本文转载自微信公众号「数据和云」,作者王鑫。转载本文请联系数据和云公众号。
一、前言
这几天在对PostgreSQL流复制的架构进行深入研究,其中一个关键的参数:recovery_min_apply_delay引起了我的注意,设置该参数的大概意思是:在进行流复制的时候,备库会延迟主库recovery_min_apply_delay的时间进行应用。比如说,我们在主库上insert10条数据,不会立即在备库上生效,而是在recovery_min_apply_delay的时间后,备库才能完成应用。
另外,我们知道在PostgreSQL中,其mvcc机制并不像Oracle或者MySQL一样,将旧版本数据存放在另外的空间中,而是通过对事务号(xid)的控制对旧版本数据不可见的方式进行实现。所以PostgreSQL中无法实现类似于Oracle的闪回机制。
在日常操作过程中,对表进行delete、truncate、drop等误操作都不能通过闪回来快速恢复。不怕一万,就怕万一,在做数据库维护的6年多里,遇到过的误操作还是很多。那么在PostgreSQL这种无法实现闪回的数据库中,如果出现误操作如何快速恢复呢?
二、架构简介
对于PostgreSQL数据库这种无法进行闪回的数据库来讲,最常用的办法就是通过备份+归档的方式进行数据恢复。但是这种恢复方式也有弊端,当数据库非常大时,恢复全量备份也会非常的慢,而且如果全量备份是一周前或者更久前的,那么恢复归档也会需要比较长的时间。这段时间内,可能业务就会长时间停摆,造成一定的损失。
如果通过流复制延迟特性作为生产数据库的容灾库,则可以从一定程度上解决该问题,其简单架构如下:
三、恢复步骤
PostgreSQL流复制容灾库架构的误操作恢复步骤如下:
1.主库出现误操作,查看流复制的replay状态;
2.在recovery_min_apply_delay时间内,暂停备库的replay;
3.判断主库出现的误操作类型(delete/truncate/drop);
4.根据主库误操作类型,对备库进行相应的操作;
5.通过pg_dump将误操作表导出;
6.在主库对pg_dump出的表进行恢复。
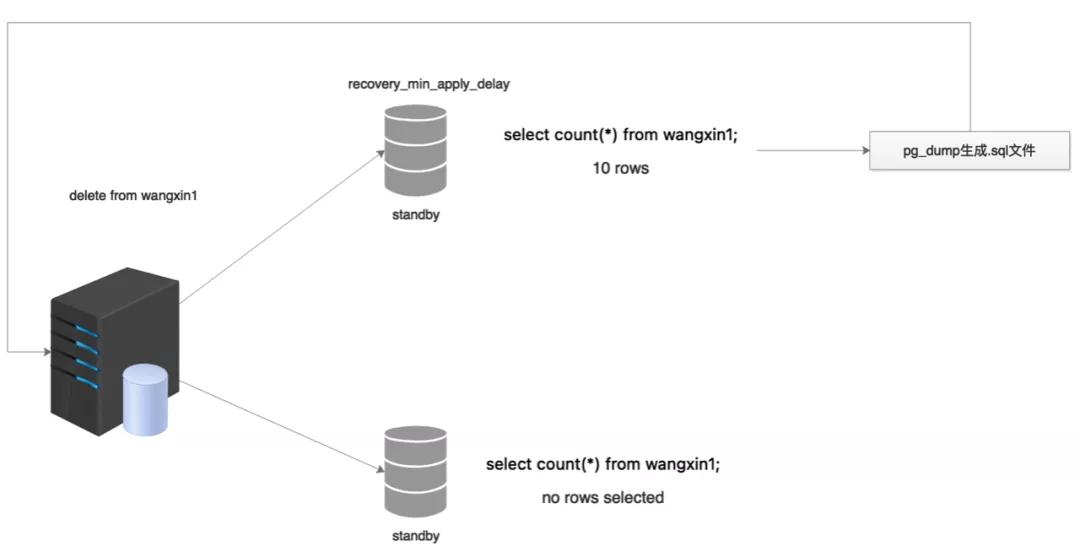
假设当前备库与主库相差10min,则误操作可以分为以下两个场景:
1)delete操作:
首先我们需要知道的是,针对delete操作,PostgreSQL会给相关表加一个ROW EXCLUSIVE锁,而该锁不会对select等dql操作进行阻塞。
所以当我们在主库进行delete误操作后,备库则会晚10min中进行replay。且此时可以对该表进行查询和pg_dump的导出。针对于主库delete误操作,恢复步骤如下:
第一步,查看流复制replay的状态,重点关注replay_lsn字段:
select * from pg_stat_replication;
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 55694
usesysid | 24746
usename | repl
application_name | walreceiver
client_addr | 192.168.18.82
client_hostname |
client_port | 31550
backend_start | 2021-01-20 09:54:57.039779+08
backend_xmin |
state | streaming
sent_lsn | 6/D2A17120
write_lsn | 6/D2A17120
flush_lsn | 6/D2A17120
replay_lsn | 6/D2A170B8
write_lag | 00:00:00.000119
flush_lag | 00:00:00.000239
replay_lag | 00:00:50.653858
sync_priority | 0
sync_state | async
reply_time | 2021-01-20 14:11:31.704194+08
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
此时可以发现数据库中的replay_lsn字段的lsn值要比sent_lsn/write_lsn/flush_lsn都要小;
第二步,为了防止处理或者导出时间过慢而导致的数据同步,立即暂停备库的replay:
select * from pg_wal_replay_pause();
- 1.
