RocketMQ存储概要设计
RocketMQ主要存储的文件包括commitlog文件、consumeQueue文件、IndexFile文件。
CommitLog是消息存储文件,所有消息主题的消息都存储在CommitLog文件中;该文件默认最大为1GB,超过1GB后会轮到下一个CommitLog文件。通过CommitLog,RocketMQ将所有消息存储在一起,以顺序IO的方式写入磁盘,充分利用了磁盘顺序写减少了IO争用提高数据存储的性能。
RocketMQ的Broker机器磁盘上的文件存储结构

【CommitLog】
消息在CommitLog中的存储格式如下:
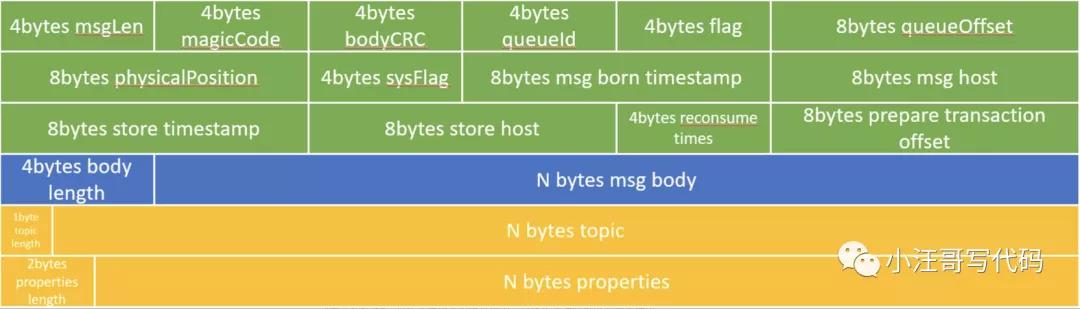
存储所有消息内容,写满一个文件后生成新的 commitlog 文件。所有 topic 的数据存储在一起,逻辑视图如下:

CommitLog代码
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- /**
- * MAGIC_CODE - MESSAGE
- * Message's MAGIC CODE daa320a7
- * 标记某一段为消息,即:[msgId, MESSAGE_MAGIC_CODE, 消息]
- */
- public final static int MESSAGE_MAGIC_CODE = 0xAABBCCDD ^ 1880681586 + 8;
- /**
- * MAGIC_CODE - BLANK
- * End of file empty MAGIC CODE cbd43194
- * 标记某一段为空白,即:[msgId, BLANK_MAGIC_CODE, 空白]
- * 当CommitLog无法容纳消息时,使用该类型结尾
- */
- private final static int BLANK_MAGIC_CODE = 0xBBCCDDEE ^ 1880681586 + 8;
- /**
- * 映射文件队列
- */
- private final MappedFileQueue mappedFileQueue;
- /**
- * 消息存储
- */
- private final DefaultMessageStore defaultMessageStore;
- /**
- * flush commitLog 线程服务
- */
- private final FlushCommitLogService flushCommitLogService;
- /**
- * If TransientStorePool enabled, we must flush message to FileChannel at fixed periods
- * commit commitLog 线程服务
- */
- private final FlushCommitLogService commitLogService;
- /**
- * 写入消息到Buffer Callback
- */
- private final AppendMessageCallback appendMessageCallback;
- /**
- * topic消息队列 与 offset 的Map
- */
- private HashMap<String/* topic-queue_id */, Long/* offset */> topicQueueTable = new HashMap<>(1024);
- /**
- * TODO
- */
- private volatile long confirmOffset = -1L;
- /**
- * 当前获取lock时间。
- * 如果当前解锁,则为0
- */
- private volatile long beginTimeInLock = 0;
- /**
- * true: Can lock, false : in lock.
