













1. Introduction
广告主通常会基于用户标签来圈定广告的目标人群,比如广告主想投奥迪的广告可能会选择北方 25~44 岁男性;投奔驰可能会选择江浙地区 25 ~55 岁男性。

但受限于广告主的先验知识,其选出来的目标人群通常非常小,不能满足投放要求。比如说广告主想投放 100w 人,但通过用户标签只选出来 10w 用户,那幺剩下来 90w 用户该怎幺选择?
如果把广告主圈出来的那 10w 用户称为种子用户( 「seed users」 ),那幺我们可以把需要额外提供的一批相似的用户称之为 「look-alike users」 。我们把这种基于种子用户进行相似人群扩展的过程称之为 「look-alike modeling」 。所以,look-alike 并不是某种特定的算法,而是一类建模方法的统称。
2. Look-alike
Look-alike 有多种类型,包括基于相似计算的 「Similarity-based」 ,基于回归模型预测的 「Regression-based」 ,基于标签相似性的 「Approximation-based」 ,基于用户相似网络的 「Graph-based」 ,基于 attention 优化的 「Attention-based」 等。
但这种划分有些不太合理,所以打算直接这里介绍一些经典的 look-alike 模型。
2.1 Turn Look-alike
Weighted Criteria-based Algorithm 是由广告科技公司 Turn 构建的一套 Approximation-based 算法,发表于 ACM 2015,该算法主要是通过计算相关标签进行人群扩散,其从相似性、新奇性和质量分三个角度综合评估标签对。
相似性的计算公式有:
为指示函数,有标签的则为 1,否则为 0;为用户数量。
但这种相似性计算公式可能有两个问题:1. 由于数据稀疏,大部分用户都只有少部分标签,所以大部分标签间的相关性都比较高;2. 相关标签要幺与种子用户的标签非常大要幺非常小,这样的计算结果就显得很冗余。
所以作者采用了第二种相似性的计算公式:
此时,也有了新奇性的计算公式:
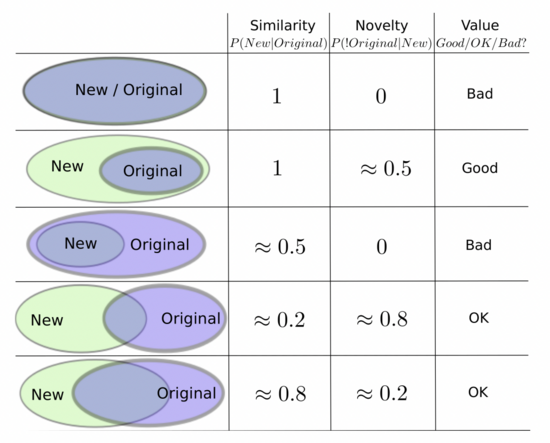
此外,还要定义质量分 q,其主要包括 CTR、CVR、ROI,这个可以自己的特定场景自己定义。
我们对上述三种指标进行加权相乘:
取 log,加上权重得到最终的评估结果:
然后我们便算出了标签之间的分数,并可以利用相似标签进行人群扩展。
2.2 Yahoo Look-alike
Yahoo Look-alike Model 是 Graph-based,其结合了 Similartiy-based 和 Regression-based 方法,系统架构如下:
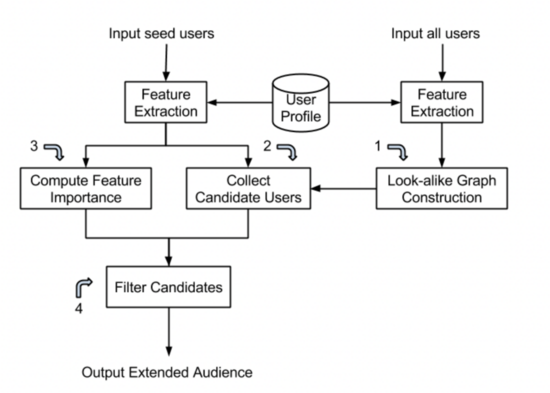
主要包含四个部分:
基于用户间相似度构建用户相似网络,并利用 LSH 对用户进行分桶;
粗召回:将种子用户在同一个桶的用户作为候选用户;
