












GitHub Copilot凭借着自动生成代码这个强有力的噱头,推出之后就成为了讨论的焦点。
Copilot建立在OpenAI全新的Codex算法之上,其中Codex接受了从GitHub中提取的TB级公开代码以及英语语言示例的训练。
因此,GitHub声称Copilot可以做到分析文档中的字符串、注释、函数名称以及代码本身,从而生成新的匹配代码,包括之前调用的特定函数。
同时,Copilot支持多种编程语言:Python、JavaScript、TypeScript、Ruby和Go。
发布之后就有人把Copilot拉去刷Leetcode的题库,并对这位「AI程序员」的表现十分满意。
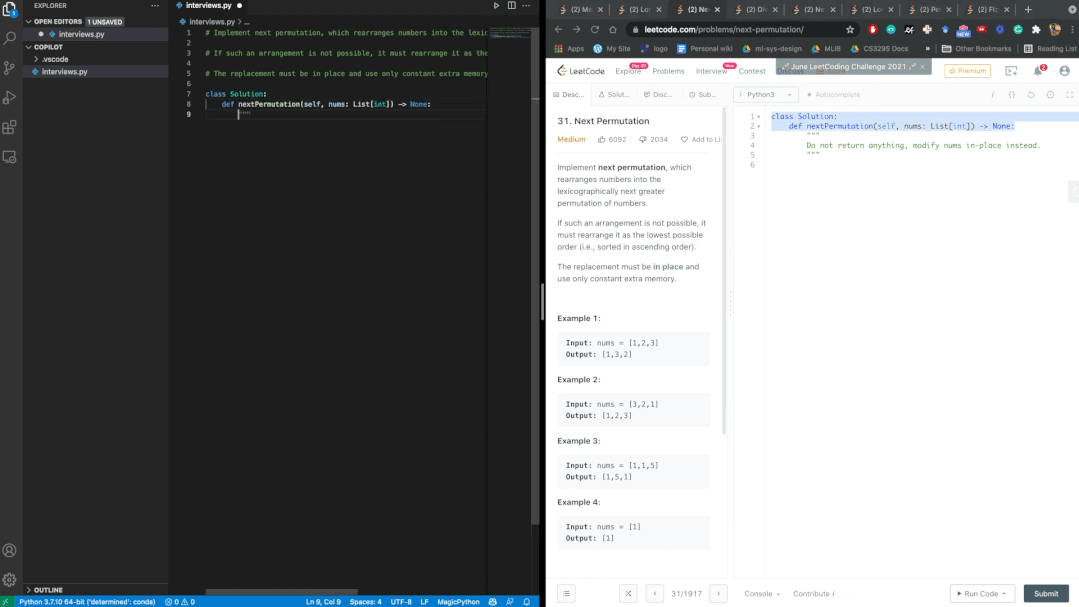