- * 添加消息 螺旋锁(通过while循环实现)
- */
- private AtomicBoolean putMessageSpinLock = new AtomicBoolean(true);
- /**
- * 添加消息重入锁
- */
- private ReentrantLock putMessageNormalLock = new ReentrantLock(); // Non fair Sync
【ConsumeQueue】
ConsumeQueue是消息消费队列文件,消息达到commitlog文件后将被异步转发到消息消费队列,供消息消费者消费;一个ConsumeQueue表示一个topic的一个queue,类似于kafka的一个partition,但是rocketmq在消息存储上与kafka有着非常大的不同,RocketMQ的ConsumeQueue中不存储具体的消息,具体的消息由CommitLog存储,ConsumeQueue中只存储路由到该queue中的消息在CommitLog中的offset,消息的大小以及消息所属的tag的hash(tagCode),一共只占20个字节,整个数据包如下:
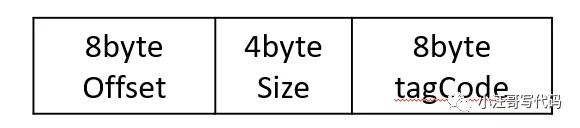
ConsumeQueue代码
- public static final int CQ_STORE_UNIT_SIZE = 20;
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- private static final Logger LOG_ERROR = LoggerFactory.getLogger(LoggerName.STORE_ERROR_LOGGER_NAME);
- private final DefaultMessageStore defaultMessageStore;
- /**
- * 映射文件队列
- */
- private final MappedFileQueue mappedFileQueue;
- /**
- * Topic
- */
- private final String topic;
- /**
- * 队列编号
- */
- private final int queueId;
- /**
- * 消息位置信息ByteBuffer
- */
- private final ByteBuffer byteBufferIndex;
- /**
- * 文件存储地址
- */
- private final String storePath;
- /**
- * 每个映射文件大小
- */
- private final int mappedFileSize;
- /**
- * 最大重放消息commitLog存储位置
- */
- private long maxPhysicOffset = -1;
