本文整理自 5 月 29 日阿里云开发者大会,大数据与 AI 一体化平台分论坛,秦江杰和刘童璇带来的《基于实时深度学习的推荐系统架构设计和技术演进》。分享内容如下:
1.实时推荐系统的原理以及什么是实时推荐系统
2.整体系统的架构及如何在阿里云上面实现
3.关于深度学习的细节介绍。
一、实时推荐系统的原理
在介绍实时推荐系统的原理之前,先来看一个传统、经典的静态推荐系统。
用户的行为日志会出现在消息队列里,然后被ETL到特征生成和模型训练中。这部分的数据是离线的,离线的模型更新和特征更新会被推到在线系统里面,比如特征库和在线推理的服务中,然后去服务在线的搜索推广应用。这个推荐系统本身是一个服务,前端展示的服务推广应用可能有搜索推荐、广告推荐等。那么这个静态系统到底是怎么工作的?我们来看下面的例子。
1. 静态推荐系统
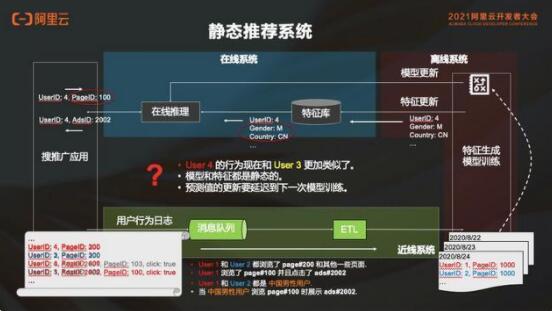
截取现在用户的行为日志,倒入离线系统中去做特征生成和模型训练,这段日志表示用户 1 和用户 2 同时浏览了 page#200 这个页面和其他一些页面,其中用户 1 浏览了 page#100 并且点击了 ads#2002。那么这个日志会被 ETL 到离线,然后送去做特征生成和模型训练。生成的特征和模型里面会看到,用户 1 和用户 2 都是中国男性用户,“中国男性”是这两个用户的一个特征,这个学习模型最终结果是:中国男性用户浏览了 page#100 的时候,需要给他推 ads#2002。这里面的逻辑就是把相似用户的行为归到一起,说明这类用户应该有同样的行为。
用户特征推进特征库建立的模型,在推送至在线服务里的时候如果有一个用户 4 出现,在线推理的服务就会到特征库里面去查这个用户的特征,查到的特征可能是这个用户正好是中国的男性用户,模型之前学到了中国男性用户访问 page#100 时候要推 ads#2002,所以会根据学习模型给用户 4 推荐了 ads#2002。以上就是静态推荐系统的基本工作流程。
但是这个系统也有一些问题,比如第一天的模型训练完成后,发现用户 4 第二天的行为其实跟用户 3 更像,不是和用户 1、用户 2 类似 。但是之前模型训练的结果是中国男性用户访问 page#100 时候要推 ads#2002,并且会默认进行这种推荐。只有经过第二次模型计算后才能发现用户 4 和用户 3 比较像,这时再进行新的推荐,是有延迟的。这是因为模型和特征都是静态的。
对于静态推荐系统来讲,特征和模型都是静态生成的。比如以分类模型为例,根据用户的相似度进行分类,然后假设同类用户都有相似的行为兴趣和特征,一旦用户被化成了某一类,那么他就一直在这个类别中,直到模型被重新训练。
2. 静态推荐系统问题
第一,用户行为其实是非常多元化的,没有办法用一个静态的事情去描述这个用户的行为。
第二,某一类用户的行为可能比较相似,但是行为本身发生了变化。例如中国男性用户访问page#100时候要推ads#2002,这是昨天的行为规律;但是到了第二天的时候发现不是所有的中国男性用户看到page#100时候都会点击ads#2002。