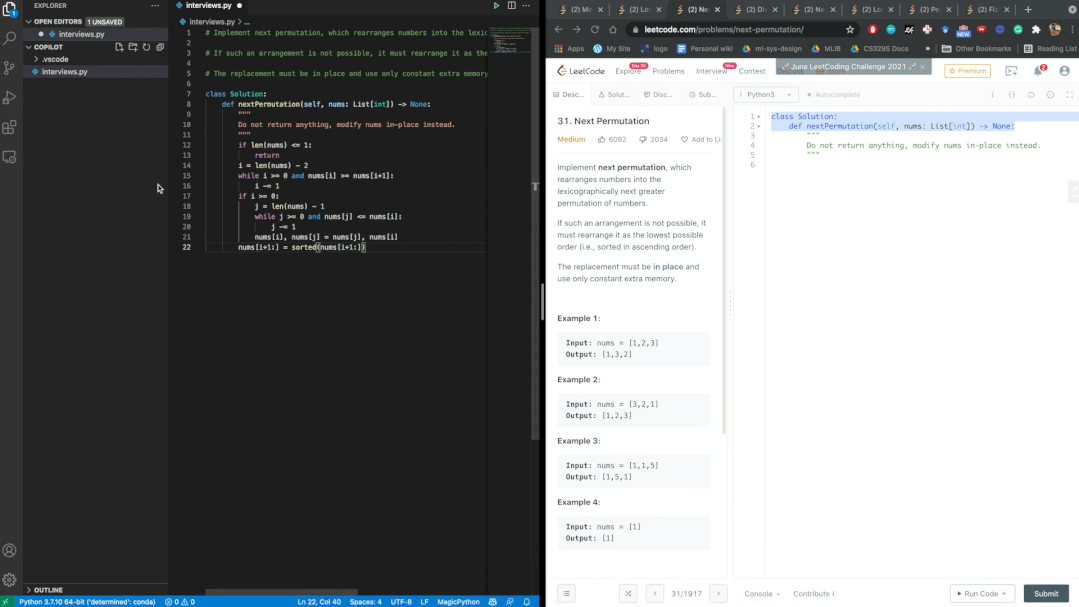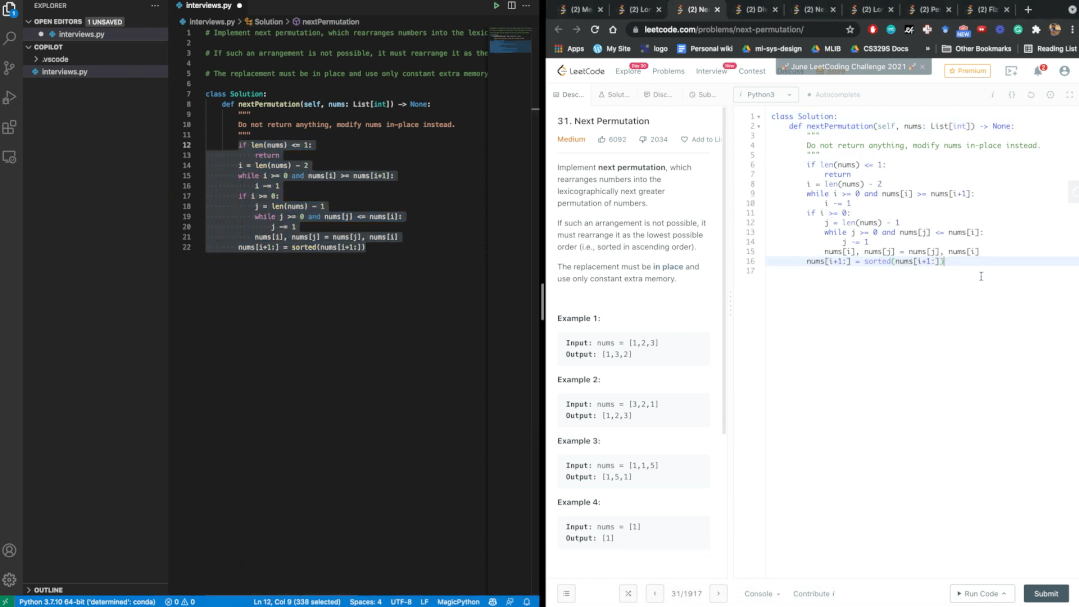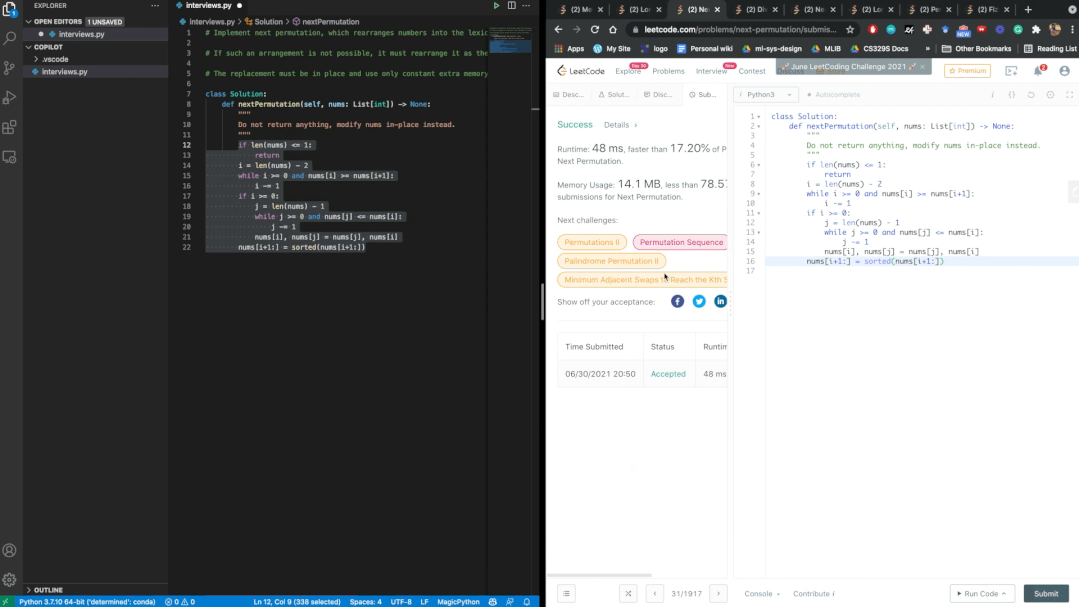
经过数个题目的验证,Copilot每次都能通过Leetcode的测试。鉴于几乎是实时的生成速度,博主表示,AI可能比我们更会编写代码。
不过网友怀疑Copilot已经在LeetCode数据库上进行过了训练,因为生成的注释和Leetcode给的模板几乎一模一样。
针对这点,GitHub表示,虽然可能有0.1%的直接引用,但是Copilot生成的代码大部分都会是原创的。
「复制-粘贴」成实锤
在发布的第二天,就有网友质疑GitHub Copilot是把免费开源的代码清洗之后,摇身一变成了赚钱的工具。
