本文转载自微信公众号「吴亲强的深夜食堂」,作者吴亲库里。转载本文请联系吴亲强的深夜食堂公众号。
dig和wire都是Go依赖注入的工具,那么,本质上功能相似的工具,为什么要从dig切换成 wire?
场景
我们从场景出发。假设我们的项目分层是:
router->controller->service->dao。
目录大概就长这样:
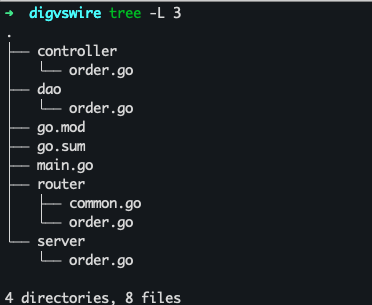
现在我们需要对外暴露一个订单服务的接口。
首页看main.go文件。
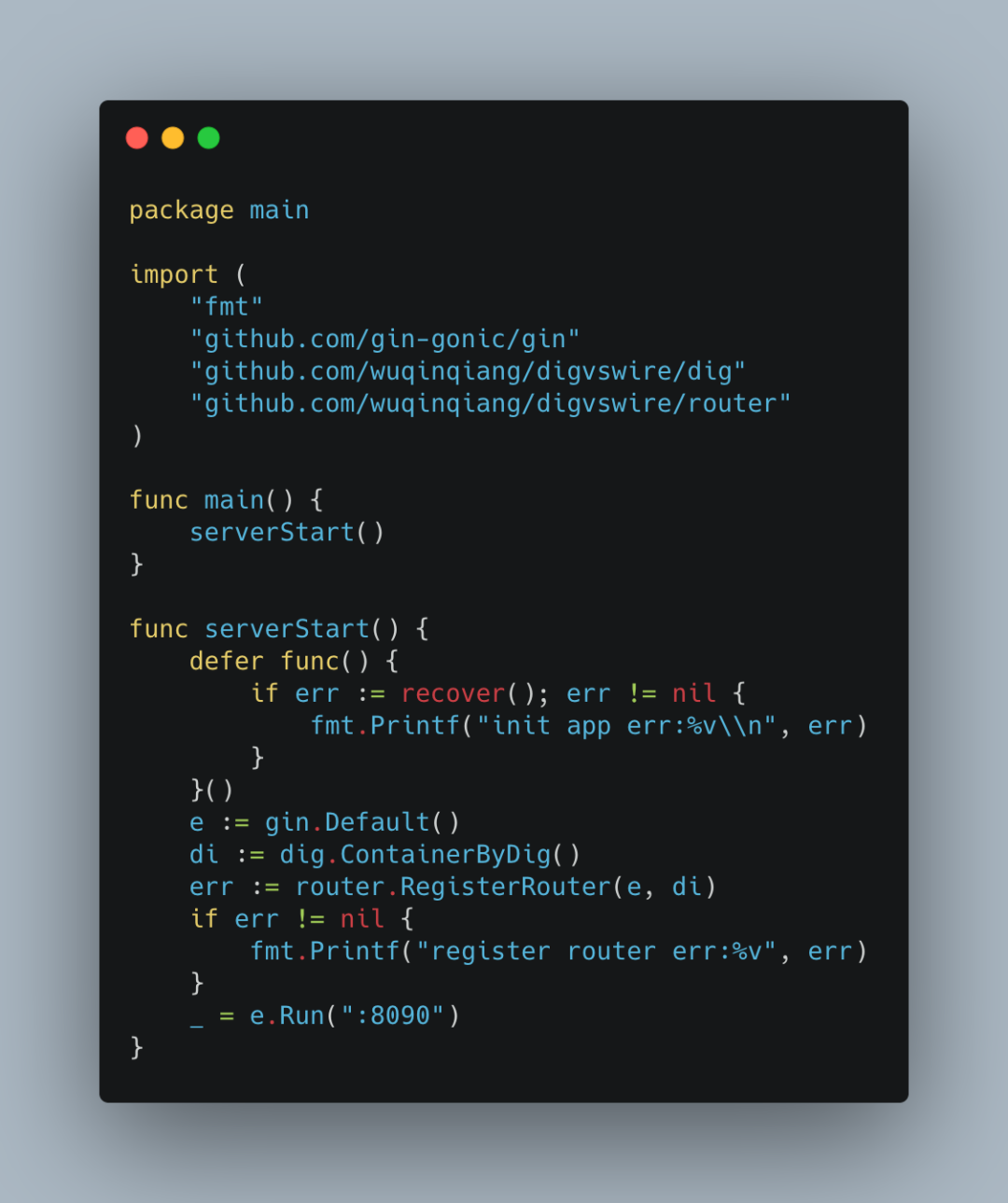
这里使用了gin启动项目。
dig
然后我们查看dig.ContainerByDig(),
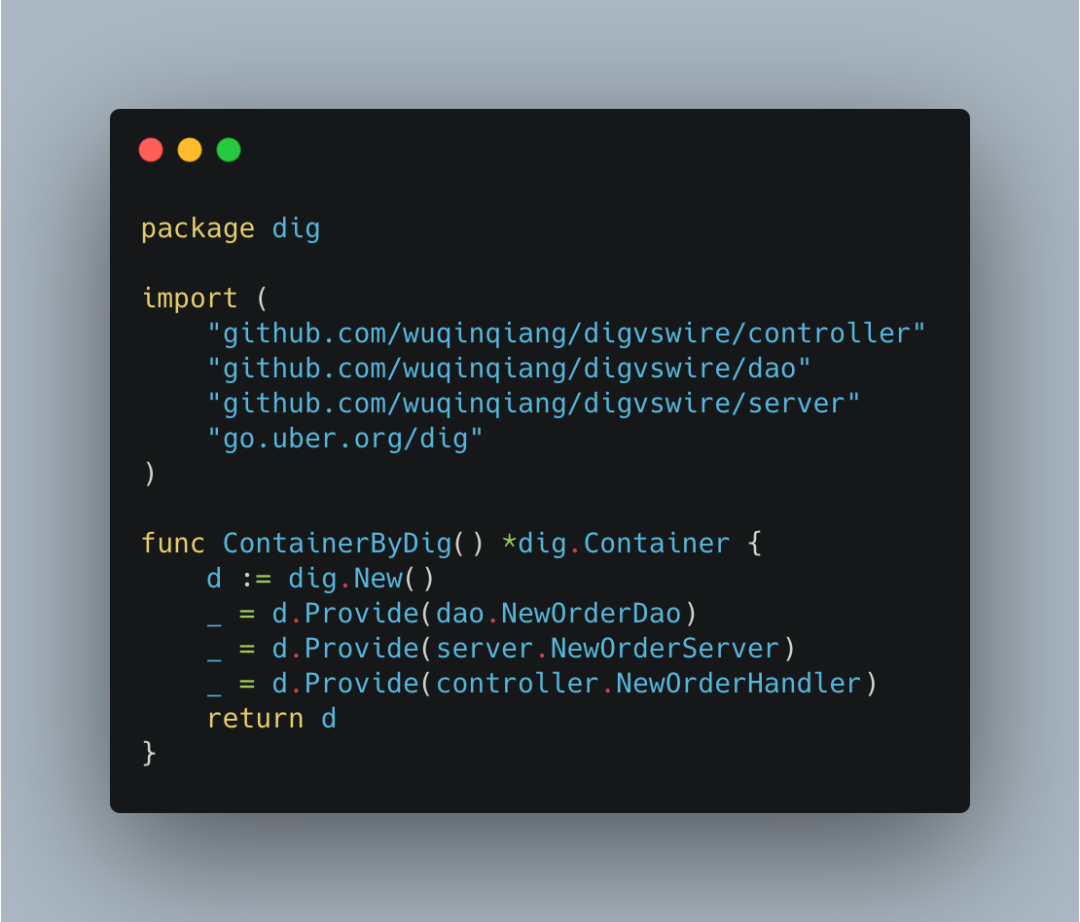