- private volatile long minLogicOffset = 0;
Consume Queue文件组织,如图所示:

Consume Queue文件组织示意图
- 根据topic和queueId来组织文件,图中TopicA有两个队列0,1,那么TopicA和QueueId=0组成一个ConsumeQueue,TopicA和QueueId=1组成另一个ConsumeQueue。
- 按照消费端的GroupName来分组重试队列,如果消费端消费失败,消息将被发往重试队列中,比如图中的%RETRY%ConsumerGroupA。
- 按照消费端的GroupName来分组死信队列,如果消费端消费失败,并重试指定次数后,仍然失败,则发往死信队列,比如图中的%DLQ%ConsumerGroupA。
死信队列(Dead Letter Queue)一般用于存放由于某种原因无法传递的消息,比如处理失败或者已经过期的消息。
【IndexFile】
IndexFile是消息索引文件,主要存储的是key和offset的对应关系。
IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。
文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。
- private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
- private static int hashSlotSize = 4;
- private static int indexSize = 20;
- private static int invalidIndex = 0;
- private final int hashSlotNum;
- private final int indexNum;
- private final MappedFile mappedFile;
- private final FileChannel fileChannel;
- private final MappedByteBuffer mappedByteBuffer;
- private final IndexHeader indexHeader;
IndexFile的存储结构:
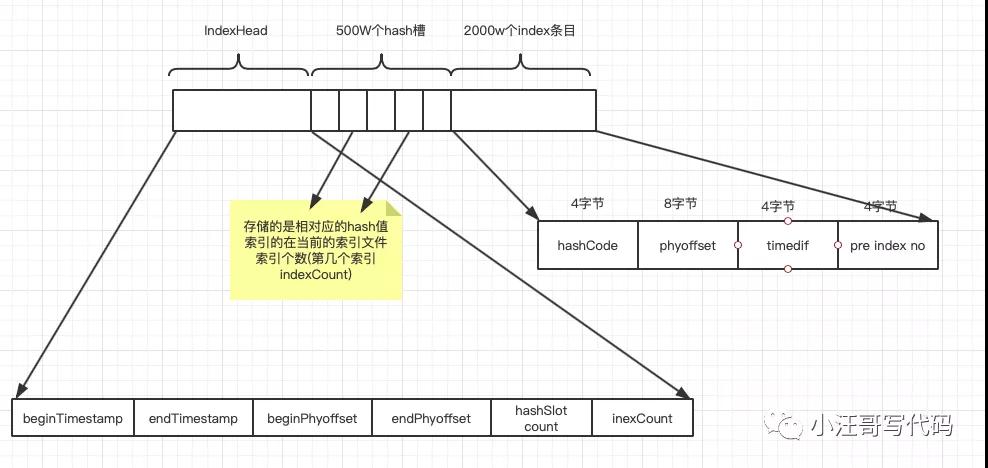
从上面的分析可以看出,RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个CommitLog中)针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中。
只要消息被刷盘持久化至磁盘文件CommitLog中,那么Producer发送的消息就不会丢失。