查看同步状态:
postgres=# select * from pg_is_wal_replay_paused();
pg_is_wal_replay_paused
-------------------------
t
(1 row)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
第三步,在备库查看数据是否存在:
select * from wangxin1;
- 1.
第四步,通过pg_dump,将表内容导出:
pg_dump -h 192.168.18.182 -p 18802 -d postgres -U postgres -t wangxin1 --data-only --inserts -f wangxin1_data_only.sql
- 1.
第五步,在主库执行sql文件,将数据重新插入:
psql -p 18801
\i wangxin1_data_only.sql
- 1.
- 2.
恢复即完成。
2)truncate和drop:
这里首先需要知道的是,truncate和drop操作会给表加上一个access exclusive锁,该类型锁是PostgreSQL数据库中最严重的锁。如果表上有该锁,则会阻止所有对该此表的访问操作,其中也包括select和pg_dump操作。
所以说,在我们对主库中的某张表进行truncate或者drop后,同样,备库会由于recovery_min_apply_delay参数比主库晚完成truncate或drop动作10min(从参数理论上是这样理解的,但实际并不是)。
那么针对truncate和drop的恢复过程我们也参考delete的方式来进行:
-[ RECORD 2 ]----+------------------------------
pid | 67008
usesysid | 24746
usename | repl
application_name | walreceiver
client_addr | 192.168.18.82
client_hostname |
client_port | 32122
backend_start | 2021-01-20 23:33:05.538858+08
backend_xmin |
state | streaming
sent_lsn | 7/3F0593E0
write_lsn | 7/3F0593E0
flush_lsn | 7/3F0593E0
replay_lsn | 7/3F059330
write_lag | 00:00:00.000141
flush_lag | 00:00:00.000324
replay_lag | 00:00:11.471699
sync_priority | 0
sync_state | async
reply_time | 2021-01-20 23:33:58.303686+08
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
接下来,为防止处理或导出时间过慢而导致的数据同步,应立即暂停备库的replay:
select * from pg_wal_replay_pause();
- 1.
查看同步状态:
postgres=# select * from pg_is_wal_replay_paused();
pg_is_wal_replay_paused
-------------------------
t
(1 row)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
接着,在备库查看数据是否存在:
select * from wangxin1;
- 1.
但是,此时就会发现问题:数据无法select出来,整个select进程会卡住(pg_dump也一样):
^CCancel request sent
ERROR: canceling statement due to user request
- 1.
- 2.
此时,可以对备库上的锁信息进行查询:
select s.pid,
s.datname,
s.usename,
l.relation::regclass,
s.client_addr,
now()-s.query_start,
s.wait_event,
s.wait_event_type,
l.granted,
l.mode,
s.query
from pg_stat_activity s ,pg_locks l
where s.pid<>pg_backend_pid()
and s.pid=l.pid;
pid | datname | usename | relation | client_addr | ?column? | wait_event | wait_event_type | granted | mode | query
-------+---------+---------+----------+-------------+----------+--------------------+-----------------+---------+---------------------+-------
55689 | | | | | | RecoveryApplyDelay | Timeout | t | ExclusiveLock |
55689 | | | wangxin1 | | | RecoveryApplyDelay | Timeout | t | AccessExclusiveLock |
(2 rows)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
发现此时truncate的表被锁住了,而pid进程则是备库的recover进程,所以此时我们根本无法访问该表,也就无法做pg_dump操作了。
因此,想要恢复则必须想办法将数据库还原到锁表之前的操作。于是对PostgreSQL的wal日志进行分析查看:
pg_waldump -p /pgdata/pg_wal -s 7/3F000000
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F050D70, prev 7/3F050D40, desc: RUNNING_XACTS nextXid 13643577 latestCompletedXid 13643576 oldestRunningXid 13643577
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643577, lsn: 7/3F050DA8, prev 7/3F050D70, desc: NEW_CID rel 1663/13593/2619; tid 20/27; cmin: 4294967295, cmax: 0, combo: 4294967295
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643577, lsn: 7/3F050DE8, prev 7/3F050DA8, desc: NEW_CID rel 1663/13593/2619; tid 20/23; cmin: 0, cmax: 4294967295, combo: 4294967295
