我们知道分布式系统中各个服务器都是通过网路进行连接的,这样导致的结果就是你很难知道各个服务器的真实状况,比如你判断另外一台服务器是否有问题的唯一办法就是发送一个请求给他,只有收到了回应,你就认为它是好的,假如没有收到回应,你就很难判断对面的服务器是否有问题,因为这个没有回应很可能是发生了网络故障,也可能是对端机器真的出问题了。 因此,在分布式系统中我们如何来准确判断这些问题呢? 本文就来详细介绍相关的方法。
基于多数的(Majority)事实
很多时候我们一个节点可能不是真的有问题,比如说它正在进行 GC ,那么在 GC 的这段时间内它就不能回应任何请求,这个时候从节点本身的来看,它自己是很 ok 的,没有任何问题。 然而从 别的节点来看,这个 GC 的节点就和出问题的节点一模一样,发请求它不回,重试也没有反应。 所以别的节点就会认为它是有问题的。 从这个角度来看,节点本身其实也是很难知道自己是否问题的。
现在比较流行判断节点是否有问题的算法都是基于多数的决策,比如说我有5个节点,那么大家一起来投票,假如有超过一定数量的节点(一般来说超过半数,这里就是有三个节点)认为它有问题,那么我们就认为这个节点是真的有问题。哪怕这个节点本身是没有问题的,但是只要有多数认为有问题,我们就认为它有问题。这里使用多数来决定是因为多数就意味着不会有冲突,因为一个系统中不可能存在两个多数,只可能有一个。
Leader和Lock
为什么我们要去判断一个节点是否有问题呢?事实上,在分布式系统中,有很多场景会使用到一个只能一个的概念,比如:
-
一个数据库partition中只能有一个节点是leader
-
为了防止同时写,只能有一个transaction或者client允许hold 某个object的lock。
-
一个用户名只能由用户注册,因为它必须唯一。
这些场景都需要我们在设计的时候小心一点,比如说即使一个节点认为它自己是这个选中的唯一(比如认为它自己的leader,认为它拿到这个object的lock等等),也可能大多数别的节点认为它有问题,这个时候假如设计不好的话,就会出问题,我们来看下面这个例子:
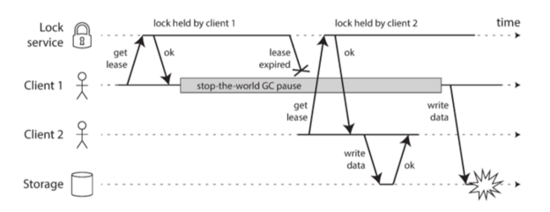
这个例子中,我们为了防止有多个client访问同样的数据,会要求每个client在写之后要先抓一下锁。这个锁是一个lease的锁,就是超时会释放的。这里你可以看到Client1首先申请了这个锁,但是很不幸,在拿到这个锁之后,它立即发生了一个GC,而这个GC发生的时候超过了lease的timeout,这就导致这个锁在lease超时之后被释放了,而client2就拿到了这个锁,做了一个更新。而client1在GC回来之后认为它是拿着这个锁的,所以它直接也去写了,这个时候就出现问题了。这里的问题就是GC回来之后,client1错误地认为它自己还是拿着锁的。
Fencing Tokens
那么如何处理上面这种错误认知呢?一个常见的技术是fencing。如下图所示:
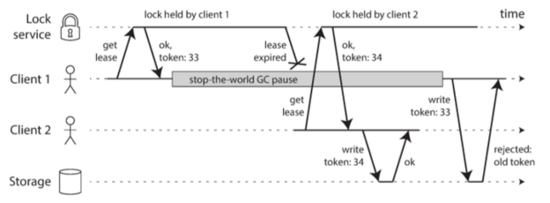
这里做的改变就是每次我们去拿锁的时候会返回一个token值给client,这个token每次拿到锁的时候都会递增。这样在client写的时候必须同时把这个token也发送回来。这样一来storage就可以可根据这个token来判断是否reject旧的token的写。
一个常见的实现方式就是使用ZooKeeper的TransactionID或者node version来作为fencingToken。
拜占庭问题(ByzantineFaults)