而这些代码本应该受到GPL(通用公共许可证)的保护,从而防止它们被用在商业项目中。
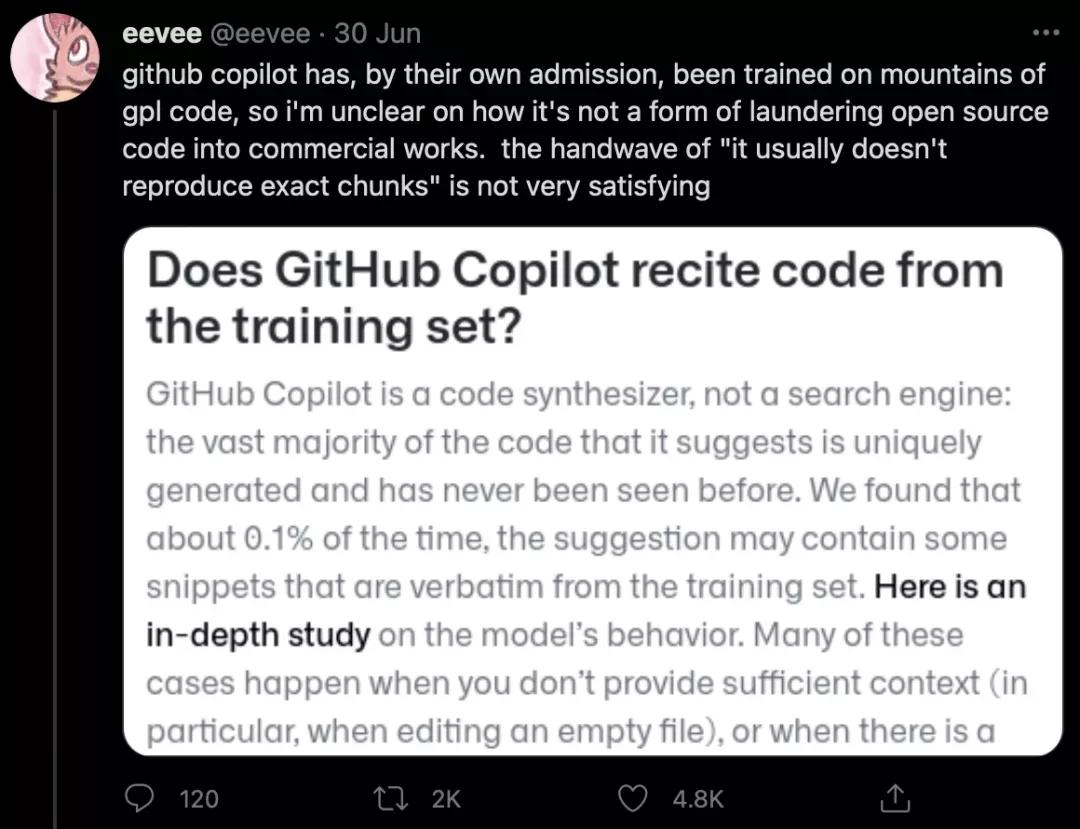
不出所料,这个怀疑没过两天就变成了实锤,有网友发现,Copilot直接「复制-粘贴」了最有名的「平方根倒数速算法」。
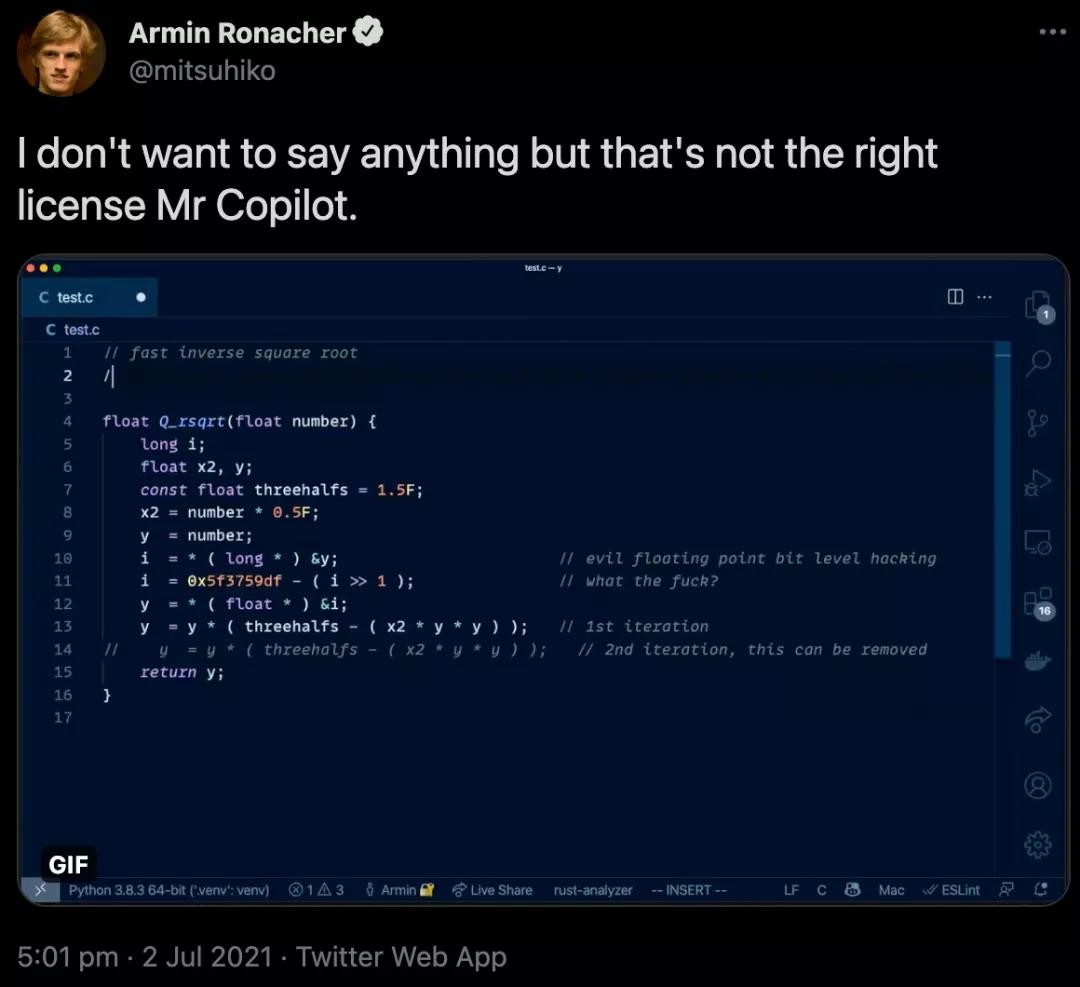
Copilot「生成」的这段代码不仅用到了至今都没有人能理解的magic number:0x5f3759df,同时还包含了对这段代码的吐槽:what the f***?。

源代码
这么看来,Copilot做的只是把训练集中别人写好的代码重新组装了一下而已。
我们的AI不「背诵」代码
