现今的多语言翻译模型,大多是在一个以英语为中心的数据集上训练一个统一的模型,并通过添加语言标签的方式来告诉模型应该翻译到哪一种语言。这种模型在预测的时候能够直接在一个非英语的句子上添加另一个非英语的语言标签来直接翻译,从而达到即使在训练时没有见过源语言和目标语言的情况下,也能实现模型翻译,这就是所谓的 zero-shot 多语言翻译。
添加语言标签的方式有很多种,来自火山翻译团队的研究者通过实验研究发现,虽然不同的语言标签对监督方向的效果几乎没有影响,但是对 zero-shot 的效果却有着非常大的影响。这个现象在多个数据集上得到了验证,其中 IWSLT17 上相差 14.02 个 BLEU,Euporal 上相差 24.24 个 BLEU,TED talks 上相差 8.78 个 BLEU。目前该研究已被 the findings of ACL 2021 接收。

论文地址:https://arxiv.org/abs/2106.07930
研究背景和动机
在多语言翻译中,有许多添加语言标签的方法,并且一般都认为不同的语言标签的添加方法对模型的性能没有影响,然而之前没有研究者系统性地研究语言标签对翻译模型是否有影响。这篇文章比较了四种常见的语言标签的添加方法。
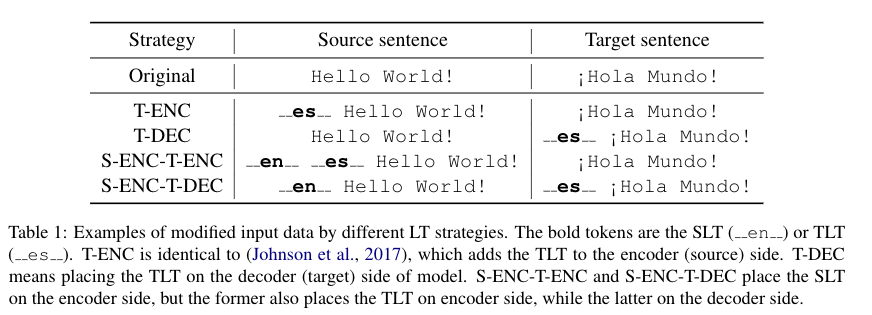
表 1 四种不同的的语言标签