通过dig.New()创建一个di容器。Provide函数用于添加服务提供者,Provide函数第一个参数本质上是个函数。一个告诉容器 "我能提供什么,为了提供它,我需要什么?" 的函数。
我们看上面的server.NewOrderServer,
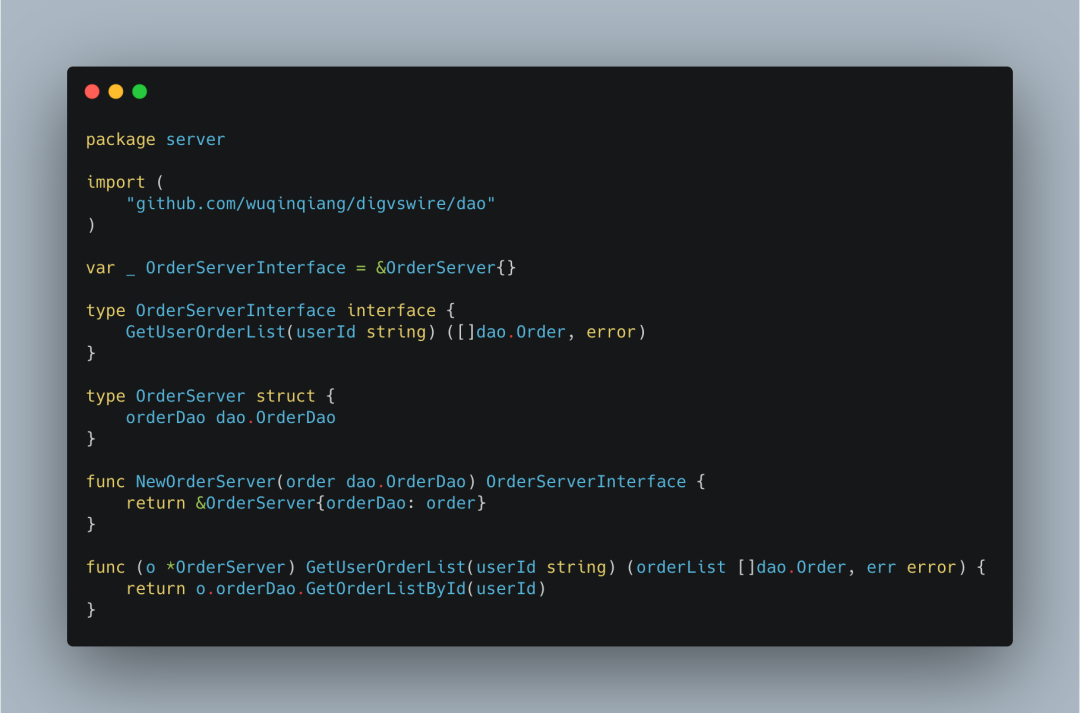
这里的NewOrderServer(xxx)在Provide中的语意就是 "我能提供一个OrderServerInterface服务,但是我需要依赖一个dao.OrderDao"。
刚才的代码中,

因为我们的调用链是controller->server->dao,那么本质上他们的依赖是controller<-server<-dao,只是依赖的不是具体的实现,而是抽象的接口。
所以你看到Provide是按照依赖关系顺序写的。
其实完全没有必要,因为这一步dig只会对这些函数进行分析,提取函数的形参以及返回值。然后根据返回的参数来组织容器结构。并不会在这一步执行传入的函数,所以在Provide阶段前后顺序并不重要,只要确保不遗漏依赖项即可。