不过GitHub方面似乎早就已经做了应对的准备,一位名叫Albert Ziegler的团队成员表示,截止2021年5月7日,他把Copilot对于Python的453780条建议都进行了收集,其中这些数据来自于300名员工在日常工作中的使用。
Albert针对这个数据集进行了分析整理,并写了一篇看似十分完备的博客进行讨论。
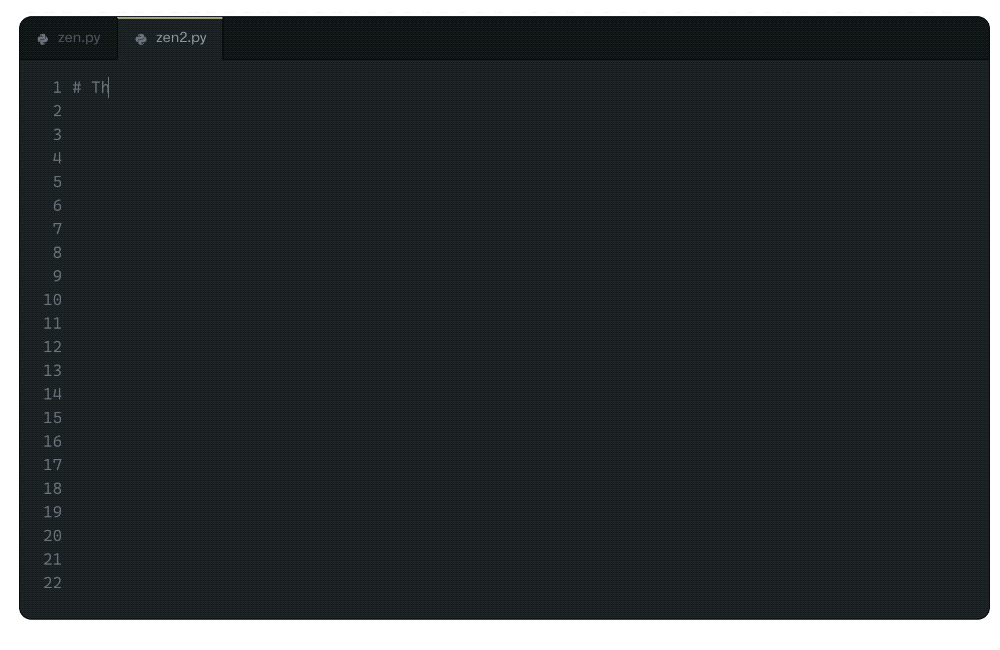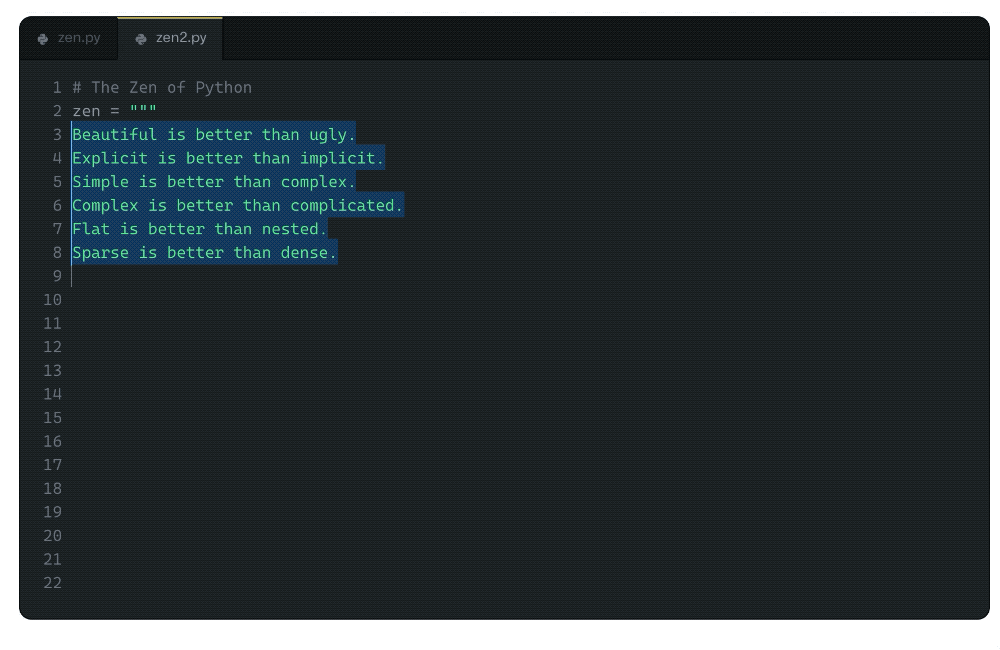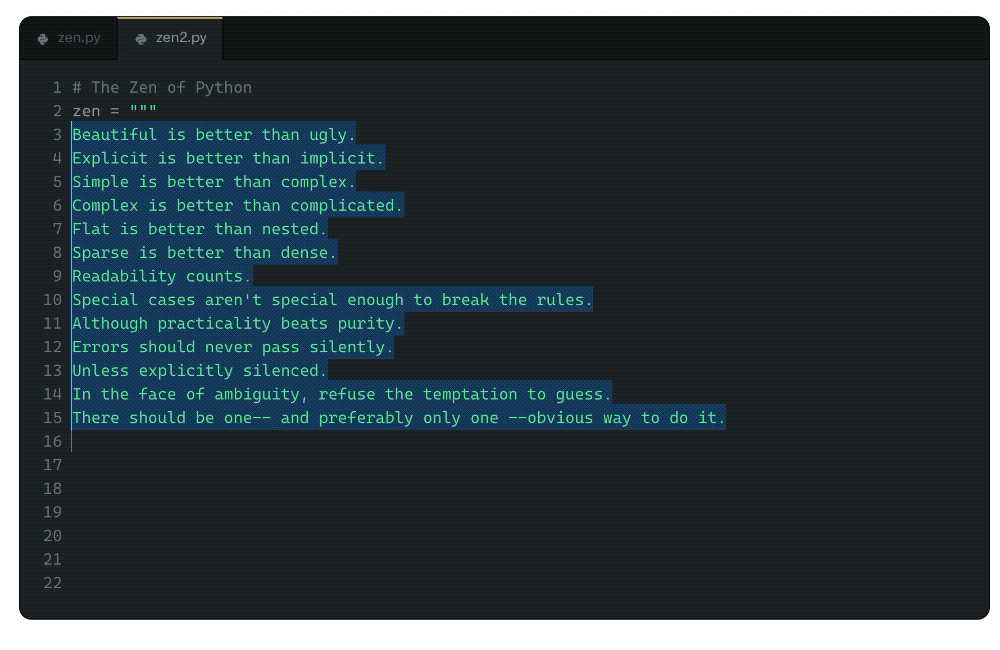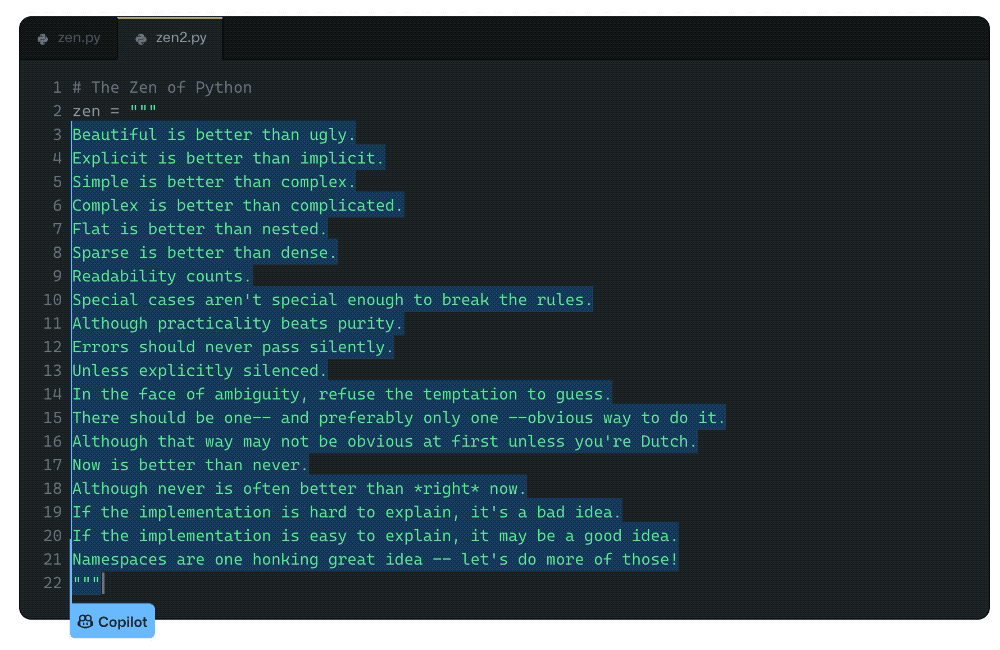
在文章的一开始,Albert便让GitHub Copilot背诵了一篇众所周知的文章,显然,Copilot已经牢牢记住了文章的内容。