特征筛选:基于特征 IV 进行特征筛选,挑出能代表种子用户的正特征;
精排序:计算用户得分并排序,返回得分最高的用户集。
用户相似性定义如下:
其中,表示用户的特征向量,权重矩阵为单特征或者特征组合的线性相关性的重要程度,这块可以基于用户特征重要性进行构建。其时间复杂度为,搜索的时间复杂度为。Yahoo 采用了 MinHash 和 LSH 进行优化,对用户进行分桶。
然后系统基于种子用户召回同一分桶内的用户作为候选集。
由于不同的广告主所关心的用户特征不一样,比如说 K12 教育关注年龄,化妆品关注性别,所以需要事先进行特征筛选。综合考虑性能和可解释性原因,Yahoo 采用 Information Value 作为特征筛选的方法,并构建权重矩阵,
其中,S 为广告主提供的种子用户;U 为备选用户集合,可以通过采样获得也可以是整个用户集合;为正特征,表示此特征在种子用户中比其他用户更重要。
此时,用户评分方法位:
其中,为特征重要性;为特征的二阶度量。
Yahoo 系统主要用了一阶,权重为 IV,所以某个广告投放下的用户分数为:
注意,这个分数的取值为实数,如果想算概率可以用 sogmoid 函数压缩一下。
2.3 Linkedin Look-alike
Linkedin 在 KDD 16 上发表了他们的 look-alike 系统,其架构如下图所示:
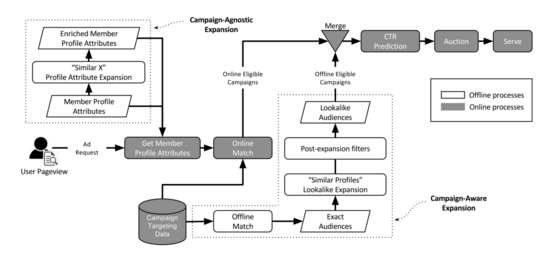
大致分为线上和线下两部分,分别称为 「Campaign-Agnostic Expansion」 和 「Campaign-Aware Expansion」 。
「Campaign-Agnostic Expansion」框架主要是利用实体进行扩展,比如 Data Mining 可以扩展到 Big Data 和 Machine Learning。该框架的算法是采用 LR 模型去从历史交互数据中捕获实体间的相似性,这种扩展方法可以直接在系统中使用 (不需要再去额外计算)。
「Campaign-Aware Expansion」框架是采用近邻搜索,基于用户的属性进行相似用户扩展。
无论是线上线下都需要用到相似度计算,这块简单介绍一下。
Linkedin 将每个实体建模为一个多域的结构化 doc(structured multi-fielded document),并提取四种类型的字段,包括:n-grams/词典、标准化命名的数据类型(standardized,公司名、行业名等)、派生数据类型(derived,互联网公司可以派生出网络开发、软件开发等)和相近实体(proximities,基于用户和公司交互的网络确定其他相关公司)。举个例子:
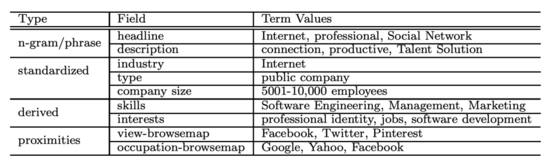
实体的结构化 doc 会被建立成倒排索引库,doc 的每个域的属性都有一个特征向量,doc 同一域之间的相似度用 cos 相似度进行计算:
doc 间的相似度利用域的相似度进行线性加权:
其中,s 为不同领域的相似度,w 为不同领域的权重。