万事俱备,我们开始注册一个能获取订单的路由,
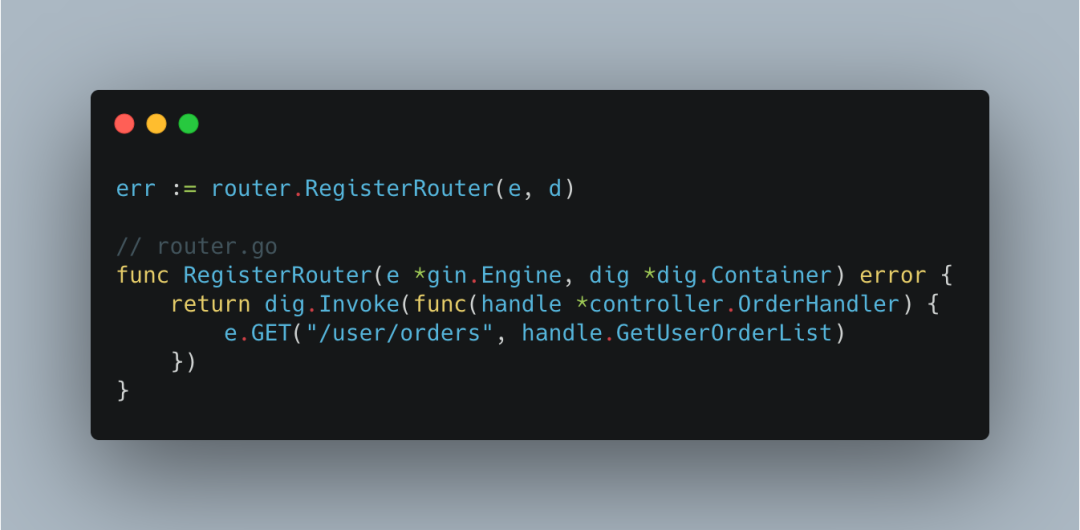
此时,调用invoke, 才是真正需要获取*controller.OrderHandler对象。
调用invoke方法,会对传入的参数做分析,参数中存在handle *controller.OrderHandler,就会去容器中寻找哪个Provide进来的函数返回类型是handle *controller.OrderHandler,
然后对应找到,
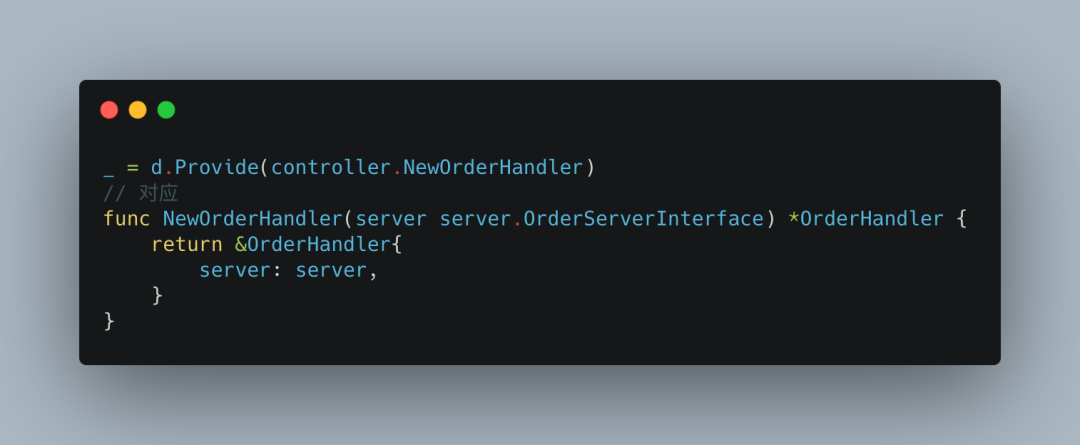
发现这个函数有形参server.OrderServerInterface,那就去找对应返回此类型的函数,
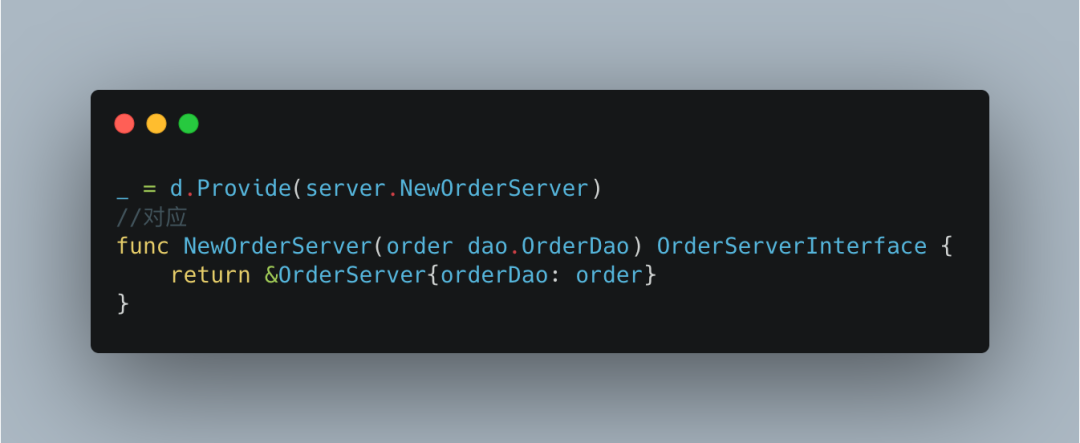
又发现形参(order dao.OrderDao),

