上篇文章分享了kafka 生产端的逻辑,以及消息发送到缓存后由sender线程发送到Broker,那么Broker 是怎么进行数据接收和持久化的呢?下面我们从Broker 的网络设计聊起。
Broker 网络设计
kafka的网络设计和Kafka的调优有关,这也是为什么它能支持高并发的原因。
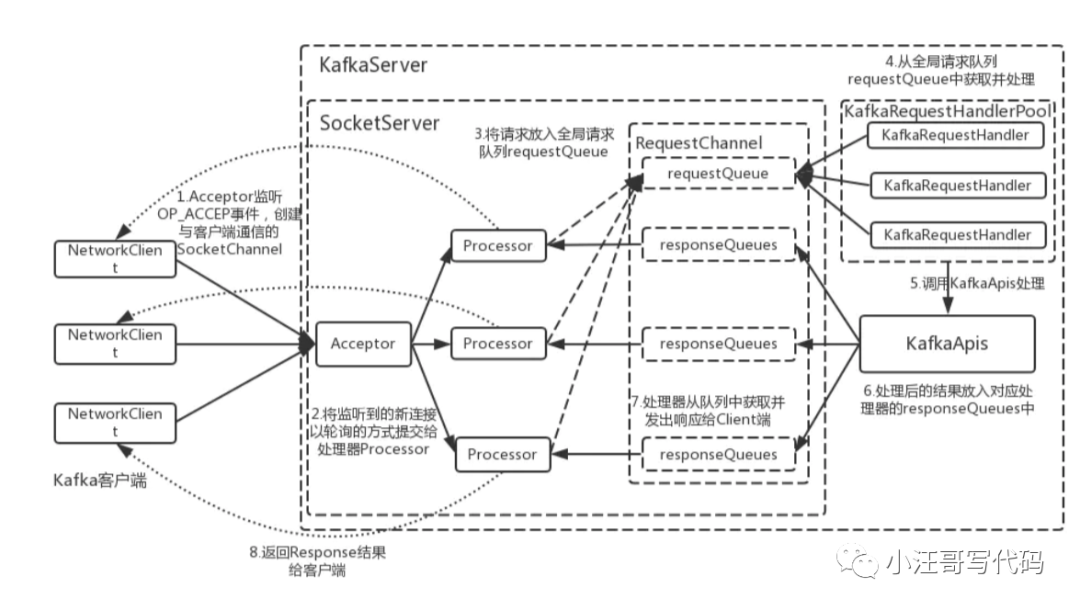
Kafka的网络三层架构
首先客户端发送请求全部会先发送给一个Acceptor,broker里面会存在3个线程(默认是3个),这3个线程都是叫做processor,
Acceptor不会对客户端的请求做任何的处理,直接封装成一个个socketChannel发送给这些processor形成一个队列,发送的方式是轮询,就是先给第一个processor发送,然后再给第二个,第三个,然后又回到第一个。
消费者线程去消费这些socketChannel时,会获取一个个request请求,这些request请求中就会伴随着数据。
线程池里面默认有8个线程,这些线程是用来处理request的,解析请求,如果request是写请求,就写到磁盘里。读的话返回结果。processor会从response中读取响应数据,然后再返回给客户端。这就是Kafka的网络三层架构。
调优点1
所以如果我们需要对kafka进行增强调优,增加processor并增加线程池里面的处理线程,就可以达到效果。request和response那一块部分其实就是起到了一个缓存的效果,是考虑到processor们生成请求太快,线程数不够不能及时处理的问题。所以这就是一个加强版的reactor网络线程模型。
Broker数据存储设计
【partition 的数据文件】
我们知道topic 是逻辑上的概念,partition是topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
例如创建2个topic名称分别为report_push、launch_info, partitions数量都为partitions=4 存储路径和目录规则为:xxx/message-folder
- |--report_push-0
- |--report_push-1
- |--report_push-2
- |--report_push-3
- |--launch_info-0
- |--launch_info-1
- |--launch_info-2
- |--launch_info-3
而partition物理上由多个segment组成。
【segment】log
每个segment 大小相等,顺序读写.
每个segment数据文件以该段中最小的offset 命名,文件扩展名为.log
日志回滚受log.segment.bytes控制,默认1G;
这样在查找指定offset 的Message 的时候,用二分查找(跳表)就可以定位到该Message 在哪个segment 数据文件中.
在磁盘上,一个partition就是一个目录,然后每个segment由一个index文件和一个log文件组成。如下:
- $ tree kafka | head -n 6
- kafka
- ├── events-1
- │ ├── 00000000003064504069.index
- │ ├── 00000000003064504069.log
- │ ├── 00000000003065011416.index
- │ ├── 00000000003065011416.log
Segment下的log文件就是存储消息的地方
每个消息都会包含消息体、offset、timestamp、key、size、压缩编码器、校验和、消息版本号等。
在磁盘上的数据格式和producer发送到broker的数据格式一模一样,也和consumer收到的数据格式一模一样。由于磁盘格式与consumer以及producer的数据格式一模一样,这样就使得Kafka可以通过零拷贝(zero-copy)技术来提高传输效率。
【segment】index
索引文件是内存映射(memory mapped)的。
索引文件,一个稀疏格式的索引,受参数log.index.interval.bytes控制,默认4KB。即不是每条数据都会写索引,默认每写4KB数据才会写一条索引。
Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index.
index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引.