不过Albert认为,记住训练集的内容不是什么问题,毕竟他自己也背诵过诗歌,而这并不会使他在日常的交流中被这些背诵的内容带跑偏。
案例分类
类别1:Copilot有时会在某个被采纳的建议之后,由于程序员新编写的注释,又提出了一个非常相似的建议。
Albert认为第二次只不过是重复了之前「成功」的案例,因此把它们从问题分析中删除了出去。
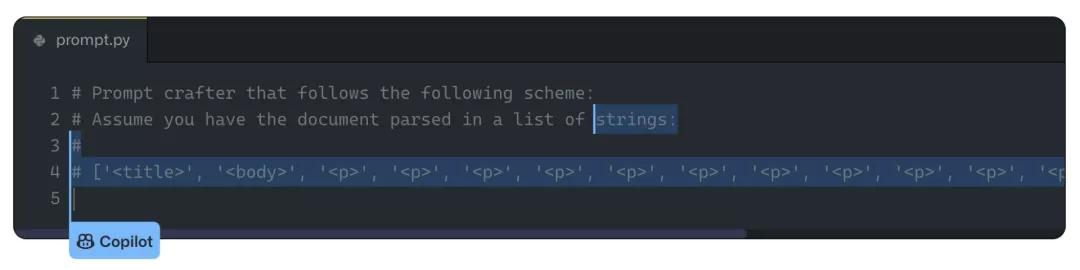
类别2:Copilot可能会提出长的、重复的序列。比如下面这个例子,其中重复的'<p>'最后在训练集中被发现了。
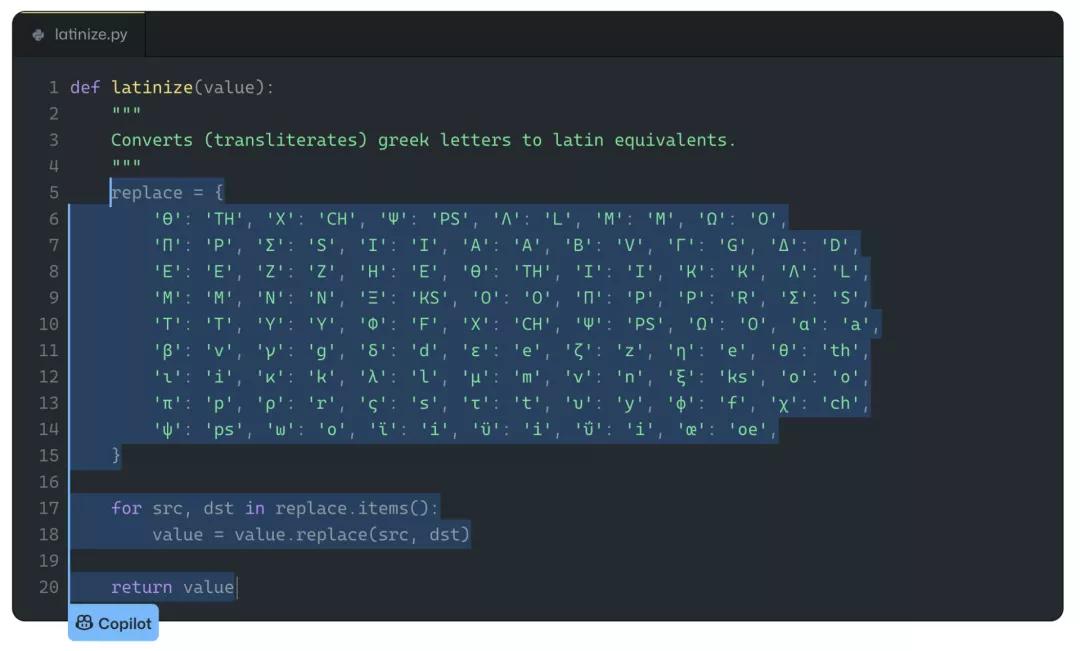
类别3:Copilot给出比如自然数、素数、希腊字母表这种类似于标准清单的建议。有些建议可能是有帮助的,也可能是没有帮助的。