最后发现NewOrderDao没有依赖,不需要再查询依赖。
开始执行函数的调用NewOrderDao(),把返回的OrderDao
传入到上层的NewOrderServer(order dao.OrderDao)进行函数调用,
NewOrderServer(order dao.OrderDao)返回的
OrderServerInterface继续返回到上层
NewOrderHandler(server server.OrderServerInterface)
执行调用,最后再把函数调用返回的*OrderHandler传递给
dig.Invoke(func(handle *controller.OrderHandler) {},
整个链路就通了。上面看的可能不太舒服,用一个图来描述这个过程。
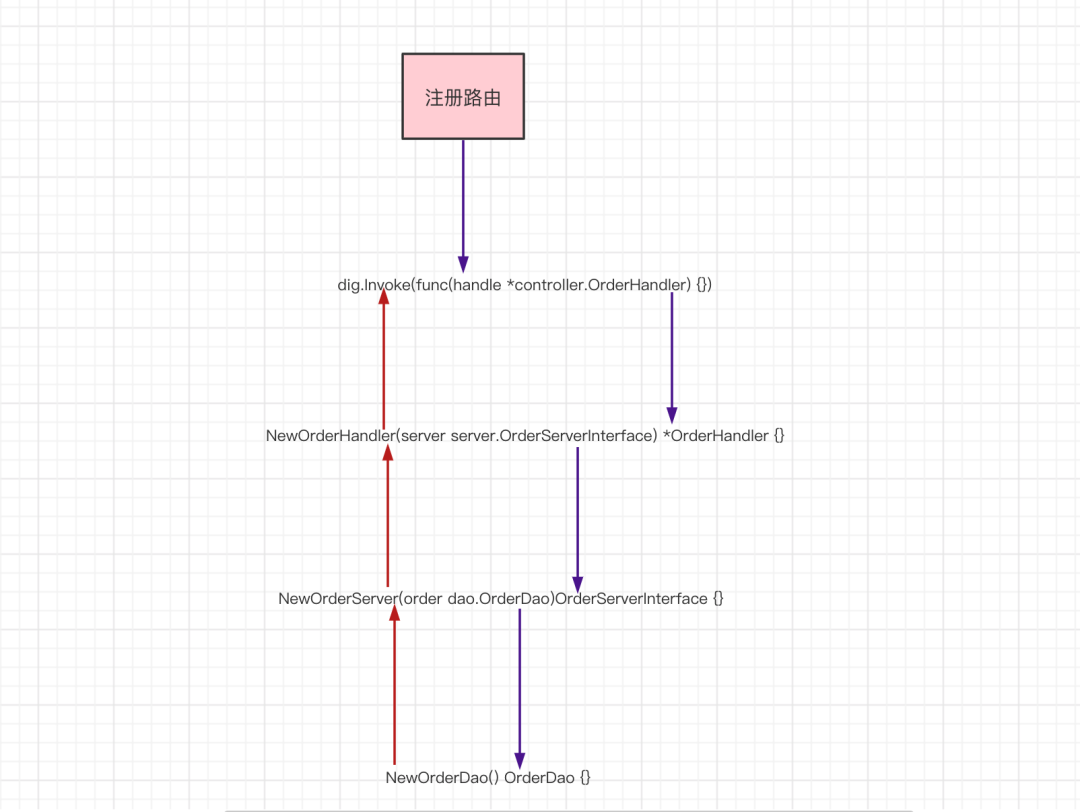
dig的整个流程采用的是反射机制,在运行时计算依赖关系,构造依赖对象。