3. 解决方案
3.1 加入实时特征工程后能够灵活推荐
在推荐系统中加入实时特征工程,把消息队列里面的消息读一份出来,然后去做近线的特征生成。举个例子,中国男性用户最近访问 page#100 的时候点击最多的 10 个广告,这件事情是实时去追踪的。就是说中国男性用户最近 10 分钟或者半个小时之内访问 page#100 的时候点的最多 10 个广告,个事情不是从昨天的历史数据里面得到的信息,而是今天的用户实时行为的数据,这就是实时特征。
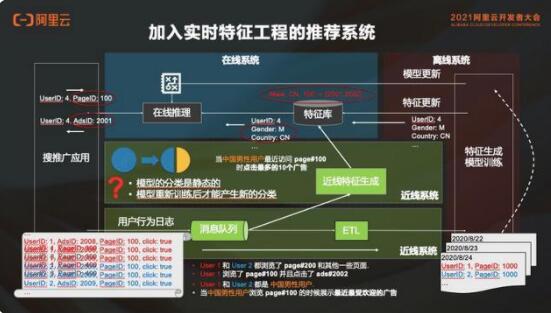
有了这个实时特征以后,就能解决刚才那个随大流的问题。同样的,如果这里的特征是对某一个用户最近 3 分钟或者 5 分钟的行为采集的,就能够更加准确的追踪到这个用户当时当刻的意图,并且给这个用户去做更准确的推荐。
所以说,在推荐系统中加入实时特征后能精准推荐。比如刚才的例子,如果用户 4 在这个情况下访问 page#100,新的学习内容为:中国男性用户最近访问 page#100 的时候,点的最多的是 ads#2001。那我们会直接推荐 ads#2001,而不是按照昨天的信息给他推 ads#2002。
3.2 实时特征推荐体系的局限性
之前的用户 1 和用户 2 的行为是非常相似的,加了实时特征就能知道它当前的意图。但是,如果用户 1 和用户 2 在做相同的特征时,他们的行为产生了不一致;也就是说在模型里面被认为是同一类的用户,他们的行为产生分化了,变成了两类用户。如果是静态的模型,即使加入了实时特征,也无法发现这一类新的用户;需要对模型进行重新训练以后,才能够产生一个新的分类。
加入实施特征工程推荐系统后,可以追踪某一类用户的行为,贴合一个大流的变化;也可以实时追踪用户的表现,了解用户当时的意图。但是当模型本身的分类方式发生变化的时候,就没有办法找到最合适的分类了,需要重新对训练模型进行分类,这种情况会遇到很多。
比如说当有很多新产品上线时,业务在高速增长,每天都会产生很多的新用户,或者说用户行为分布变化得比较快。这种情况下即使使用了实时特征系统,由于模型本身是一个逐渐退化的过程,也会导致昨天训练的模型今天再放到线上去,不一定能够 work 的很好。
3.3 解决方案
在推荐系统中新增两个部分:近线训练和近线样本生成。
假设有用户 1 和用户 2 分别是上海和北京的用户,这个时候会发现之前的模型不知道上海和北京的用户是有区别的,它认为都是中国男性用户。而在加入实时训练这个模型后,就会逐渐的学习北京的用户和上海的用户,两者的行为是有区别的,确认这一点后再进行推荐就会有不一样的效果。
再比如说,今天北京突然下暴雨了或者上海天气特别热,这个时候都会导致两边用户的行为不太一样。这时再有一个用户 4 过来,模型就会分辨这个用户是上海还是北京的用户。如果他是上海的用户,可能就会推荐上海用户所对应的内容;如果不是的话,可以继续推荐别的。
