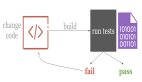
最近的十几年深度学习发展十分迅速,业界出现了很多深度学习算法开发框架。同时,由于深度学习具有广泛应用场景和对算力的巨大需求,我们需要将深度学习算法运行在各种通用和专用的硬件上,比如各种类型的CPU,GPU,TPU,NPU等。那么这就出现了框架和硬件之间的组合爆炸,如图 1所示。比如说TensorFlow要支持GPU计算,就要把tensorflow里面的所有算子开发一个GPU版本,如果又要支持D芯片,又需要把每个算子开发一个D芯片的版本。这个过程无疑非常耗时耗力。

图 1
于此同时,我们现在有非常多的算法网络,比如说YOLO, BERT, GPT等等。而这些算法网络是是由不同类型、不同shape,不同连接关系的算子组成的。最终它们又运行在不同种类和型号的硬件上面。这就导致人工去为每个场景开发和实现最优算子成本很高。这里举了两个例子,如图 2所示,算子融合是一个常见的性能优化方法,在融合之前,每个算子计算前后都需要把数据从内存读到缓存,再从缓存写回到内存。而融合之后,可以避免算子之间内存读写从而提高性能。传统的做法就是人工去根据算子连接关系开发融合算子,但是不同网络不同类别算子连接关系几乎不可能完全枚举。另一个例子就是算子调优,算子实现过程有很多参数会影响性能,但是传统人工算子开发方式很难去表达和维护这些参数,并且对这些参数进行调优从而实现不同shape和硬件的最优性能。
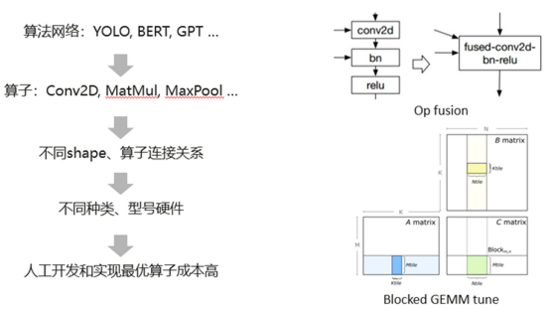
图 2
深度学习编译器正是为了解决上面一系列问题而诞生的,它可以作为框架和硬件之间的公共组件和桥梁,最终希望实现的目标是我们只用开发一次,就能够为自动为任何设备生成最优代码。比如为CPU开发的算子可以几乎原封不同的用于GPU和D芯片,从而显著降低成本。
这里简单介绍一下深度学习编译器的组成部分和功能,如图 3所示。首先它的前端是从不同的框架拿到计算图,并且使用这个High level IR的数据结构来表示,然后在这个阶段进行一系列图优化,比如常量折叠,算子融合,等价替换等。这里展示了一个等价替换的例子,原来计算图是这样的,我们给它换一个计算方式,结果不变,但是性能可能更优。接着,对于计算图里面的每一个算子,采用DSL一种领域特定的语言来描述算子的计算过程和对算子进行优化。比如对算子进行tiling,多核,double-buffer等优化。由于算子的计算过程通常是用多重循环来实现的,比如说矩阵乘法是一个三重的循环。深度学习编译器可以很方便的对循环进行各种变换,并且对这些变换的参数进行调优,从而得到不同shape和硬件的最佳算子实现。最后,基于low level IR为不同硬件生成具体的代码。
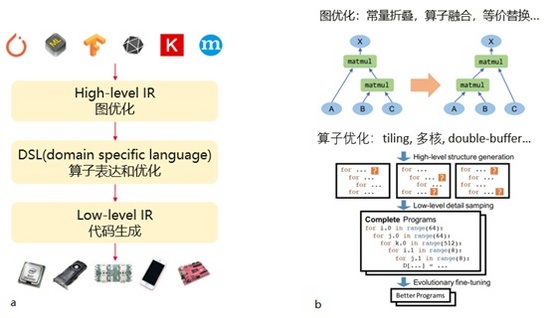
图 3
最后介绍下业界已有的编译器项目。目前生态最完善,开源的,框架不依赖的项目首推TVM,已经被很多公司所采用。TVM流程如如图 3a所示,TVM可以导入各个框架的模型,例如TensorFlow pb,onnx,TorchScript等模型,统一用TVM称为Relay的High level IR进行表示。IR中每个算子采用了Tensor expression的DSL来进行计算描述和调度。这个DSL采用Einstein’s notation的方式进行算子的compute描述,算子compute一般体现为多重for循环。然后基于Halide思想使用schedule对这个多重for循环进行各种变换,例如循环合并,split,顺序变换等等。最后,lower到low-level IR生成具体的device代码并进行推理。
这里再简单介绍下TVM具体如何生成最优的算子代码。上面介绍了算子需要进行compute描述,然后需要对compute对应的多重for循环进行调度变换,即schedule。TVM的算子生成和调优经历了3代发展。第一代TVM/AutoTVM,这一代需要用户编写算子的compute和算子的schedule,AutoTVM与TVM的区别在于可以在schedule定义一些可变的参数,然后采用例如遗传算法进行参数调优。例如把一个loop切分为2段,那么在哪里进行切分是可以进行优化的。第二代AutoScheduler (Ansor),这一代只需要用户开发算子ompute,Ansor内部自动根据一些规则进行调度变换。由于调度开发需要同时熟悉TVM的表达机制和底层硬件原理,schedule开发往往具有很高的难度,因此Ansor可以显著降低开发人员工作量和开发难度,缺点就是Ansor调优时间很长,往往需要1小时才能调优1个算子。以卷积网络为例,Ansor在部分场景能超过TensorFlow算子性能,距离TensorRT实现有一定差距。第三代Meta Schedule (AutoTensorIR)才处于起步阶段,预期会对调优速度和性能进行优化,暂时还不可用,我们拭目以待。
TVM的落地包括华为D芯片TBE算子开发工具,在TVM的基础上增加了D芯片的代码生成支持。TVM采用了Halide计算+调度的路线,还有另外一种采用polyhedral算法路线的编译器,比如Tensor Comprehensions,Tiramisu,华为自研的AKG等。这种方法跟Ansor一样,也只需要用户开发算子compute,无需开发schedule,因此对用户也较为友好。其中AKG已经用在了MindSpore的图算融合里面。其他的深度学习编译器还有TensorFlow的XLA、TensorRT等,大家可能已经用过。
总之,深度学习编译器具有很多优势。比如易于支持新硬件,避免重复开发,采用一系列自动优化代替人工优化,可以实现极致性价比等。目前深度学习编译器也有一些不足,仍然出于一个快速发展的状态。例如调优时间长,对于复杂的算子无法有效生成,一个模型中深度学习编译器生成的算子能超过库调用的算子比例较低等,仍然需要大家持续投入和优化。