这样会存在什么问题?
假设我现在注释掉Provide的一行代码,比如,
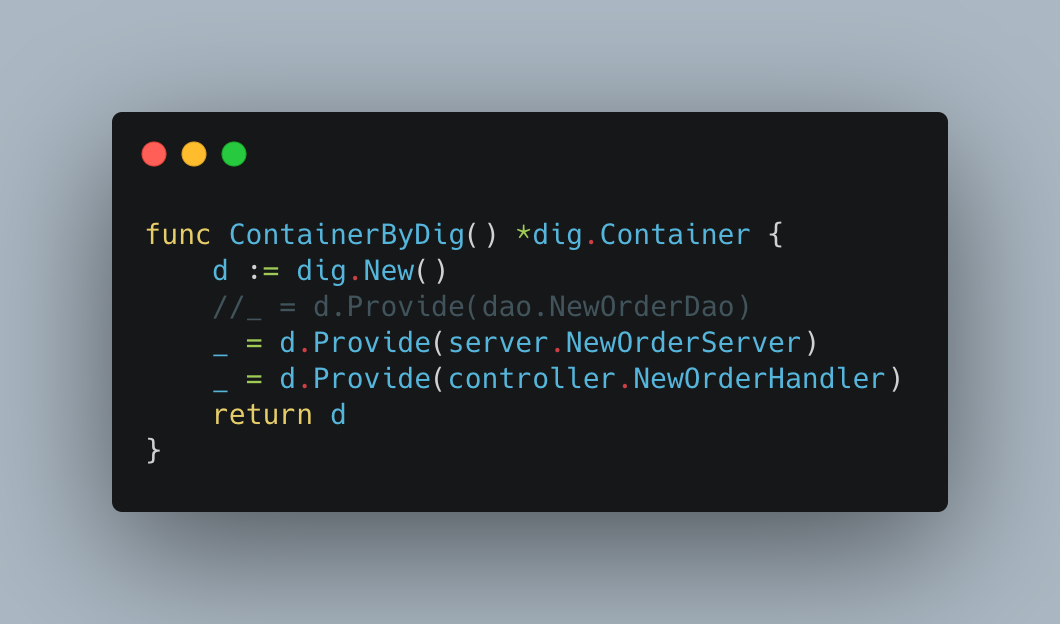
我们在编译项目的时候并不会报任何错误,只会在运行时才发现缺少了依赖项。

wire
还是上面的代码,我们使用wire作为我们的DI容器。
wire也有两个核心概念:Provider和Injector。
其中Provider的概念和dig的概念是一样的:"我能提供什么?我需要什么依赖"。
比如下面wire.go中的代码,
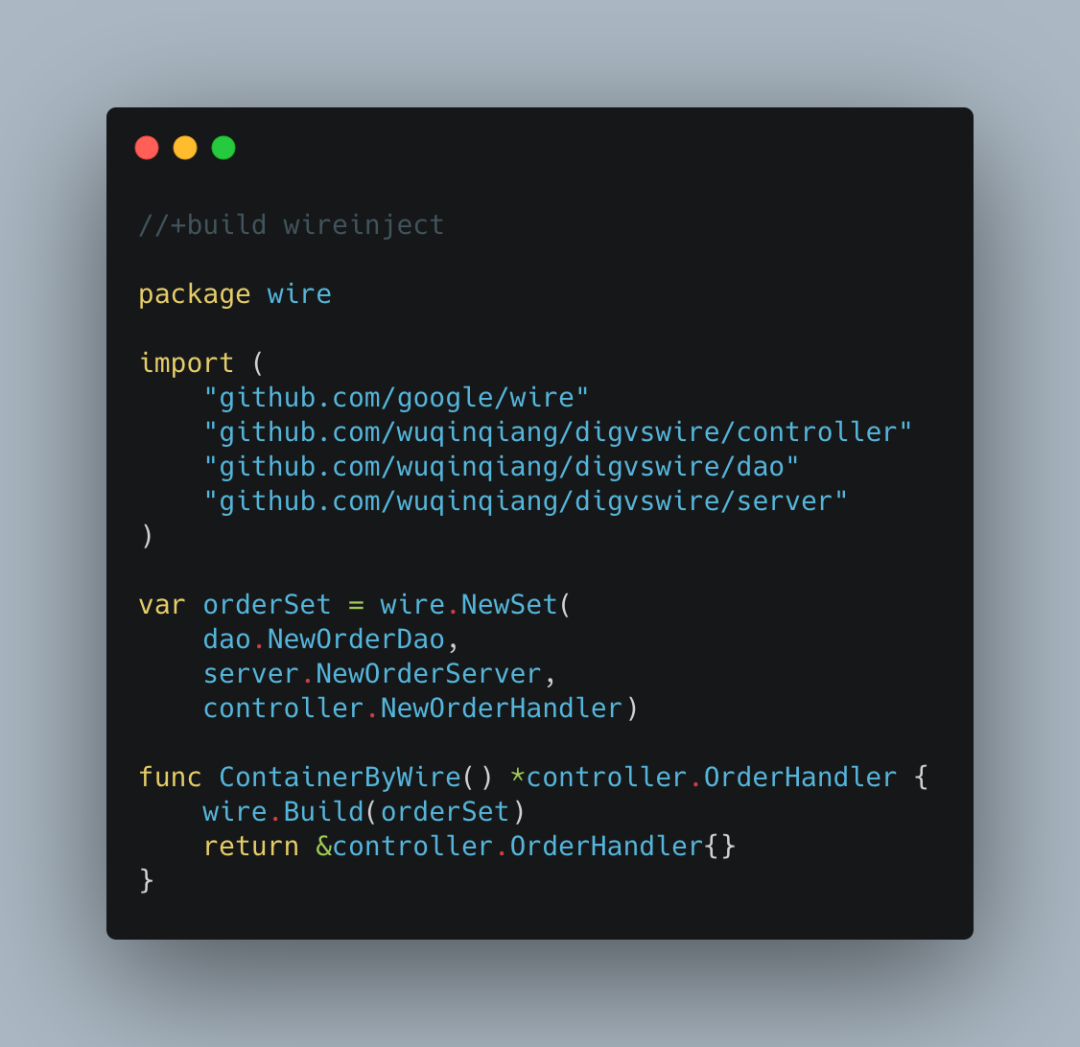
dao.NewOrderDaoserver.NewOrderServer以及controller.NewOrderHandler就是Provider。
你会发现这里还调用wire.NewSet把他们整合在一起,赋值给了一个变量orderSet。