加入实时模型训练,最主要的目的是在动态特征的基础上,希望模型本身能够尽可能的贴合此时此刻用户行为的分布,同时希望能够缓解模型的退化。
二、 阿里巴巴实时推荐方案
首先了解下阿里内部实施完这套方案之后有什么好处:
第一个是时效性。目前阿里大促开始常态化,在大促期间整个模型的时效性得到了很好的提升;
第二个是灵活性。可以根据需求随时调整特征和模型;
第三个是可靠性。大家在使用整个实时推荐系统的时候会觉得不放心,没有经过离线当天晚上大规模的计算验证,直接推上线,会觉得不够可靠,其实已经有一套完整的流程去保证这件事情的稳定性和可靠性;
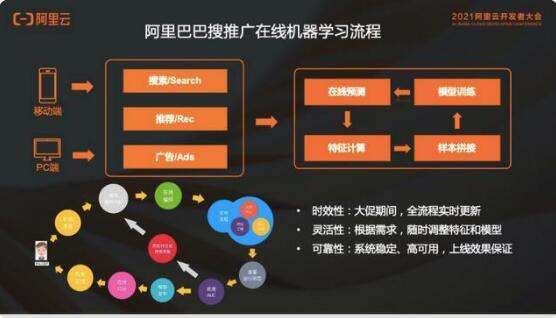
这个推荐模型从图上看,从特征到样本到模型,再到在线预测这个过程,和离线其实没有区别。主要的区别就是整个的流程实时化,用这套实时化的流程去服务在线的搜索推广应用。
1. 如何实施
根据经典离线架构进行演变。
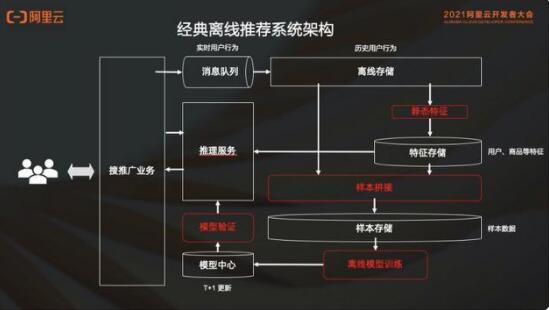
首先,用户群行为会从消息队列来走离线存储,然后这个离线存储会存储所有的历史用户行为;然后在这个离线存储上面,通过静态特征计算样本;接下来把样本存到样本存储里,去做离线模型训练;之后把离线的这个模型发布到模型中心,去做模型验证;最后把模型验证过的模型推到推理服务去服务在线业务。这个就是完整的离线体系。
我们将通过三件事情进行实时化改造:
第一是特征计算;
第二是样本生成;
第三是模型训练。
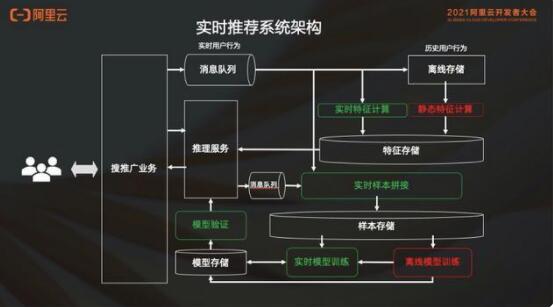
相比之前,消息队列不仅仅存入离线存储,还要分出来两链路:
第一链路会做实时的特征计算,比如说最近几分钟之内中国男性用户看 page#100 的时候点了什么广告,这个是实时计算算出来的,即最近一段时间的一些用户可能产生的一些行为特征等。
另外一条链路是消息队列,可以进行实时样本拼接,就是说不需要手动去打标签,因为用户自己会告诉我们标签。比如我们做了一个推荐,如果用户点击了,那么它一定是个正样本;如果过了一段时间用户没有点击,那我们认为它就是个负样本。所以不用人工去打标签,用户会帮我们打标签,这个时候很容易就能够得到样本,然后这部分样本会放到样本存储里面去,这个跟之前是一样的。区别在于这个样本存储不仅服务离线的模型训练,还会去做实时的模型训练。
离线模型训练通常还是天级的 T+1 的,会训练出一个 base model ,交给实时模型训练去做增量的训练。增量模型训练的模型产出就可能是 10 分钟、15 分钟这样的级别,然后会送到模型存储做模型验证,最后上线。
架构图中绿色的部分都是实时的,这部分有一些是新加出来的,有一些则是由原本的离线变成实时的。
2. 阿里云企业级实时推荐解决方案
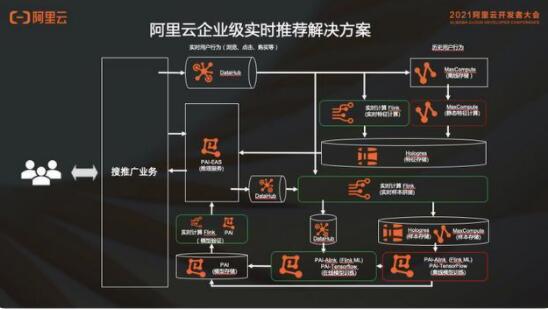
在阿里云企业级实时推荐解决方案中,如何使用阿里云产品搭建?