如表 1 所示,这四种方法会将源语言标签和目标语言标签按照不同的方法加到源句首或者目标句首。
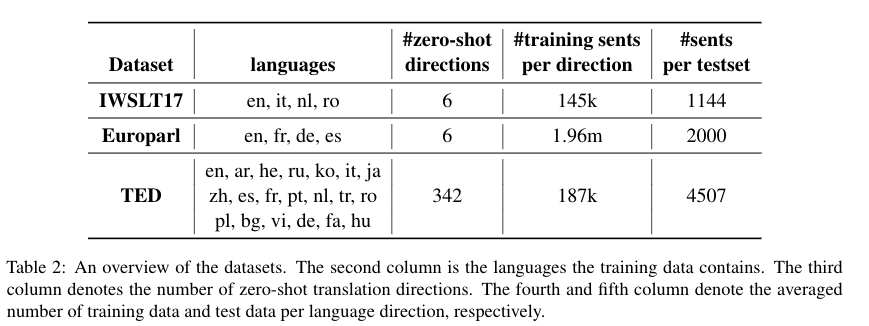
表 2 数据集详情
如表 2 所示,这篇文章选择了 IWSLT17,Euporal 和 TED talks 三个数据集,这三个数据集在语言数量和数据集大小上都有比较大的差异。这篇文章在这三个数据集上基于上述四种不同的语言标签训练了配置完全一样的多语言翻译模型。
实验结果
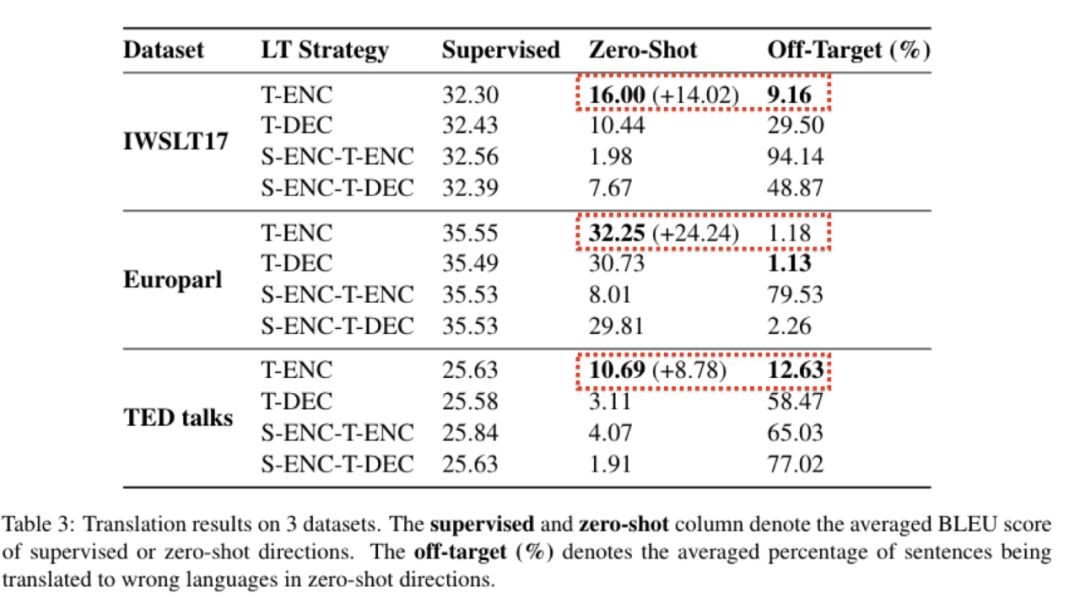
表 3 实验结果
如表 3 所示,可以看到:
1. 对于不同的语言标签,不同的数据集,在有监督的方向上,模型的表现基本一致。
2. 在 Zero-shot 方向上:
a. 不同的语言标签对模型的性能有着很大的影响,并且,T-ENC 的表现在三种数据集上一致地超过了其他三种标签:在 IWSLT17 上超过了 14.02 个 BLEU,在 Euporal 上超过了 24.24 个 BLEU,在 TED talks 上超过了 8.78 个 BLEU。
b. 不同语言标签导致的 off-target 的比例也不相同(off-target 是指翻译到语言 X 时,却翻译成另一个语言的情况),基本上 T-ENC 的 off-target 的比例都要比别的小,这一点和模型在 zero-shot 上的性能基本一致。
分析
