













早在苏美尔王国时期,这个智慧王国的子民就开始记录数据,进行人口普查、分配粮食。
全世界最早产生的文明之一苏美尔的人口普查记录
苏美尔人贡献了书面数据分析的最早记录。
随着计算机的出现,人们开始用机器分析大型数据集,这一阶段最早可以追溯到大型计算机时代。
计算机大大加快了数据分析的速度,被广泛应用在审计和人口普查上。
而这种将大量数据分析与社会问题相结合的工作,即计算社会科学(Computational social science)近年来得到了巨大的发展。
巨大的发展伴随的是没有限制、不受监管的数据收集。

这其中存在很大风险:缺乏监控以及从匿名数据中重新识别身份的风险。
还有人担心,收集数据却没有征得当事人的同意怎么办?
大部分数据都被少数大型科技公司垄断怎么办?
不仅大型科技公司掌握数据、数据使用权在向发达国家、富裕人群倾斜,这样做出的决策难免会有偏差。
所以,目前需要我们将社会科学和不同学科以及收集分析大型数据集所需的技能结合起来,这就需要跨学科的合作。
但是,目前跨学科合作面临诸多挑战。
今天,Nature就以特刊形式讨论了目前计算社会科学面临的挑战和机遇。

克服跨学科的语言障碍
计算社会科学集社会、自然、计算科学等学科于一身。
同一个词,在不同学科之间可能有不同的含义,在这种情况下就很容易「鸡同鸭讲」。
例如,在社会科学领域,「预测」(prediction)通常含有「相关」的意思;而在物理科学领域,这个词更多指的是「预测」。
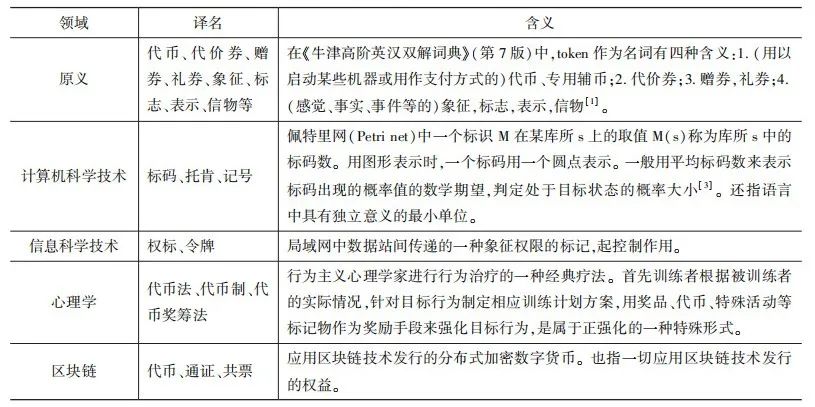
「token」在不同领域里也有不同含义
因此,不同学科之间需要克服同一术语表达不同意思的语言障碍。开展跨学科研究时,科学家们首先需要学会彼此的语言,然后得出一种能够相互理解的术语。
但比起语言障碍,更难的是如何展示、分析和解释数据,最终解释某种现象。
比方说,要想了解交通拥堵的原因,研究人员会收集并预测交通流量数据,还会从司机口中了解到他们选择特定路线的原因。计算社会科学的学科互补特性,能更高效地回答研究问题。
处理数据的「大忌」
所有研究结果取决于分析策略,还取决于数据的质量,在处理社会数据的时候更是如此。
要想完成计算社会科学的研究,就先得要有大量的数据,如手机的定位信息。但是这些信息通常不是出于研究目的才收集的,因此很容易被人误解。
仅从数字中观察到趋势或模式中就得出结论,这是研究人员处理大数据集的「大忌」。研究人员应该考虑可能会影响结果的因素。
为了提取数据的真正意义,研究人员需要确保他们根据理论,仔细地定义测量对象,并适当地进行验证和解释。
算法的广泛影响是另一个潜在错误。算法遍及整个社会,以不同的方式影响着个人和群体行为,这意味着,所有的观察不仅在描述人类行为,还在描述算法对人们行为方式的影响。
社会科学理论需要更新,承认算法带来的影响;要是没有这些理论,没有清晰理解算法对可用数据的影响,研究人员就无法得出有意义的结论。
共享数据的难处
大型数据集通常是商企的私有财产,这是计算社会科学的另一个复杂问题。搞学术的科学家需要跟企业联系才能获得访问权限,这有可能会产生更多偏见。
对于公司而言,数据是有价值的,因此共享数据会冒犯到公司的「底线」。这也是公司倾向于限制共享内容的原因之一。
但考虑到这些数据能提供社会效益,公司——连同学术研究人员和公共机构——需要共同解决这些问题,并为数据的质量、数据访问和数据所有权制定标准。
未来获取数据的方式
一篇关于「人类社会感知」的文章对于如何获得有用、可靠的数据列举了一些方法。这是对个人如何在其社交网络中收集他人信息的研究。
例如,研究人员可以通过采访对象并询问他们的朋友在谈论什么,从而预测出政治观点的变化。
收集他人的数据有助于避免自我报告数据中出现的一些偏见,生成匿名数据也有额外好处:研究人员永远不需要知道他们获得的数据中,任何有关个人或敏感细节的信息。
获取数据的方式变得更加成熟,这一点体现在传染病建模和行为科学的交叉领域。
要建立准确的传染和感染模型,研究人员需要了解患病人群的文化和行为。如果不考虑传播的这些和其他社会方面的传播因素,就难以预测疾病的传播路径。跨学科的结构和广泛合作十分关键。
而新冠肺炎疫情已经表明,大规模数据集应用于科学能够挽救生命。随着具有计算机科学或应用数学背景的研究人员与社会科学家的合作,而这种潜力才刚刚开始显现。
