消息队列会用 DataHub;实时的特征和样本使用实时计算 Flink 版;离线的特征存储和静态特征计算都会用 MaxCompute;特征存储和样本中心使用 MaxCompute 交互式分析(Hologres);消息队列的部分都是 DataHub;模型训练的部分会用到 PAI,模型存储和验证,还有在线推理服务这一套流程都是 PAI 里面的。
2.1 实时特征计算及推理
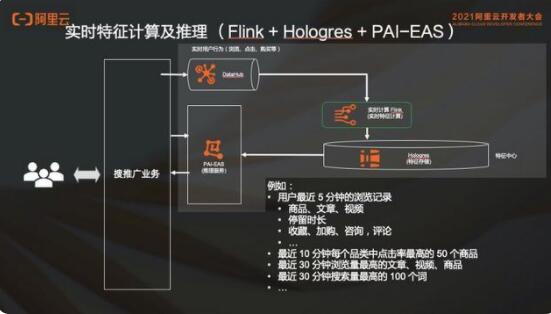
特征和推理就是把用户日志实时采集过来,导入实时计算 Flink 版里面去做实时特征计算。然后会送到 Hologres 里面去,利用 Hologres 流式的能力,拿它做特征中心。在这里,PAI 可以去直接查询 Hologres 里面的这些用户特征,也就是点查的能力。
在实时计算 Flink 版计算特征的时候,比如说用户最近 5 分钟的浏览记录,包括商品、文章、视频等,根据不同的业务属性,实时特征是不一样的。也可能包括比如最近 10 分钟每个品类点击率最高的 50 个商品,最近 30 分钟浏览量最高的文章、视频、商品,最近 30 分钟搜索量最高的是 100 个词等。在这不同的场景,比如搜索推荐,有广告、有视频、有文本、有新闻等。这些数据拿来做实时特征计算的和推理的这一条链路,然后在这个链路基础之上,有的时候也是需要静态特征回填的。
2.2 静态特征回填
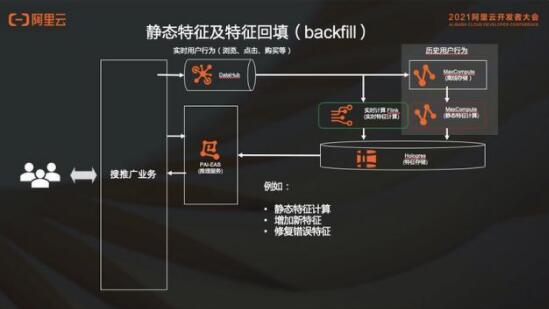
比如新上线一个特征,这个新的特征在实时链路上线了之后,如果需要最近 30 天用户的行为,不可能等 30 天之后再计算。于是需要找到离线数据,然后把最近 30 天的这个特征给它补上。这就叫特征回填,也就是 backfill 。通过 MaxCompute 去算这个特征回填一样也是写到 Hologres,同时实施起来也会把新的特征给加上,这是一个新特征的场景。
当然还有一些其他场景,比如算一些静态特征;再比如可能线上特征有一个 bug 算错了,但是数据已经落到离线去了,这时候对离线特征要做一个纠错,也会用到 backfill 的过程。
2.3 实时样本拼接
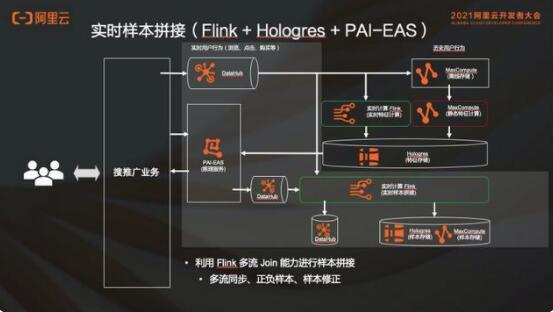
实时样本拼接本质上对于推荐场景来讲,就是展示点击流之后,样本获得一个正样本或者负样本。但是这个 label 显然是不够的,还需要有特征,才能够做训练。特征可以从 DataHub 中来,在加入了实时特征以后,样本的特征是时时刻刻在发生变化的。