Linkedin 将用户和公司分别进行上述实体建模,然后将用户关注的公司作为正样本,没关注的公司作为负样本,并用 LR 模型进行训练。
PS:会不会出现极端情况,导致召回量不够。
2.4 Tecent Look-alike
Realtime Attention-based Look-alike Model(RALM)是微信看一看团队提出的,其发表于 KDD19,其将 Attention 融入到 look-alike 方法中并用于实时资讯推荐,其系统架构如下图所示:
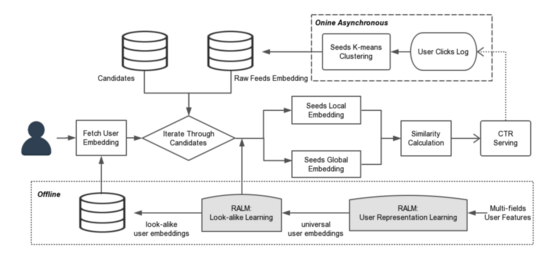
其大致分为: 「离线训练」 、 「在线实时预测」 和 「在线异步处理」 ,分别对应上图的下、中、上三个位置。
2.4.1 offline Learning
「离线训练」部分包括 User Representation Learning 和 Look-alike Learning,前者用于学习用户的特征向量,后者是基于用户特征向量计算相似分数。
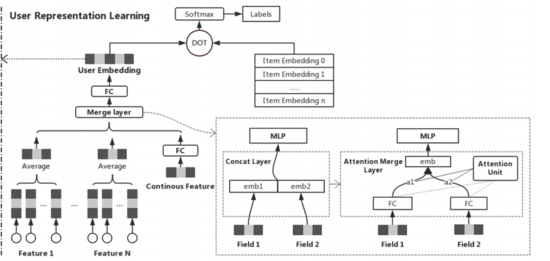
User Representation Learning 模块是基于 Youtube DNN 模型进行改进,左侧为用户特征,并用 Attention 代替 concat,左侧为 Item 特征,然后整体做 SCE Loss 或者多分类,预测用户的下一个点击,训练完成后左侧取最后一层隐层作为用户的特征向量,模型结构如下图所示:
Look-alike Learning 模块采用双塔结构,左边输入所有种子用户的特征向量,右边输入目标用户的特征向量,其结构如下图所示:
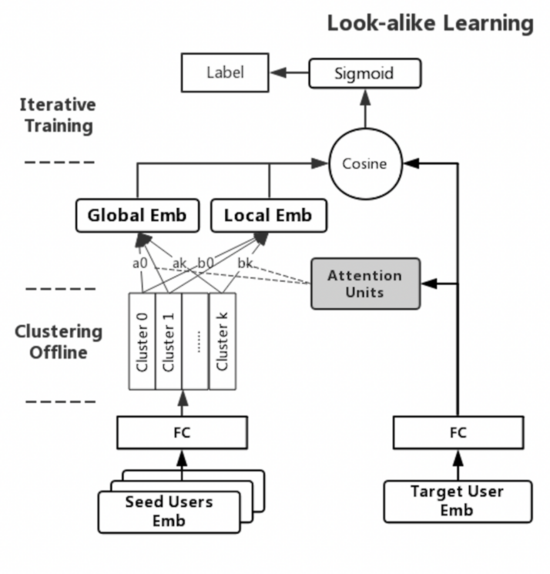
这也是 RALM 能实现实时计算的主要原因,其将种子用户特征代替 Item 特征,从而将 User-Item 模型转换成 User-Users 模型。
所以,Look-alike Learning 模块的关键在于表达种子用户群体。
假设用户会存在自己的个性信息,同时也有群体共性信息,那幺种子群体可以表示为:个性信息+共性信息。作者为此分别建模 Local Attention 和 Global Attention 学习出两种 embedding:
Local Attention 是将种子采用乘法 attention,提取种子用户群体中与目标用户相关的信息,捕捉用户的局部信息。
Global Attention 只与种子用户群体有关,所有采用 self-attention 的方式,将种子用户乘以矩阵转换,再乘以种子用户自己,用其捕捉用户群体自身内部的兴趣分布;
得到的 Local & Global embedding 之后,对此进行加权求和,这就是种子用户群体的全部信息。
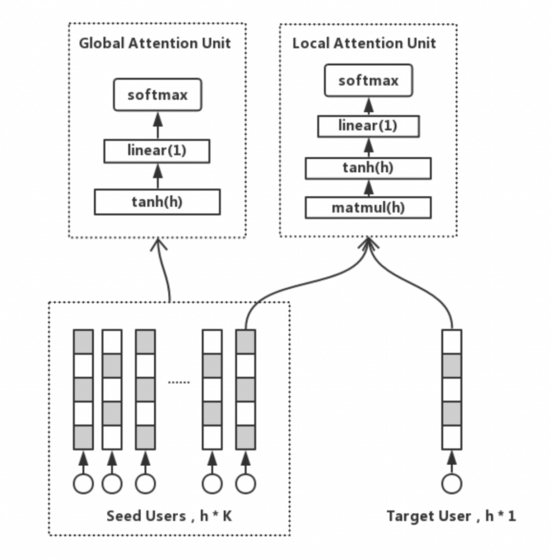
但我们知道的 Attention 本身计算量非常大,所以无法满足模型线上部署的耗时要求。为此,作者将种子用户通过 k-means 进行聚类,从而减少 Key 的数量。