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
有关内存映射:
- 即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。通过mmap,进程像读写硬盘一样读写内存,也不必关心内存的大小有虚拟内存为我们兜底。mmap其实是Linux中的一个用来实现内存映射的函数,在Java NIO中可用MappedByteBuffer来实现内存映射。
【Kafka中通过offset查询消息内容的整个流程】
Kafka 中存在一个 ConcurrentSkipListMap 来保存在每个日志分段。
offset-->concurrentSkipListMap-->找到baseOffset对应的日志分段-->读取索引文件.index-->找打不大于offset-baseoffset的最大索引项-->读取分段文件(.log)-->从日志分段文件(.log)中顺序查找
当前索引文件的文件名即为 baseOffset 的值。
【日志留存策略】
Kafka 会定期检查是否要删除旧消息,见参数
log.retention.check.interval.ms,默认5分钟。当前有三种日志留存策略:
基于空间:log.retention.bytes,默认未开启;
基于时间:log.retention.hours(mintues/ms),默认7天;
基于起始位移:Kafka 0.11.0.0版本引入,解决流处理场景中已处理的中间消息删除问题。
目前基于时间的日志留存策略最常使用。
调优点2
即尽力保持客户端版本和 Broker 端版本一致
即尽力保持客户端版本和 Broker 端版本一致。不要小看版本间的不一致问题,它会令 Kafka 丧失很多性能收益,比如 Zero Copy。
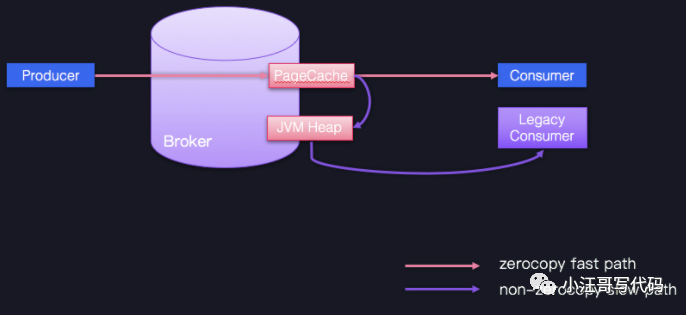
图中蓝色的 Producer、Consumer 和 Broker 的版本是相同的,它们之间的通信可以享受 Zero Copy 的快速通道;相反,一个低版本的 Consumer 程序想要与 Producer、Broker 交互的话,就只能依靠 JVM 堆中转一下,丢掉了快捷通道,就只能走慢速通道了。因此,在优化 Broker 这一层时,你只要保持服务器端和客户端版本的一致,就能获得很多性能收益了。
Broker 副本机制
分区副本默认1,见参数
default.replication.factor。
【副本作用(并不提供读写分离)】
1、实现冗余,提高消息可靠性
2、实现高可用,参与leader选举,在leader不可用时提高可用性。
3、leader处理partition的所有读写请求;follower会被动定期地去复制leader上的数据
【leader副本选举】
1、由控制器负责
2、选举机制或策略
所有的副本(replicas)统称为Assigned Replicas,即AR
副本同步队列(ISR)
SR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟。任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR
基本策略是从AR中找第一个存活的副本,且该副本在ISR中。
3、leader来维护:leader有单独的线程定期检测ISR中follower是否脱离ISR, 如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
【副本机制的好处】
通常来讲副本机制的好处:
1、提供数据冗余。即使系统部分组件失效,系统依然能够继续运转,因而增加了整体可用性以及数据持久性。
2、提供高伸缩性。支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量。
3、改善数据局部性。允许将数据放入与用户地理位置相近的地方,从而降低系统延时。
对于 Apache Kafka 而言,目前只能享受到副本机制带来的第 1 个好处,也就是提供数据冗余实现高可用性和高持久性。
对于客户端用户而言,Kafka 的追随者副本没有任何作用,它既不能像 MySQL 那样帮助领导者副本“抗读”,也不能实现将某些副本放到离客户端近的地方来改善数据局部性。
Broker 高水位机制
【概念】
HW即高水位,是Kafka副本对象的重要属性,分区的高水位由leader副本的高水位表示,含义是被follower副本同步之后的位置。
对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费
【作用】
定义消息可见性,只有分区高水位以下的消息才能被消费;
帮助kafka完成副本同步,kafka是基于高水位实现的异步的副本同步机制。
【LEO的概念】
含义是日志末端位移(Log End Offset),下一条消息写入的位移。
总结为什么MySQL的索引不采用kafka的索引机制?
既然kafka那么优秀那么快,为什么MySQL的索引不采用kafka的索引机制?
我们还要考虑一个问题:InnoDB中维护索引的代价比Kafka中的要高。Kafka中当有新的索引文件建立的时候ConcurrentSkipListMap才会更新,而不是每次有数据写入时就会更新,这块的维护量基本可以忽略,B+树中数据有插入、更新、删除的时候都需要更新索引,还会引来“页分裂”等相对耗时的操作。Kafka中的索引文件也是顺序追加文件的操作,和B+树比起来工作量要小很多。
其实说到底还是应用场景不同所决定的。MySQL中需要频繁地执行CRUD的操作,CRUD是MySQL的主要工作内容,而为了支撑这个操作需要使用维护量大很多的B+树去支撑。Kafka中的消息一般都是顺序写入磁盘,再到从磁盘顺序读出(不深入探讨page cache等),他的主要工作内容就是:写入+读取,很少有检索查询的操作,换句话说,检索查询只是Kafka的一个辅助功能,不需要为了这个功能而去花费特别太的代价去维护一个高level的索引。前面也说过,Kafka中的这种方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中。