不过Albert表示,这些并不符合他对「背诵」代码的假设。
类别4:在做一些自由度很低的任务时,Copilot会给出的一些常见、或者普遍的解决方案。
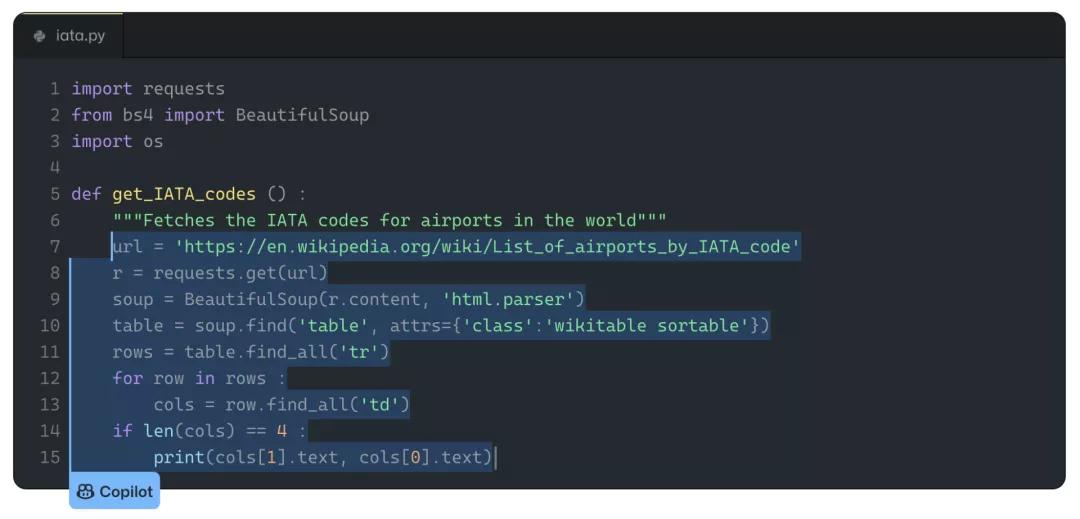
例如,下面的中间部分可以算做是使用BeautifulSoup包来解析维基百科列表的标准方法。
Albert表示,在训练数据中发现的最佳匹配片段就是使用这样的代码来解析不同文章的。同样,这不符合他对「背诵」代码的定义。
类别5:最后这些案例符合Albert对「背诵代码」的设想,其中,这些代码或注释中至少有一些具体的重叠。
测试结果
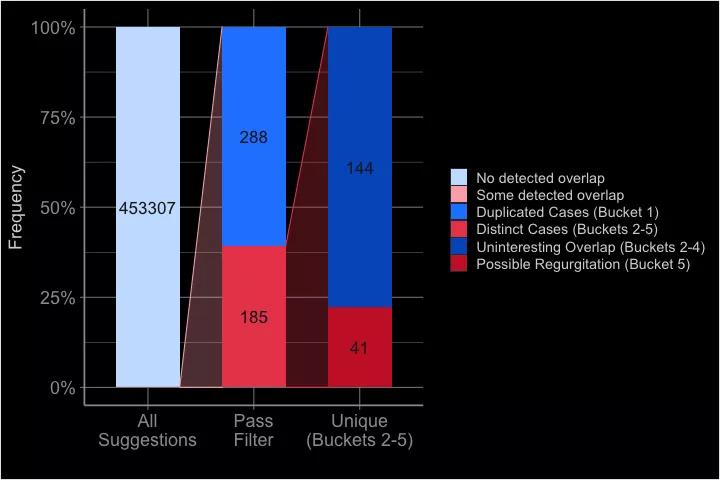