完成 Look-alike Learning 之后,我们可以把右侧用户过 FC 的特征向量存储起来,提供给在线服务。
2.4.2 Online Asyncheonous
在线异步处理,主要是处理与线上请求无关的计算,如:
基于用户点击日志,更新 Item 的种子用户列表;
计算种子用户的聚类中心,并配送给推荐系统;
计算 Global Embedding。
这些所有的东西都是定时更新的,不需要进行实时计算。
2.4.3 Online Service
在线服务这块,主要是拉取种子用户的聚类中心、Global Embedding 和用户的 Embedding,线上实时计算 Local Embedding,并计算最终的相似度。
PS:RALM 因为有聚类,种子用户出现异常点可能会出现点问题(当然,内部大概率优化过了)。
2.5 Pinterest Look-alike
Pinterest look-alike 于 KDD 19 发表了他们的 look-alike 模型,其大致分为两部分基于 LR 的分类模型和基于 Embedding 的相似搜索的模型。
2.5.1 Classifier-based Approach
Pinterest 的baseline 是用 LR 模型去做个分类模型,种子样本为正样本,随机选取非种子样本为负样本,然后训练一个分类模型去给所有用户打分排序。
2.5.2 Embedding-based Approach
Pinterest 探索的新方法,大致分为两块:一块是训练 Embedding ,另一块是基于 Embedding 和 LSH 找相似用户。
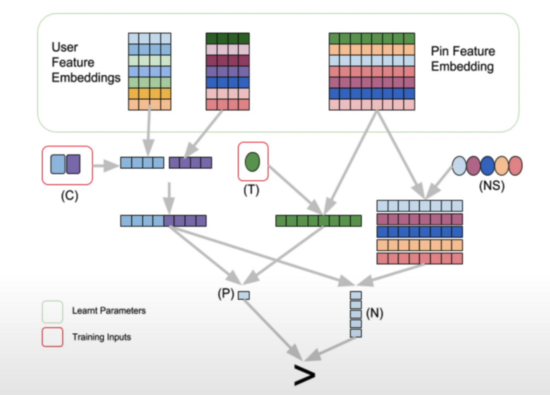
首先是计算用户的特征向量,其基于 StarSpace 的方法进行训练(Pair-wise):
用户:用户作为 Piar A,concat 用户的离散特征+归一化后的连续特征,经过一层线性激活函数的 Dense,输出得到用户特征向量;
Topic:Item 的 Topic 作为 Pair B,经过 lookup 得到 Topic 的特征向量;
训练样本:取与用户交户过的 Item,用 Item 的 Topic 作为 Pair B;其他随机选取 k 个的 Topic 作为负样本,与用户组成样本对;
训练集:与用户交户过的 Item 的 Topic 作为正样本,随机选取的 k 个 Topic 作为负样本,损失函数为:
训练停止:由于模型最终会用于解决种子用户扩散的问题,所以作者取种子用户和非种子用户,其中 90% 的种子用户组成集合 K,从剩下 10%的种子用户中取出一个,非种子用户取出一个。定义相似性:,则训练停止的评估标准为:
训练的 tensorboard 如下图所示:
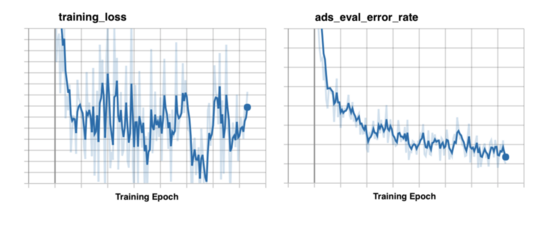
模型重训:使用模型的最新版本定期(较长的时间)重新计算用户嵌入,主要是目的是希望所有用户的兴趣都在变换,以捕捉用户的行为和用户的漂移。(为啥?)
