Python中文社区公众号。
背景
作为一个程序员,经常需要阅读英文论文、文档、书籍。对于一些基础不好的同学来说,最主要的拦路虎是英语单词。计算机类文档不同于小说,其语法、句式都比较简单,可以说只要词汇量有了,阅读就很简单。
如果能在平时提高词汇量,那是最好不过了。鸡汤警告!你必须暗自努力,然后惊艳所有人!这句话打在这里没毛病吧,老铁。但无所侧重地背普通英语字典,恐怕效率并不高。不提前学习单词,直接上手阅读,遇到生词再查,效率也提升不起来。
这里介绍一个针对专业文档背单词的方法:把当前文档的所有单词,建立一个专属字典,先背诵这个字典,再去看书,一定能一目十行。
思路
总体思路是文件分词统计,查找字典,生成新字典。
- 首先,有一个需要阅读的英文文档,给它分词,按照单词频率排序;
- 找一个已掌握的英语词汇表(四六级或考研等),把上文中的单词和本词汇表重复的项删除;
- 再找一个词汇量大的字典,在其中查找对应解释;
- 把结果存储到一个字典文件中。
得到的字典,就是这本书的专属字典了。业余背这个字典,相当于掌握了计算机专业英语。这个方法也适用于机械、电子等等任何专业英语的地方。
实现
下面,以 Python 神作《Fluent Python》为例,用 Python 自带的库实现分词、统计功能。首先看下它的内容梗概。
- Fluent Python
- CLEAR, CONCISE, AND EFFECTIVE PROGRAMMING
- Luciano Ramalho
- ......
分词
首先来分词。
- from collections import Counter
- import re
- ct2 = Counter()
- patt = re.compile(r'\w+')
- with open('f1.txt','r',encoding='utf-8') as f:
- for l in f.readlines():
- ws = (n.lower() for n in patt.findall(l))
- ct2.update(ws)
以上代码中,导入了 Counter 和 re 模块。
Counter 负责统计单词词频,re 正则表达式分割英语单词。得到结果 ct2 中是所有单词的词频。
下面,把它保存下来。
- with open('result_f1.txt','w',encoding='utf-8') as f:
- f.write(''.join(('%s %s\n'%(a,b) for a,b in ct2.most_common())))
现在,result_f1.txt 中存储的是这本书出现的单词,而且是按照词频排序的,如下。
- the 12414
- a 5639
- of 4900
- in 4837
- to 4689
- is 3848
- ......
和预想得很像,排名靠前的基本是介词等常用词。
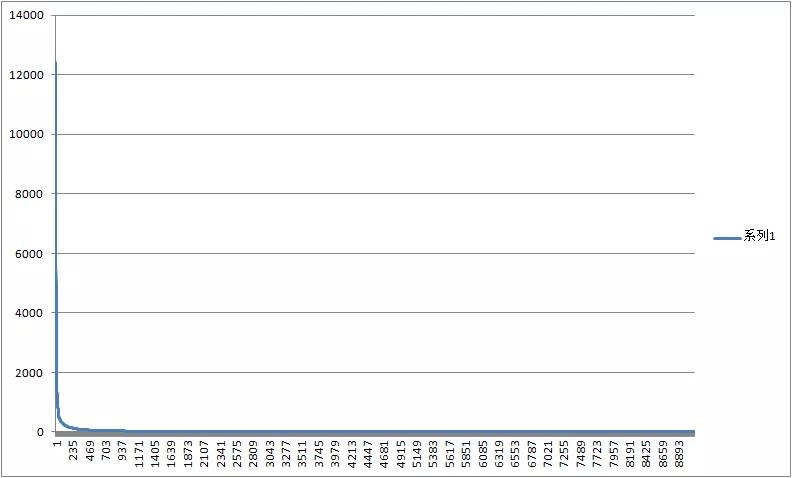
另外,比较有意思的数据是,《Fluent Python》共使用词汇 9118 个,其中出现一次的单词有 3168 个。出现频次最高的 the 达到 12000 次。它的分布图如下。
载入字典
下载一个比较全的字典,十万个单词。载入内存,存储在字典数据变量 dicts 中。
- 这是 dict 结构第一次真正存储字典!
- dicts = dict()
- with open('103976.txt','r',encoding='gbk') as f:
- for l in f.readlines():
- k = l[0:l.find('\t')]
- v = l[l.find('\t')+1:]
- dicts.update({k:v})
删除认识的单词
字典当中大量的 the a is,相当挑战我们的容忍度,这让旁人看了,还以为我们小学没毕业呢。去掉去掉……
众所周知,我们采用了小学二年级就掌握的 postgrade.txt 英文字典。
- postgrade.txt 同学们肯定耳熟能详。神奇的是第一个单词。abandon vt.离弃,丢弃;遗弃,抛弃;放弃
- with open('postgrade.txt','r',encoding='utf-8') as f:
- f.readline()
- for l in f.readlines():
- k = l[:l.find(' ')]
- try:
- del dicts[k]
- except KeyError as e:
- pass
现在,字典 dicts 中,仅仅剩下所我们不认识的,103976 - 5000 = 98976 个单词了。
生成新字典
以词频单词来查找单词表,再把单词和释义存到新单词表中,就得到新单词表了。
- with open('f1_res.txt','w',encoding='utf-8') as wf,open('result_f1.txt','r',encoding='utf-8')as f:
- for l in f.readlines():
- k = l[:l.find(' ')]
- v = dicts.get(k,None)
- if v:
- wf.write('%s %s'%(k,v))
- wf.close()
这里第一句,两个 with 可以写到一句话里。这样代码看起来比较和谐。
查字典方法,使用v = dicts.get(k,None),这样查不着的单词,返回 None,写入新字典时判断这个值,就可以了。
总结
除此处介绍的生生单个文档字典外,还可多拿几个领域专业文档,提取它们的常用单词,然后生成专属字典,这字典,相当于相关领域的专业英语字典。
这里使用 Python 自带库写程序,效率可能不高。如果需要,可以使用 pandas 之类的库来实现,提高效率。
作者:巩庆奎,大奎,对计算机、电子信息工程感兴趣。