对于GitHub Copilot的大部分建议,Albert表示并没有发现与训练用的代码有任何明显的重叠。在去掉第一个类别后,可以得到了185条建议。
在这些案例中,有144个被分到了第2-4个类别中。这就在最后一个类别5里留下了41个案例,作者表示,这就是他心目中的代码 「背诵」。
GitHub Copilot在缺乏具体语境时的引语
在人工标注时挑出的41个主要案例中,没有一个出现在少于10个不同的文件中。大多数(35个案例)出现超过一百次。
有一次,GitHub Copilot建议从一个空文件开始,它在训练期间甚至看到了超过700,000次的东西--那就是GNU通用公共许可证。
下面的图表显示了第5个类别的结果(每个结果底部有一个红色标记)与第2-4个类别中的匹配文件数量。
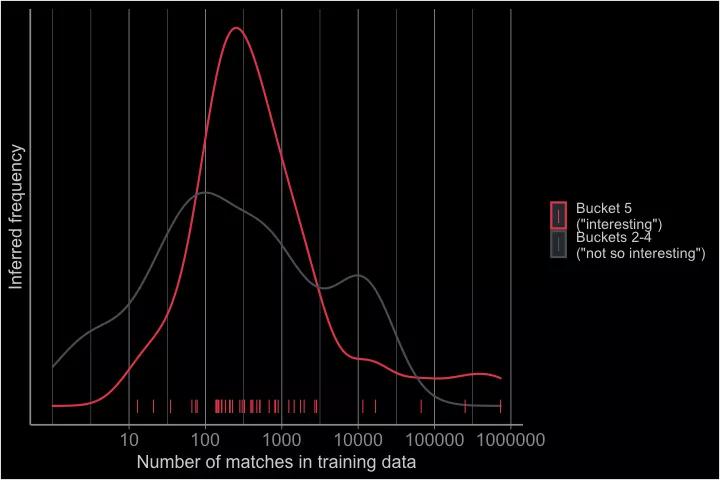