那么是什么原因导致了这种现象?这篇文章试图从三个方面解释这个现象并在 TED 数据集上做了实验:
1. 在目标语言相同的情况下,语言标签的添加方式是否影响了不同语言的句子经过 Encoder 之后的表示的一致性?
2. T-ENC 可以获得相对于其他方法更小的 off-target 比例,是不是由于在预测的时候,它的 attention 注意力机制能够更好地注意到语言标签?
3. 意思相同的不同语言的句子,在翻译模型的每一层的相似性如何?
Encoder 的表示的一致性
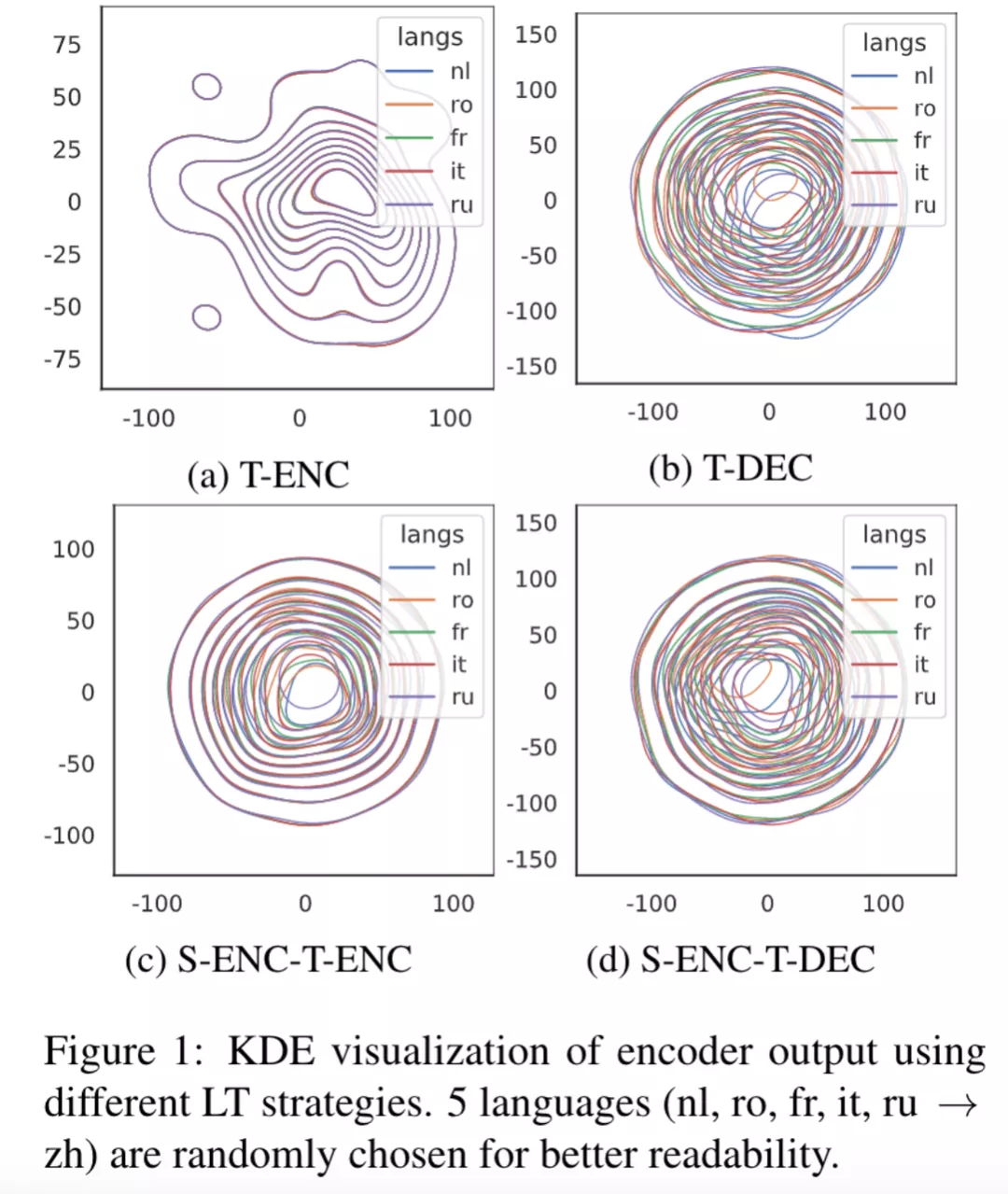
上图是通过对 Encoder 的输出使用 t-SNE 降维,之后使用 kde 画出来的分布图,展示了不同语言的句子在目标语言相同的情况下的分布,可以发现 T-ENC 不同语言之间的 Encoder 表示分布更加一致。这表明,T-ENC 能够帮助模型学习到语言无关的 Encoder 表示。
缓解 off-target 的问题
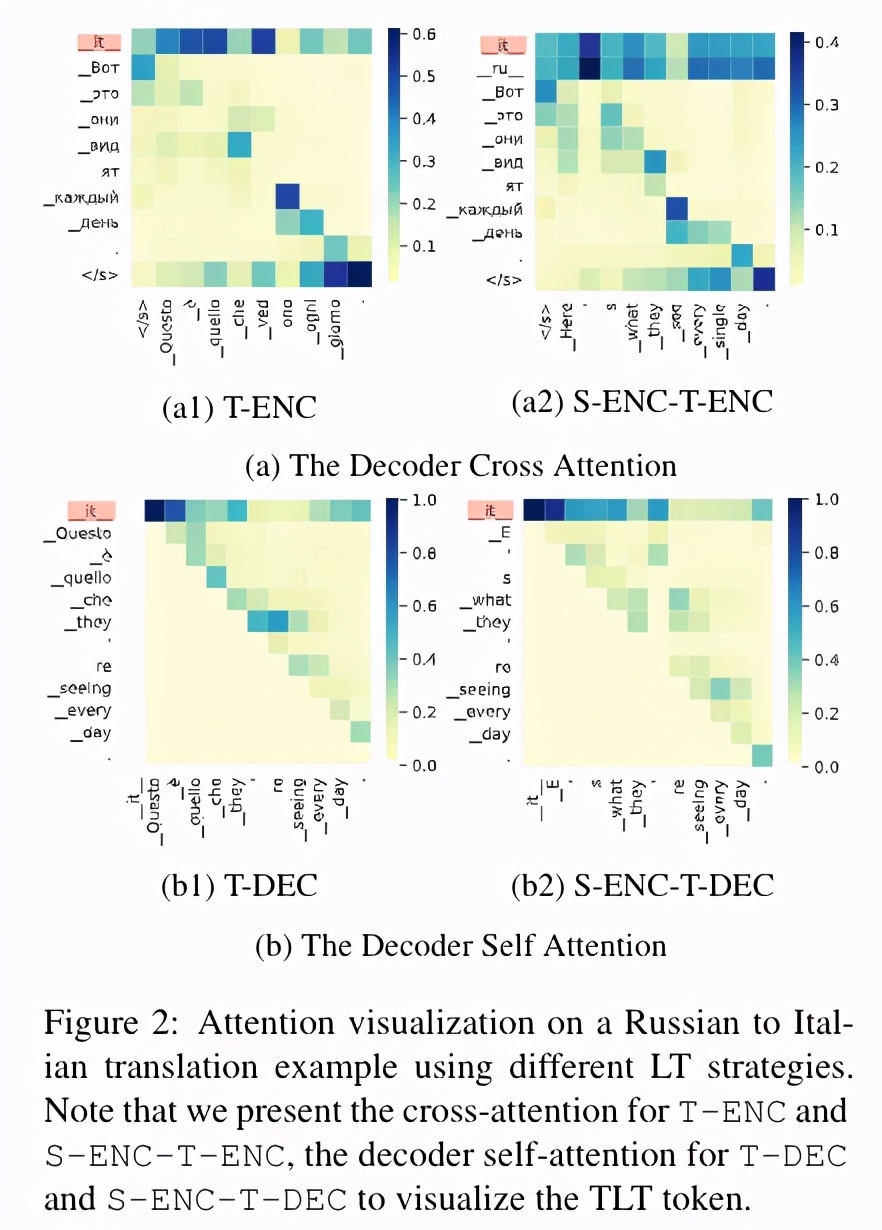
上图通过一个 case study 展示了从一个俄语句子翻译到意大利语句子时,不同的语言标签下,模型的 attention 对意大利语标签的 “关注” 程度,显然使用 T-ENC 时,模型对意大利语标签的关注程度最高,这可以一定程度上解释为什么 T-ENC 拥有最小的 off-target 比例。