rmgr: Heap len (rec/tot): 65/ 6889, tx: 13643577, lsn: 7/3F050E28, prev 7/3F050DE8, desc: HOT_UPDATE off 27 xmax 13643577 flags 0x00 ; new off 23 xmax 0, blkref #0: rel 1663/13593/2619 blk 20 FPW
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643577, lsn: 7/3F052930, prev 7/3F050E28, desc: NEW_CID rel 1663/13593/2619; tid 20/28; cmin: 4294967295, cmax: 0, combo: 4294967295
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643577, lsn: 7/3F052970, prev 7/3F052930, desc: NEW_CID rel 1663/13593/2619; tid 20/24; cmin: 0, cmax: 4294967295, combo: 4294967295
rmgr: Heap len (rec/tot): 76/ 76, tx: 13643577, lsn: 7/3F0529B0, prev 7/3F052970, desc: HOT_UPDATE off 28 xmax 13643577 flags 0x20 ; new off 24 xmax 0, blkref #0: rel 1663/13593/2619 blk 20
rmgr: Heap len (rec/tot): 53/ 7349, tx: 13643577, lsn: 7/3F052A00, prev 7/3F0529B0, desc: INPLACE off 13, blkref #0: rel 1663/13593/1259 blk 1 FPW
rmgr: Transaction len (rec/tot): 130/ 130, tx: 13643577, lsn: 7/3F0546D0, prev 7/3F052A00, desc: COMMIT 2021-01-20 23:31:23.009466 CST; inval msgs: catcache 58 catcache 58 catcache 50 catcache 49 relcache 24780
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F054758, prev 7/3F0546D0, desc: RUNNING_XACTS nextXid 13643578 latestCompletedXid 13643577 oldestRunningXid 13643578
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F054790, prev 7/3F054758, desc: RUNNING_XACTS nextXid 13643578 latestCompletedXid 13643577 oldestRunningXid 13643578
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 7/3F0547C8, prev 7/3F054790, desc: CHECKPOINT_ONLINE redo 7/3F054790; tli 1; prev tli 1; fpw true; xid 0:13643578; oid 33072; multi 1; offset 0; oldest xid 479 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 13643578; online
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F054840, prev 7/3F0547C8, desc: RUNNING_XACTS nextXid 13643578 latestCompletedXid 13643577 oldestRunningXid 13643578
rmgr: Standby len (rec/tot): 42/ 42, tx: 13643578, lsn: 7/3F054878, prev 7/3F054840, desc: LOCK xid 13643578 db 13593 rel 24780
rmgr: Storage len (rec/tot): 42/ 42, tx: 13643578, lsn: 7/3F0548A8, prev 7/3F054878, desc: CREATE base/13593/24885
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643578, lsn: 7/3F0548D8, prev 7/3F0548A8, desc: NEW_CID rel 1663/13593/1259; tid 1/13; cmin: 4294967295, cmax: 0, combo: 4294967295
rmgr: Heap2 len (rec/tot): 60/ 60, tx: 13643578, lsn: 7/3F054918, prev 7/3F0548D8, desc: NEW_CID rel 1663/13593/1259; tid 1/14; cmin: 0, cmax: 4294967295, combo: 4294967295
rmgr: Heap len (rec/tot): 65/ 7537, tx: 13643578, lsn: 7/3F054958, prev 7/3F054918, desc: UPDATE off 13 xmax 13643578 flags 0x00 ; new off 14 xmax 0, blkref #0: rel 1663/13593/1259 blk 1 FPW
rmgr: Heap2 len (rec/tot): 76/ 76, tx: 13643578, lsn: 7/3F0566E8, prev 7/3F054958, desc: CLEAN remxid 13642576, blkref #0: rel 1663/13593/1259 blk 1
rmgr: Btree len (rec/tot): 53/ 3573, tx: 13643578, lsn: 7/3F056738, prev 7/3F0566E8, desc: INSERT_LEAF off 141, blkref #0: rel 1663/13593/2662 blk 2 FPW
rmgr: Btree len (rec/tot): 53/ 5349, tx: 13643578, lsn: 7/3F057530, prev 7/3F056738, desc: INSERT_LEAF off 117, blkref #0: rel 1663/13593/2663 blk 2 FPW