举一个例子,做出某一个商品的推荐行为的时候,是早上 10:00,用户的实时特征是他 9:55 到 10:00 的浏览记录。但是当看到这个样本流回来的时候,有可能是 10:15 的时候了。如果说这个样本是一个正样本,当给到用户推荐的商品且他产生了购买行为,这段时间我们是无法看到用户实时特征的。
因为那个时候的特征已经变成了用户从 10:10 浏览到 10:15 的时候的浏览记录了。但是在做预测的时候,并不是根据这个 5 分钟内的浏览记录来推荐的这个商品,所以需要把当时做推荐的时候所采用的那些特征给它保存下来,在这个样本生成的时候给它加上,这就是 DataHub 在这里的作用。
当使用 ES 做实时推荐的时候,需要把当时用来做推荐的这些特征保存下来,拿去做这个样本的生成。样本生成后,可以存储到 Hologres 和 MaxCompute 里面去,把实时样本存储到 DataHub 里面。
2.4 实时深度学习和 Flink AI Flow
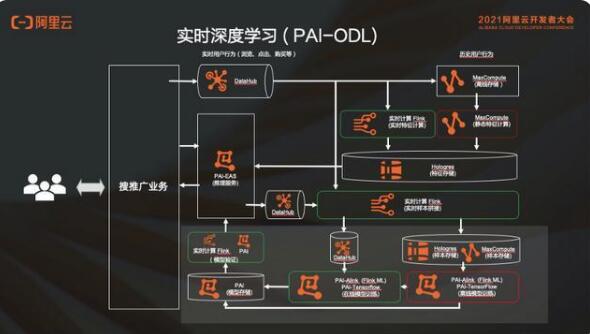
这个部分会有离线训练是以 “天“ 为级别的;也会有在线的实时训练是 “分钟级” 的;有的可以做的比较极致,是按 “秒” 级的。不管是哪边出来的模型,最后都会送到这个模型中去,进行模型的验证以及上线。
这个其实是一个非常复杂的工作流。首先,静态特征计算是周期性的,也可能是手动的。当需要做 backfill 的时候,有手动触发的一个过程。根据这个模型图能看出它是批的训练,当它训练完了之后,需要到线上去做一个实时模型验证。这个模型验证可能是一个流作业,所以这里是从批到流的一个触发过程,模型是从流作业里面出来的,它是一个 long running 的作业,每 5 分钟产生一个模型,这每 5 分钟的模型也需要送进去做这个模型验证,所以这是一个流触发流动作的过程。
再比如说这个实时样本拼接,大家都知道 Flink 有一个 watermark 的概念,比如说到某一个时刻往前的数据都到收集齐了,可以去触发一个批的训练,这个时候就会存在一个流作业。当他到了某一个时刻,需要去触发批训练的时候,这个工作流在传统的工作流调度里面是做不到的,因为传统的工作流调度是基于一个叫做 job status change 的过程来做的,也就是作业状态发生变化。
假设说如果一个作业跑完了并且没有出错,那么这个作业所产生的数据就已经 ready 了,下游对这些数据有依赖的作业就可以跑了。所以简单来说,一个作业跑完了下一个作业延续上继续跑,但是当整个工作流里面只要有一个流作业的存在,那么这整个工作流就跑不了了,因为流作业是跑不完的。