不同层的相似性
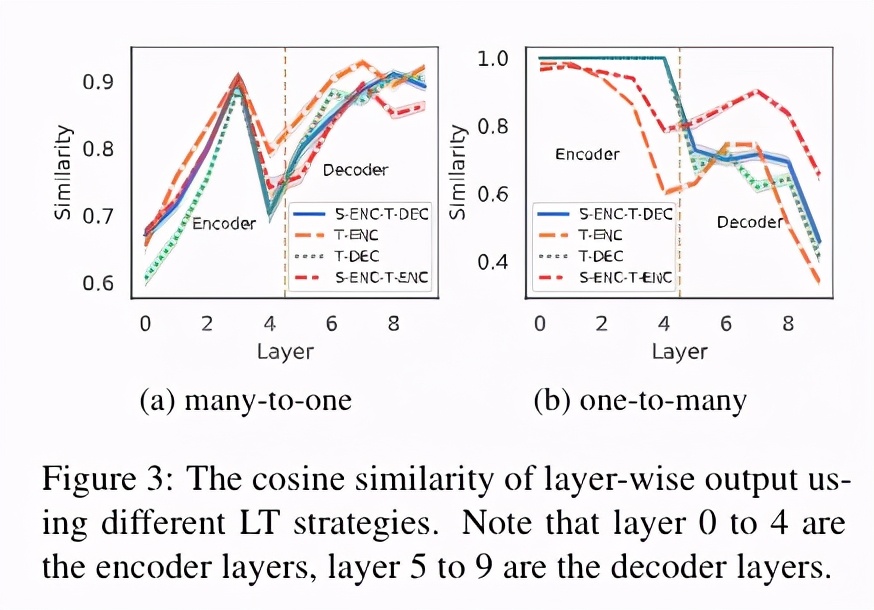
上图的子图 a 展示了,从除了英语和俄语外的 18 个语言翻译到俄语的时候,意思相同的句子在不同语言之间的表示的相似性,可以看到 T-ENC 的相似性曲线一直在其他的语言标签之上,这表明在目标语言相同的时候,T-ENC 各层的表示相比于其他的方法都有更好的一致性。
上图的子图 b 展示了,从俄语翻译到除了英语和俄语外的 18 个语言翻译的时候,同一个俄语句子在不同目标语言下的相似性,可以看到 T-ENC 的相似性曲线几乎一直在其他的语言标签下方,这表明,当目标语言不同的时候,T-ENC 能够更好的生成目标语言相关的表示。
总结
该研究发现了不同语言标签对多语言 Zero-shot 翻译的巨大影响,并在数据相差很大的三个不同的数据集上进行了实验,验证了不同语言标签对多语言 Zero-shot 翻译确实存在巨大影响,并且表明 T-ENC 在 Zero-shot 上优于其他语言标签。同时该研究还分析了不同语言标签对模型在预测时表示的影响,发现 T-ENC 能够更好地得到与目标语言相关而与源语言无关的表示:
1. T-ENC 能使不同源语言句子经过 Encoder 的表示更一致。
2. T-ENC 的注意力机制能够更好的注意到目标语言的语言标签。
3. T-ENC 在不同层的表示相对于其他方法与目标语言的相关性更强。