正因为如此,Consumer也就肯定有机会去消费这条消息。当无法拉取到消息后,可以等下一次消息拉取,同时服务端也支持长轮询模式,如果一个消息拉取请求未拉取到消息,Broker允许等待30s的时间,只要这段时间内有新消息到达,将直接返回给消费端。这里,RocketMQ的具体做法是,使用Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
【全局的角度来看消息的存储】
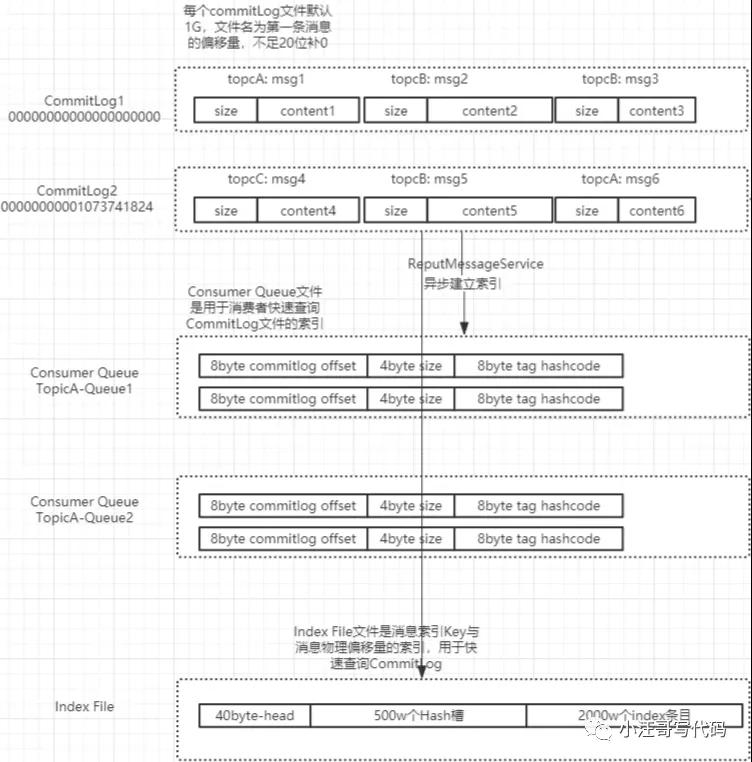
【消息存储流程】
Broker端收到消息后,将消息原始信息保存在CommitLog文件对应的MappedFile中,然后异步刷新到磁盘
ReputMessageServie线程异步的将CommitLog中MappedFile中的消息保存到ConsumerQueue和IndexFile中
ConsumerQueue和IndexFile只是原始文件的索引信息
内存映射和数据刷盘
【内存映射流程】
- 内存映射文件MappedFile通过AllocateMappedFileService创建
- MappedFile的创建是典型的生产者-消费者模型
- MappedFileQueue调用getLastMappedFile获取MappedFile时,将请求放入队列中
- AllocateMappedFileService线程持续监听队列,队列有请求时,创建出MappedFile对象
- 最后将MappedFile对象预热,底层调用force方法和mlock方法。
【刷盘机制】
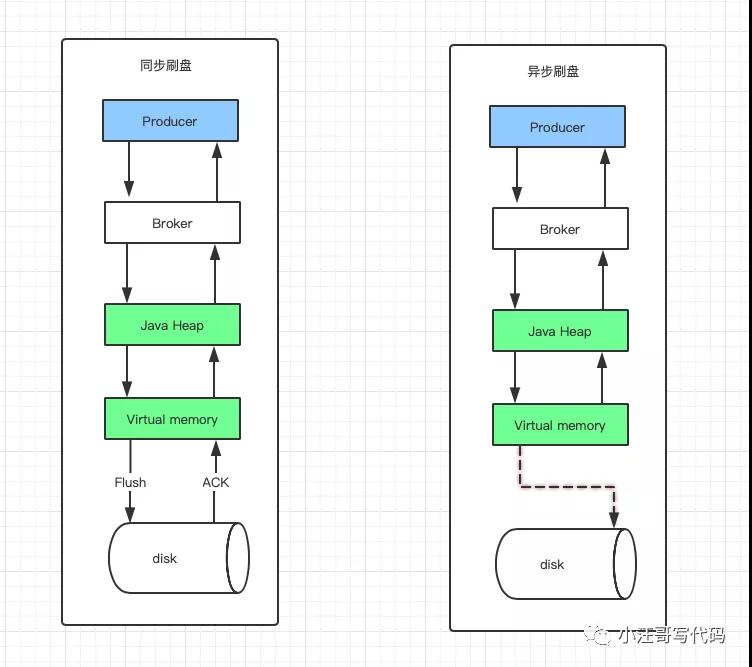
- 异步刷盘:消息被写入内存的PAGECACHE,返回写成功状态,当内存里的消息量积累到一定程度时,统一触发写磁盘操作,快速写入 。吞吐量高,当磁盘损坏时,会丢失消息
- 同步刷盘:消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,给应用返回消息写成功的状态。吞吐量低,但不会造成消息丢失。
【刷盘流程】
producer发送给broker的消息保存在MappedFile中,然后通过刷盘机制同步到磁盘中。
刷盘分为同步刷盘和异步刷盘。
异步刷盘后台线程按一定时间间隔执行。
同步刷盘也是生产者-消费者模型。broker保存消息到MappedFile后,创建GroupCommitRequest请求放入列表,并阻塞等待。后台线程从列表中获取请求并刷新磁盘,成功刷盘后通知等待线程。
RocketMQ 文件存储模型层次结构
文件存储模型层次结构图
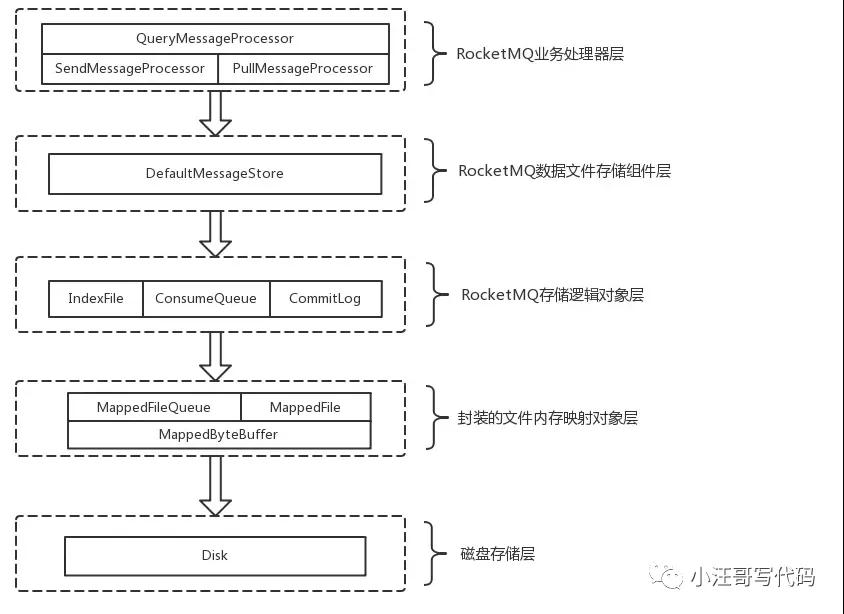
RocketMQ文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为5层,下面将从各个层次分别进行分析和阐述:
RocketMQ业务处理器层:Broker端对消息进行读取和写入的业务逻辑入口,比如前置的检查和校验步骤、构造MessageExtBrokerInner对象、decode反序列化、构造Response返回对象等;
RocketMQ数据存储组件层;该层主要是RocketMQ的存储核心类—DefaultMessageStore,其为RocketMQ消息数据文件的访问入口,通过该类的“putMessage()”和“getMessage()”方法完成对CommitLog消息存储的日志数据文件进行读写操作(具体的读写访问操作还是依赖下一层中CommitLog对象模型提供的方法);另外,在该组件初始化时候,还会启动很多存储相关的后台服务线程,包括AllocateMappedFileService(MappedFile预分配服务线程)、ReputMessageService(回放存储消息服务线程)、HAService(Broker主从同步高可用服务线程)、StoreStatsService(消息存储统计服务线程)、IndexService(索引文件服务线程)等;
RocketMQ存储逻辑对象层:该层主要包含了RocketMQ数据文件存储直接相关的三个模型类IndexFile、ConsumerQueue和CommitLog。IndexFile为索引数据文件提供访问服务,ConsumerQueue为逻辑消息队列提供访问服务,CommitLog则为消息存储的日志数据文件提供访问服务。这三个模型类也是构成了RocketMQ存储层的整体结构(对于这三个模型类的深入分析将放在后续篇幅中);
封装的文件内存映射层:RocketMQ主要采用JDK NIO中的MappedByteBuffer和FileChannel两种方式完成数据文件的读写。其中,采用MappedByteBuffer这种内存映射磁盘文件的方式完成对大文件的读写,在RocketMQ中将该类封装成MappedFile类。这里限制的问题在上面已经讲过;对于每类大文件(IndexFile/ConsumerQueue/CommitLog),在存储时分隔成多个固定大小的文件(单个IndexFile文件大小约为400M、单个ConsumerQueue文件大小约5.72M、单个CommitLog文件大小为1G),其中每个分隔文件的文件名为前面所有文件的字节大小数+1,即为文件的起始偏移量,从而实现了整个大文件的串联。这里,每一种类的单个文件均由MappedFile类提供读写操作服务(其中,MappedFile类提供了顺序写/随机读、内存数据刷盘、内存清理等和文件相关的服务);
磁盘存储层:主要指的是部署RocketMQ服务器所用的磁盘。这里,需要考虑不同磁盘类型(如SSD或者普通的HDD)特性以及磁盘的性能参数(如IOPS、吞吐量和访问时延等指标)对顺序写/随机读操作带来的影响;
文件存储的高可用
【分布式存储】
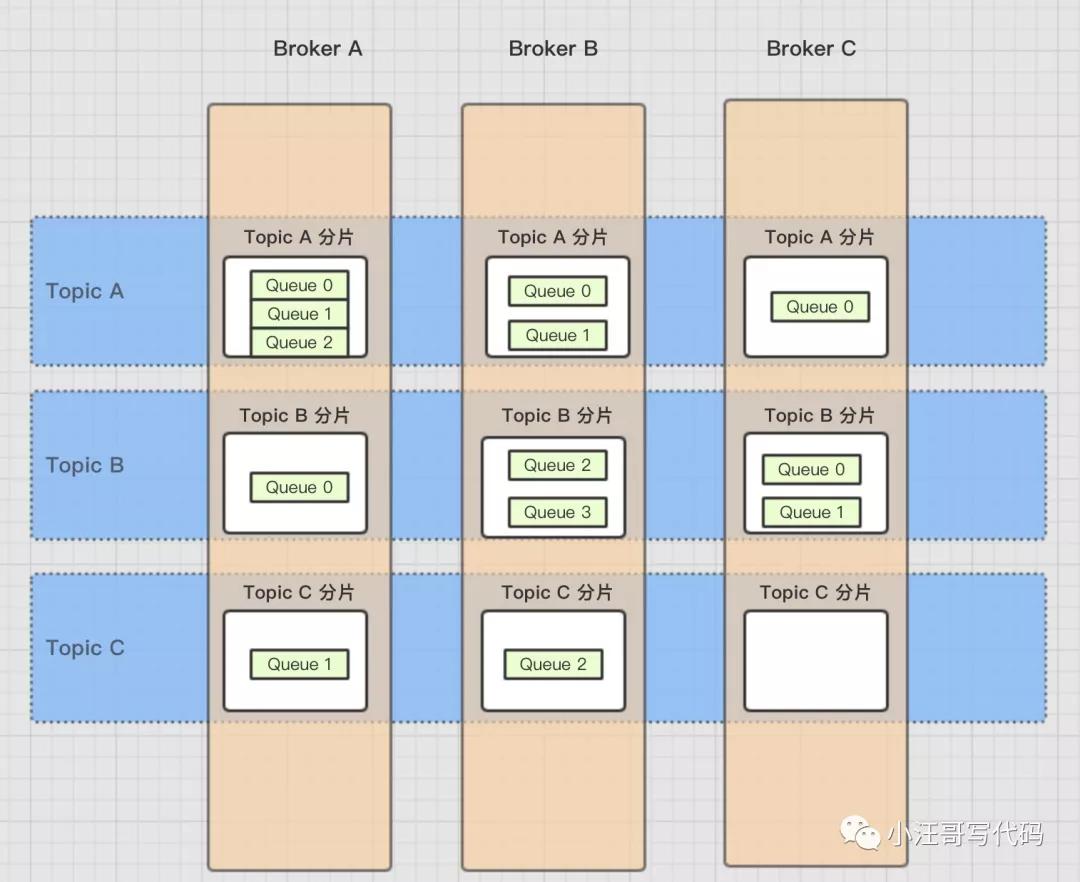