比如说这个例子的实时计算,数据是不断变化的跑动,但是也会存在随时可能 ready 的,也就是说可能跑到某一个程度的时候数据就 ready 了,但其实作业根本没有跑完。所以需要引入一个工作流,这个工作流我们把它叫做 Flink AI Flow,去解决刚才那个图里面各个作业之间的协同关系这个问题。
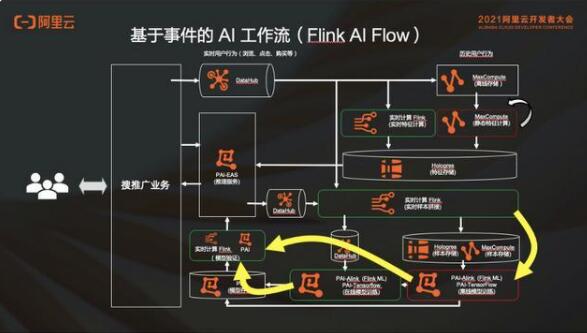
Flink AI Flow 本质上是说节点都是一个 logical 的 processing unit,是一个逻辑处理节点,节点和节点之间,不再是上一个作业跑完跑下一个作业的关系了,而是一个 event driven 的 conditions,是一个事件触发的一个概念。
同样在工作流执行层面,调度器也不再基于作业状态发生变化去做调度动作,而是基于事件的调度。比方说事件调度这个例子,当一个流作业的 water mark 到了的时候,就是说这个时间点之前的所有数据都到全了,可以去触发批作业去跑,并不需要流作业跑完。
对于每一个作业来讲,通过调度器提作业或者停作业是需要条件的。当这些事件满足一个条件的时候,才会进行调度动作。比如说有一个模型,当模型生成的时候,会满足一个条件,要求调度器把一个 validation 的作业模型验证的作业给拉起来,那这个就是由一个 event 产生了一个 condition,要求 schedule 去做一件事情的过程。
除此之外,Flink AI Flow 除了调度的服务之外,还提供了三个额外的支持服务来满足整个 AI 工作流语义,分别是元数据服务、通知服务和模型中心。
元数据服,是帮大家管理数据集和整个工作流里面的一些状态;
通知服务,是为了满足基于事件调度语义;
模型中心,是去管理这个模型当中的一些生命周期。
三、实时深度学习训练 PAI-ODL
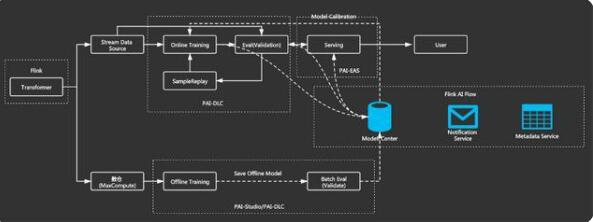
Flink 生成实时样本之后,在 ODL 系统有两个流。
第一个流是实时流,生成的实时样本送到 stream data source 上面比如像 kafka,在 kafka 中的这个样本会有两个流向,一个是流到 online training 中,另一个是流到 online evaluation 。
第二个流是离线训练的数据流,拿离线的数据流向数仓来做这种 offline T+1 的 training 。