其实是用到ProviderSet的概念。原理就是把一组相关的Provider进行打包。
这样的好处是:
- 结构依赖清晰,便于阅读。
- 以组的形式,减少injector里的Build。
至于injector,本质上就是按照依赖关系调用Provider的函数,然后最终生成我们想要的对象(服务)。
比如上面的ContainerByWire()就是一个injector。
那么wire.go文件整体的思路就是:定义好injector,然后实现所需的Provider。
最后在当前wire.go文件夹下执行wire命令后,
此时如果你的依赖项存在问题,那么就会报错提示。比如我现在隐藏上面的dao.NewOrderDao,那么会出现 ,

如果依赖不存在问题,最终会生成一个wire_gen.go文件。
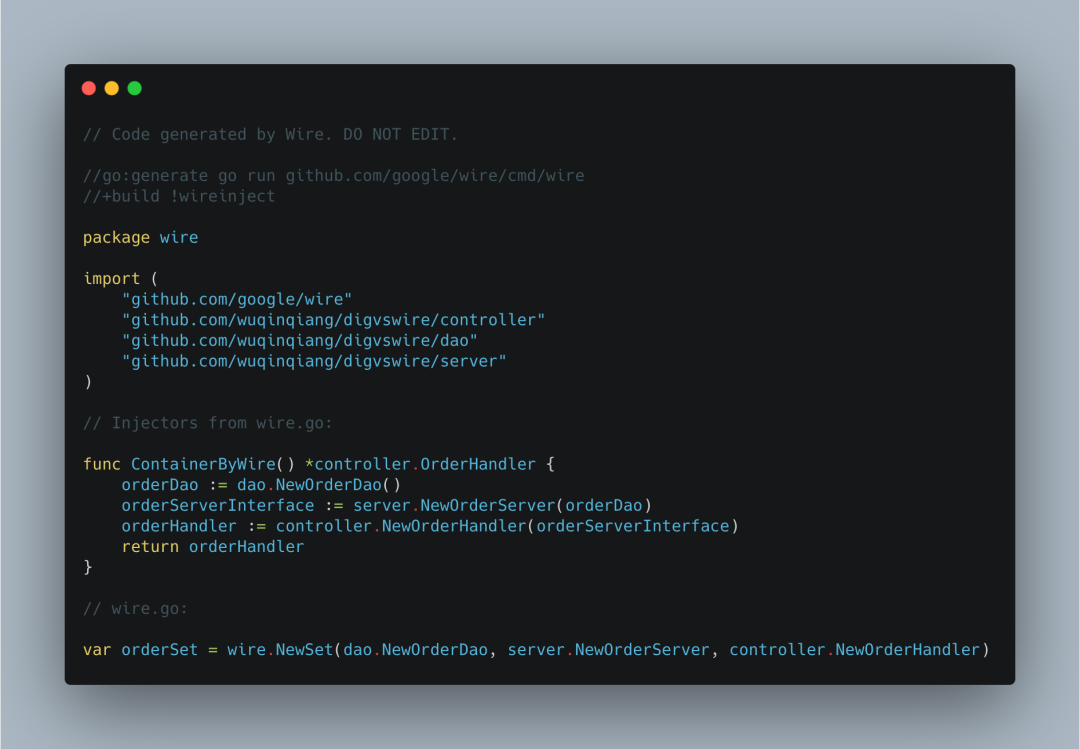