rmgr: Btree len (rec/tot): 53/ 2253, tx: 13643578, lsn: 7/3F058A30, prev 7/3F057530, desc: INSERT_LEAF off 108, blkref #0: rel 1663/13593/3455 blk 4 FPW
rmgr: Heap len (rec/tot): 42/ 42, tx: 13643578, lsn: 7/3F059300, prev 7/3F058A30, desc: TRUNCATE nrelids 1 relids 24780
rmgr: Transaction len (rec/tot): 114/ 114, tx: 13643578, lsn: 7/3F059330, prev 7/3F059300, desc: COMMIT 2021-01-20 23:33:46.831804 CST; rels: base/13593/24884; inval msgs: catcache 50 catcache 49 relcache 24780
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F0593A8, prev 7/3F059330, desc: RUNNING_XACTS nextXid 13643579 latestCompletedXid 13643578 oldestRunningXid 13643579
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 7/3F0593E0, prev 7/3F0593A8, desc: RUNNING_XACTS nextXid 13643579 latestCompletedXid 13643578 oldestRunningXid 13643579
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn:
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
从wal日志的分析中,可以非常明显的看到,在最后一次checkpoint点后(恢复的起始点),正常来说,数据库会继续执行lsn为7/3F054840的步骤开启事务,并在下一步lsn为7/3F054878的步骤直接对oid为24780(通过oid2name可以知道,这张表就是我们误操作表)的表进行lock操作,做一系列相关的操作后,进行了truncate,最后进行commit操作。
而这一系列操作,我们则可以认为是truncate一张表的正常操作。
由于我们知道checkpoint点是数据库的恢复起始点,那么我们是否可以将数据库恢复到这一点的lsn呢?此时的lsn肯定不会对表进行lock操作,那么我们就可以对该表进行pg_dump操作了。
想法是好的,但是实际操作则没那么顺利。我们可以通过对备库PostgreSQL的配置文件进行修改,加入参数:
- recovery_target_lsn= ‘7/3F0547C8’
- recovery_target_action= ‘pause’
重启数据库。
此时却发现数据库无法启动,通过对日志查看,发现原因竟然是:

这个恢复点,是一致性恢复点之前的点,所以无法正常恢复。
此时就出现了令我们奇怪的点,我们知道checkpoint的两个主要作用是:将脏数据进行刷盘;将wal日志的checkpoint进行记录。此时,肯定是数据库一致的点,但是为什么会报不一致呢?
经过一点一点的尝试,发现能够恢复的lsn点,只有truncate或者drop的commit操作的前面。那么这样我们还是无法对误操作表进行解锁。
最后,只能通过一种方式,即pg_resetwal的方式,强制指定备库恢复到我们想要的lsn点:
pg_resetwal -D data1 -x 559 Write-ahead log reset
再进行pg_dump即可。
但是,此时PostgreSQL的主备流复制关系已经被破坏,只能重新搭建或者以其他方式进行恢复(比如pg_rewind)。
四、问题分析
再次返回到进行truncate或drop的恢复步骤中,我们可以发现一个问题,为什么在checkpoint点后、truncate点前,无法将数据库恢复到一致点呢?为什么会报错呢?

按照常理来讲,checkpoint点就是恢复数据库的起始点,也是一致点,但是却无法恢复了。
继续进行详细的探究后发现一个现象:
延迟流复制过程中,我们配置了recovery_min_apply_delay参数,对源端数据库做truncate后,备库replay的lsn,停留在truncate表后的commit操作。而从主库的pg_stat_replication的replay_lsn值来看,此时备库的recover进程,应该就是在执行最后的commit的lsn;
更形象的来说,此时备库类似于我执行以下命令:
begin;
truncate table;
- 1.
- 2.
- 3.
也就是说,此时我并没有提交,而备库也正在等待我进行提交,所以此时误操作表会被锁定。
但实际上,truncate table这个动作,已经在我的备库上进行了replay,只是最后的commit动作没有进行replay。因此,对于truncate动作之前所有lsn的操作已经是我当前数据库状态的一个过去式,无法恢复了,故会报错。
为了验证想法,在大佬的帮助下,又对PostgreSQL的源码进行查看,发现猜想原因确实没错:
在/src/backend/access/transam/xlog.c中,对于recovery_min_apply_delay参数有以下的一段描述:
/*
* Is it a COMMIT record?
*
* We deliberately choose not to delay aborts since they have no effect on
* MVCC. We already allow replay of records that don't have a timestamp,
* so there is already opportunity for issues caused by early conflicts on
* standbys.
*/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
大概意思是,当record中没有时间戳(timestamp)的时候,数据库就已经进行了replay。replay只会等待有时间戳的record,而所有的record中,只有commit操作有时间戳,故replay会等待一个commit操作。
不过在实际的生产环境中,我们通常会把recovery_min_apply_delay参数设置的较大,而在这之间,一般都会有一些其他的事务进行操作,当主库出现误操作(哪怕说truncate/drop),只要及时发现,我们可以暂停replay的步骤,停在正常的事务操作下,此时误操作的表的事务还没有执行,那么这个容灾库还是比较有作用的。