在 online training 中支持用户可配置生成模型的频率,比如说用户配置 30 秒或者 1 分钟生成一次模型更新到线上。这个满足在实时推荐场景中,特别是时效性要求高的场景。
ODL 支持用户设定一些指标来自动判断生成的模型是否部署线上,当 evaluation 这边达到这些指标要求之后,这个模型会自动推上线。因为模型生成的频率非常高,通过人工去干预不太现实。所以需要用户来设定指标,系统自动去判断当指标达到要求,模型自动回推到线上。
离线流这边有一条线叫 model calibration,也就是模型的校正。离线训练生成 T+1 的模型会对在线训练进行模型的校正。
PAI-ODL 技术点分析
1. 超大稀疏模型训练
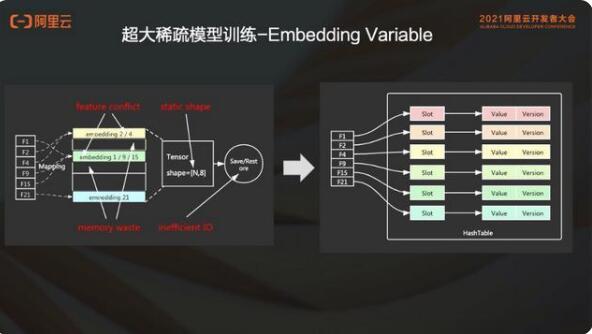
超大稀疏模型的训练,是推荐搜索广告这类稀疏场景里常用的一个功能。这里实际上是一个典型、传统的深度学习引擎,比如像 TensorFlow,它原生的内部实现的就是 fix size 这种固定 size variable,在稀疏场景使用中会有一些常见问题。
就像 static shape,比如在通常的场景里边,像手机 APP 这种,每天都会有新用户来加入,每天也会有新的商品,新闻和新的视频等更新。如果是一个固定大小的 shape 的话,其实是无法表达稀疏场景中这种变化的语义的。而且这个 static shape 会限制模型本身长期的增量训练。如果说一个模型可增量训练时长是一两年,那很可能之前设定的这个大小已经远远不能满足业务需求,有可能带来严重的特征冲突,影响模型的效果。
如果在实际的模型中设置的 static shape 比较大,但是利用率很低,就会造成内存的浪费,还有一些无效的 IO。包括生成全量模型的时候,造成磁盘的浪费。
在 PAI-ODL 中基于 PAI-TF 引擎,PAI-TF 提供了 embedding variable 功能。这个功能提供动态的弹性特征的能力。每个新的特征会新增加一个 slot。并支持特征淘汰,比如说下架一个商品,对应的特征就会被删掉。
增量模型是说可以把一分钟内稀疏特征变化的部分记录下来,产生到这个增量模型中。增量模型记录了稀疏的变化的特征和全量 Dense 的参数。
基于增量模型的导出,就可以实现 ODL 场景下模型的快速更新。快速更新的增量模型是非常小的,可以做到频繁的模型上线。
2. 支持秒级的模型热更新
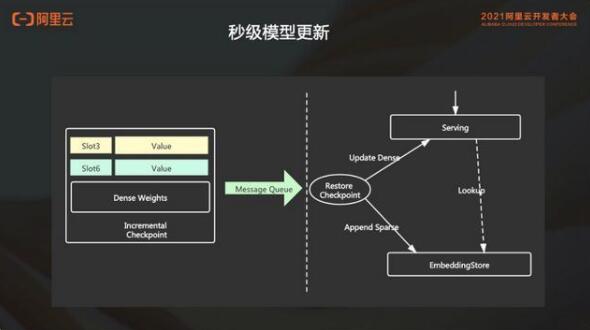
通常在我们接触的用户中,通常是关注的主要是三点:
第一点就是模型的效果,我上线之后效果好不好?