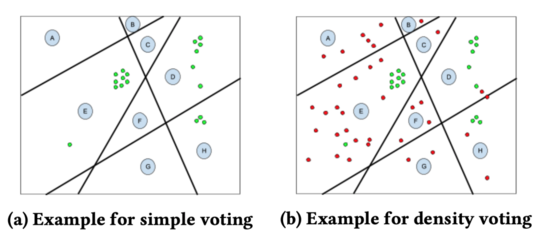
得到用户特征向量后,利用 LSH 对用户进行映射,然后基于种子用户的个数进行投票选出哪些区域,并取区域内用户作为扩展用户。
当然还要考虑每个区域的用户数量不同,所以种子集合 s 在区域的修正得分为:
其中,为区域内的所有人数,为平滑因子,且。
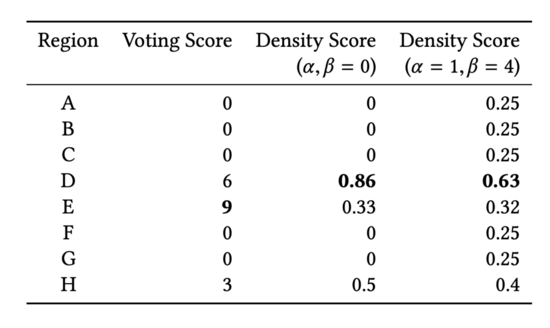
下表为各区域人数(绿色为种子用户,红色为非种子用户):
下表为投票得分和概率得分的区别,可以看到区域排名有所变化:
作者重复 m 次映射,得到最终的的概率得分:,每个用户的映射结果为,所以用户最终得分为:。
然后,选取得分大的用户作为扩展用户。
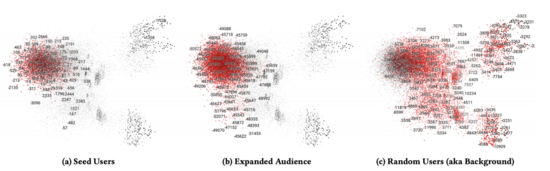
可视化结果如下图所示:
2.5.3 End-To-End System
介绍下 Pinterest 的系统:
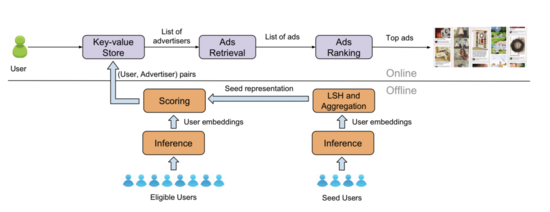
下方为离线计算:
首先,离线计算好用户的特征向量;
然后,基于种子用户 m 次映射结果,计算所有区域的得分;
再者,对最近访问过 Pinterest 用户计算得分,排序后卡一个阈值。(利用桶排序,阈值大小根据广告主需求排定,满足广告投放需求即可);
最后,组成 <user, adv> 进行广告投放;
作者在实验的时候发现,Classifier-based 和 Embedding-based 混合起来的 Blending-based 比较好用:
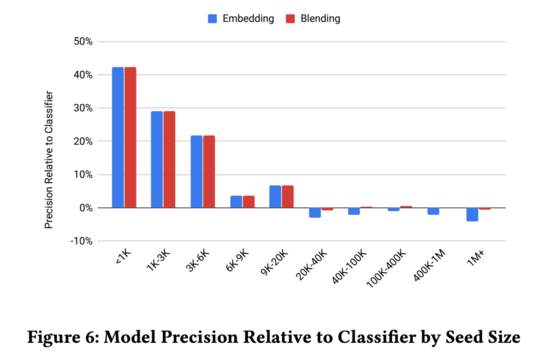
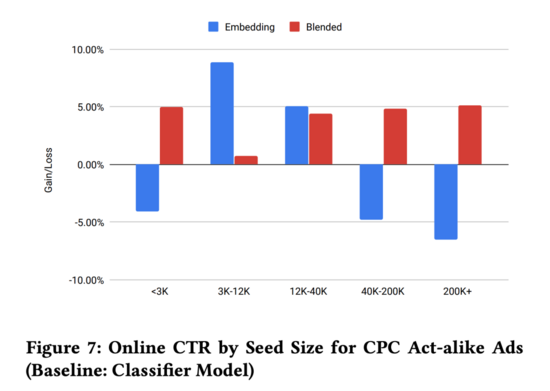
3. Conclusion
看的这几篇都是工业界的论文,最大的感触是非常实用,工业风满满,特别是最后一篇 Pinterest 的 Look-alike,论文细节非常多,也非常的实用。
4. Reference
《Effective Audience Extension in Online Advertising》
《A Sub-linear, Massive-scale Look-alike Audience Extension System》
《Audience Expansion for Online Social Network Advertising》
《Real-time Attention Based Look-alike Model for Recommender System》
《Finding Users Who Act Alike: Transfer Learning for Expanding Advertiser Audiences》
RALM:微信看一看中基于Attention机制的实时Look-alike推荐模型 (jianshu.com)





