需要注意上面两个文件。我们看到wire.go中第一行//+build wireinject,这个build tag确保在常规编译时忽略wire.go文件。
而与之相对的wire_gen.go中的//+build !wireinject。
两个对立的build tag是为了确保在任意情况下,两个文件只有一个文件生效, 避免出现 "ContainerByWire()方法被重新定义" 的编译错误。
现在我们可以真正使用injector了,我们在入口文件中替换成dig。
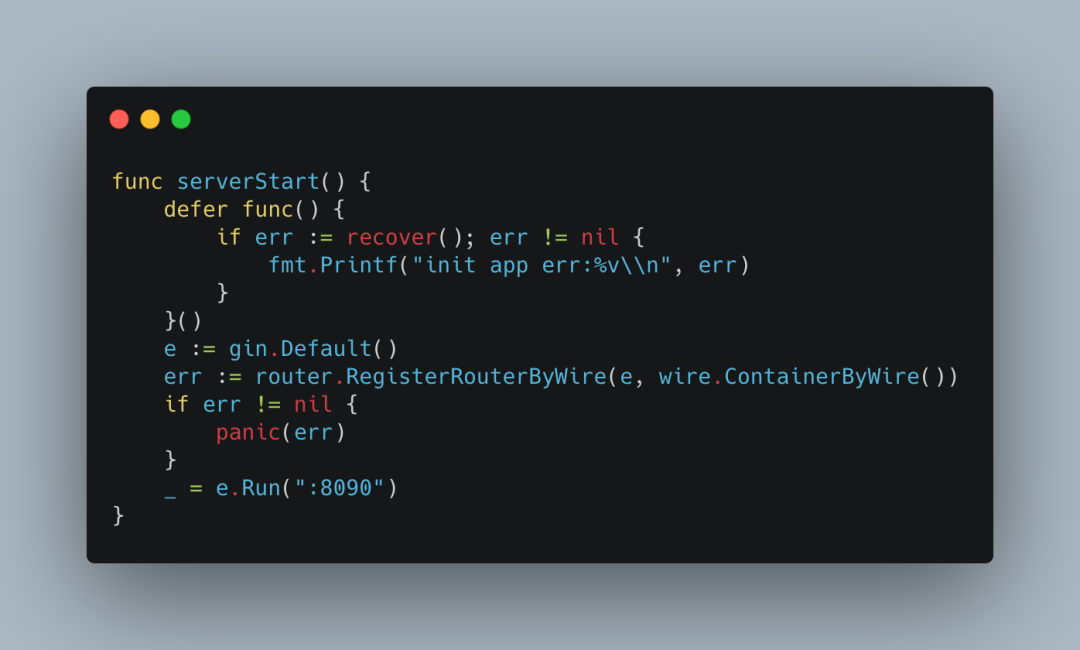
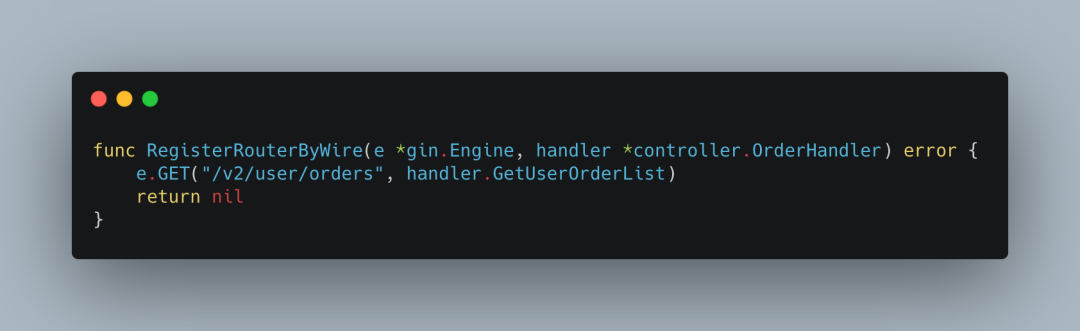
一切正常。
当然wire有一个点需要注意,在wire.go文件中开头几行:

build tag和package他们之间是有空行的,如果没有空行,build tag识别不了,那么编译的时候就会报重复声明的错误:

还有很多高级的操作可以自行了解。如果有需要完整代码请下方留言。
总结
以上大体介绍了 go 中dig和wire两个DI工具。其中dig是通过运行时反射实现的依赖注入。 而wire是根据自定义的代码,通过命令,生成相应的依赖注入代码,在编译期就完成依赖注入,无需反射机制。 这样的好处是:
- 方便排查,如果存在依赖错误,编译时就能发现。而 dig 只能在运行时才能发现依赖错误。
- 避免依赖膨胀,wire生成的代码只包含被依赖的,而dig可能会存在好多无用依赖。
- 依赖关系静态存在源码,便于工具分析。
Reference
[1]https://github.com/google/wire
[2]https://github.com/uber-go/dig
[3]https://medium.com/@dche423/master-wire-cn-d57de86caa1b
[4]https://www.cnblogs.com/li-peng/p/14708132.html