第二点就是成本,我到底花多少钱。
第三点就是性能,能不能达到我对RT的要求。
embedding store 多级的混合存储支持用户可配置不同的存储方式。可以在满足用户性能的前提下,更大程度的降低用户的成本。
embedding 场景是非常有自己场景特点的,比如说我们的特征存在很明显的冷热区别。有些商品或者视频本身特别热;有些则是用户的点击行为特别多,也会造成它特别热。有些冷门的商品或者视频就没人点,这是很明显的冷热分离,也是符合这种二八原则的。
EmbeddingStore 会把这些热的特征存储到 DRAM 上面,然后冷的特征存放在 PMEM 或者是 SSD 上。
3. 超大稀疏模型预测
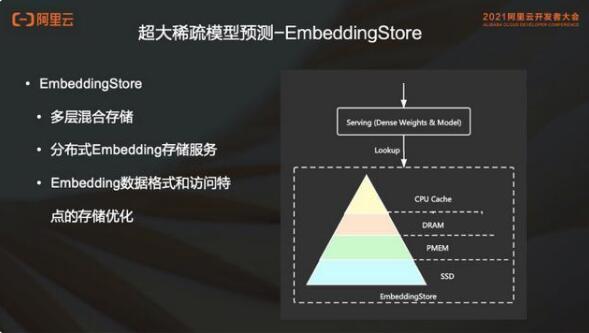
此外,EmbeddingStore 支持分布式存储 Service。在 serving 的时候,每个 serving 的节点其实都需要去做一个全量的模型的加载。如果使用 EmbeddingStore 的分布式 service,就可以避免每个 serving 节点加载全量模型。
EmbeddingStore 支持用户可配置这种分布式的 embedding, 独立的 isolated 这种 embedding store service。每个 serving 节点查询稀疏特征时从 EmbeddingStore Service 查询。
EmbeddingStore 的设计充分的考虑了稀疏特征的数据格式和访问特点。举个简单的例子:稀疏特征的 key 和 value ,key 是 int64 , value 就是一个 float 数组。无论是在 serving 还是在 training,访问都是大批量的访问。此外 Inference 阶段对稀疏特征的访问是无锁化的只读访问。这些都是促使我们设计基于 embedding 场景的稀疏特征存储的原因。
4. 实时训练模型校正
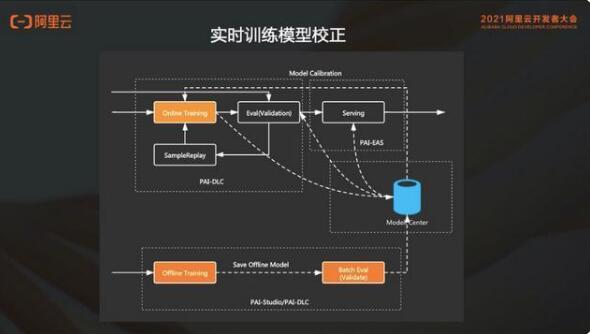
为什么 PAI-ODL 会支持离线训练模型对 online training 有一个模型校正?
通常在实时训练过程中,会存在这种 label 不准以及样本分布的问题。因此使用天级别的模型会自动校正到 online training,增强模型的稳定性。PAI-ODL 提供的模型校正用户是无干预的,用户基于自己业务特点配置相关配置后,每天自动根据新产生的全量模型进行 online training 端的 base 模型校正。当离线训练生成 base 模型,online training 会自动发现 base model,并且在 data stream source 会自动跳转到对应的样本,基于最新的 base 模型和新的 online training 的训练样本点开始 online training。
5. 模型回退及样本回放
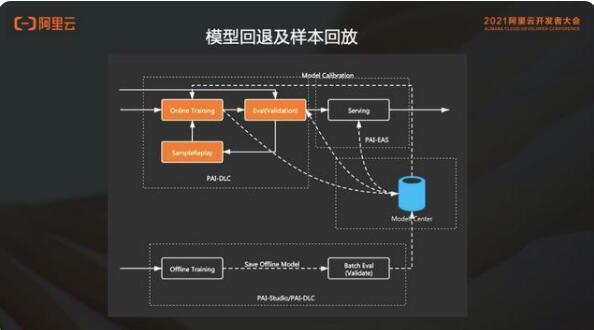
虽然有样本的异常样本检测以及异常样本处理,仍然无法避免线上的更新模型会有效果问题。
当用户收到报警,线上的指标下降。需要提供给用户一个能力,可以回滚这个模型。
但是在 online training 的场景中,从发现问题到去干预可能经过了好几个模型的迭代,产出了若干模型了。此时的回滚包含:
1)线上 serving 的模型回滚到问题时间点的前一个模型;
2)同时 online training 需要回跳到问题模型的前一个模型;
3)样本也要回跳到那个时间点来重新开始进行训练。