同一个topic 上的数据会分成多个queue 分布在不同的 broker 上,而且每个queue 都有副本机制。
【副本的主从同步(HA)】
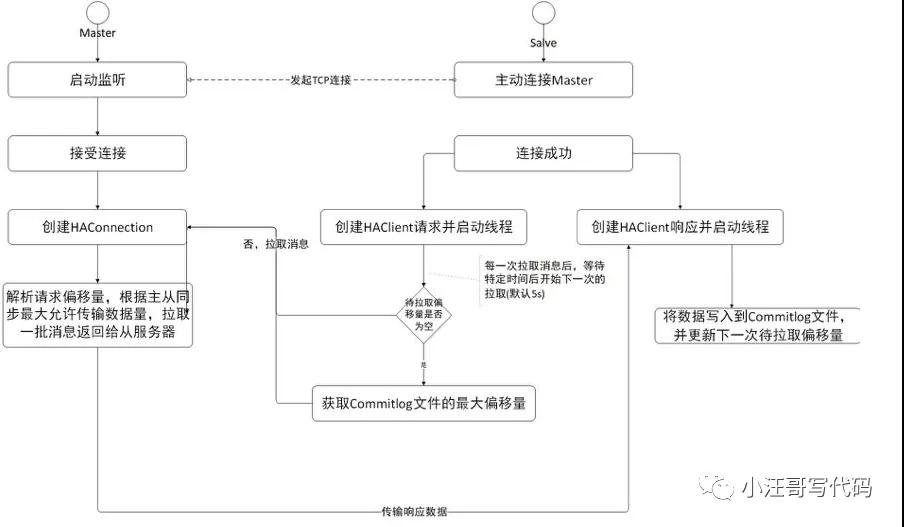
RocketMQ 的主从同步机制如下:
1.首先启动Master并在指定端口监听;
2.客户端启动,主动连接Master,建立TCP连接;
3.客户端以每隔5s的间隔时间向服务端拉取消息,如果是第一次拉取的话,先获取本地commitlog文件中最大的偏移量,以该偏移量向服务端拉取消息;
4.服务端解析请求,并返回一批数据给客户端;
5.客户端收到一批消息后,将消息写入本地commitlog文件中,然后向Master汇报拉取进度,并更新下一次待拉取偏移量;
6.然后重复第3步;
文件存储的优化技术
RocketMQ存储层采用的几项优化技术方案在一定程度上可以减少PageCache的缺点带来的影响,主要包括内存预分配,文件预热和mlock系统调用。
【预先分配MappedFile】
在消息写入过程中(调用CommitLog的putMessage()方法),CommitLog会先从MappedFileQueue队列中获取一个 MappedFile,如果没有就新建一个。
RocketMQ中预分配MappedFile的设计非常巧妙,下次获取时候直接返回就可以不用等待MappedFile创建分配所产生的时间延迟。
【文件预热&&mlock系统调用】
(1)mlock系统调用:其可以将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。对于RocketMQ这种的高吞吐量的分布式消息队列来说,追求的是消息读写低延迟,那么肯定希望尽可能地多使用物理内存,提高数据读写访问的操作效率。
(2)文件预热:预热的目的主要有两点;第一点,由于仅分配内存并进行mlock系统调用后并不会为程序完全锁定这些内存,因为其中的分页可能是写时复制的。因此,就有必要对每个内存页面中写入一个假的值。其中,RocketMQ是在创建并分配MappedFile的过程中,预先写入一些随机值至Mmap映射出的内存空间里。第二,调用Mmap进行内存映射后,OS只是建立虚拟内存地址至物理地址的映射表,而实际并没有加载任何文件至内存中。程序要访问数据时OS会检查该部分的分页是否已经在内存中,如果不在,则发出一次缺页中断。这里,可以想象下1G的CommitLog需要发生多少次缺页中断,才能使得对应的数据才能完全加载至物理内存中(ps:X86的Linux中一个标准页面大小是4KB)?RocketMQ的做法是,在做Mmap内存映射的同时进行madvise系统调用,目的是使OS做一次内存映射后对应的文件数据尽可能多的预加载至内存中,从而达到内存预热的效果。
本文转载自微信公众号「小汪哥写代码」,可以通过以下二维码关注。转载本文请联系小汪哥写代码公众号。