上文中说的FencingToken有一个前提,就是client发过来的token是它真正收到,你可以想象假如client在写的时候发送的token是一个假的token,那么显然fencingToken就也会有问题了。所以对于分布式系统来说,假如有节点说谎,那么问题就会变得更加复杂,我们称这种情况为拜占庭问题,也就是我们常说的拜占庭将军问题。
我们可以简单认为在一个有拜占庭问题的系统中,可能会有那么一两个节点给出的消息是不可靠的。这种不可靠可能是因为:
-
机器的memory或者CPU registry中的数据因为一些原因出了问题。比如说我们读registry的时候出错了,就返回一个default值,或者任意的值等等。
-
比如说有一些cheat或者attack发生。这种情况下节点就是不可信的。
当然,在现实中,我们认为这种不可信的问题它发生在比较少的节点,而不是大多数或者所有。所以假如有任何不可信的事情发生在多数节点上(比如有个code的bug,总是把收到的token加一个随机数),那么相应的算法也是没有办法解决这个问题的。
减少谎言的存在
虽然我们认为有谎言的节点是很少的。但是假如我们能够有一些机制去探测或者保护节点,那显然会更好,比如:
-
网络的包,我们会加一些checksum来检测它是否正确。
-
对用户的输入值加一些检查,比如看是否在一个合理的范围内。
-
NTP的客户端连接多个地址,然后看majority的反馈来决定真实的时间等。
系统模型和现实
我们设计了很多算法来解决各种分布式系统中的问题。而这些算法都是基于一系列的软件和硬件对的,也就是说有很多假设,而这些依赖就是我们俗称的系统模型。
比如说我们谈到时间假设,下面这三种就是常见的系统模型:
同步模型
所谓同步模型就是指你知道网络延时,process的暂停和时钟的漂移不会超过某一个限制值。当然不是说没有网络延时,只是说你知道它不会超过一个界限。当然这种模型其实在现实中是不现实的,因为总有意料之外的延时会发生。
部分同步模型
所谓部分同步模型就是我们认为大多数时候是同步模型,就是不会超过一定的限制,但那是有时还是会超过这些限制。这个就是一个比较现实的模型。
异步模型
这种模型就是不做任何假设,甚至连时钟多不信任,比如不是用超时。限制这种模型的限制就非常大。
除了上面的关于时间的假设,还有一个比较常见的问题就是节点失败的假设,通常有下面这三种模型:
Crash-stop错误
这种模型下,算法认为一个节点出问题了,比如不响应了,就再也不会回来了。
Crash-Recovery错误
这种模型下,算法认为一个节点出问题了,它一会还会回来。当然什么回来不知道。这就要求节点可能需要一些能够常见保存的介质,比如很多东西写到磁盘中去,这样即使crash了之后还能恢复。
拜占庭错误
节点有可能发生任何事情,就像我们上面说的那样。
我们在现实中最常见的模型就是部分同步的crash-recovery错误。那么分布式系统的算法如何使用这些模型呢?
算法的正确性
我们判断算法的正确性的时候,需要使用一些属性来判断。比如一个从小到大的排序算法,输出中的两个不同的元素就需要满足前面的比后面的小。这就是一个最简单的判断方法。
同样的,那么我们如何判断分布式系统中的算法是否正确呢?我们还是以上面那个拿锁为例,我们可以有下面这些属性来进行判断:
唯一性
没有任何两个请求得到的token是一样的。
单调递增
假如请求x的token是tx,请求y的token是ty,x在y前面,那么tx<ty。
可靠性
假如有节点发送了请求,那么只要不crash它最终都能收到response。
安全和活力
这里我们需要区分两个概念,一个是安全一个是活力(Liveness)。比如上面的例子中的唯一性和单调递增就是安全,可靠性就是活力。简单区分这两者就是安全一般指坏的不能发生,活力指好的最终会发生。区分这两者有助于我们处理比较复杂的系统模型。
总结
本文详细介绍了分布式系统中对真实的判断和处理,希望大家能有一个大概的了解。