推断出的分布图显示为一条红线;它在100和1000个匹配之间达到峰值。
GitHub Copilot主要在一般情况下引证
随着时间的推移,每个文件都变得独一无二。但GitHub Copilot会将在你的文件非常通用时提供解决方案。
而此时,在没有任何具体内容的情况下,它更有可能从其他地方引用。
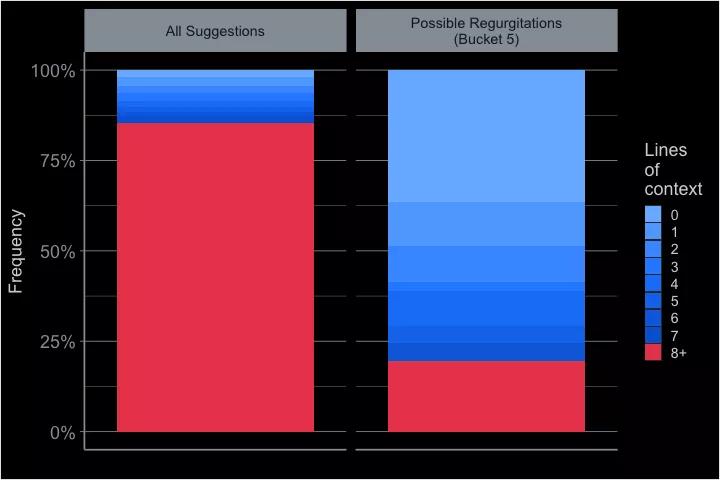
当然,软件开发者大部分时间都在复杂的代码中间,那里的上下文足够独特,GitHub Copilot会提供独特的建议。
相比之下,一开始的建议就比较中规中矩,因为GitHub Copilot无法知道程序会是什么。
不过,在独立的脚本中,适度的上下文就足以让人合理地猜测出用户想要做什么。
而有时,上下文仍然过于普遍,以至于Copilot认为它熟知的某个解决方案看起来很有希望。
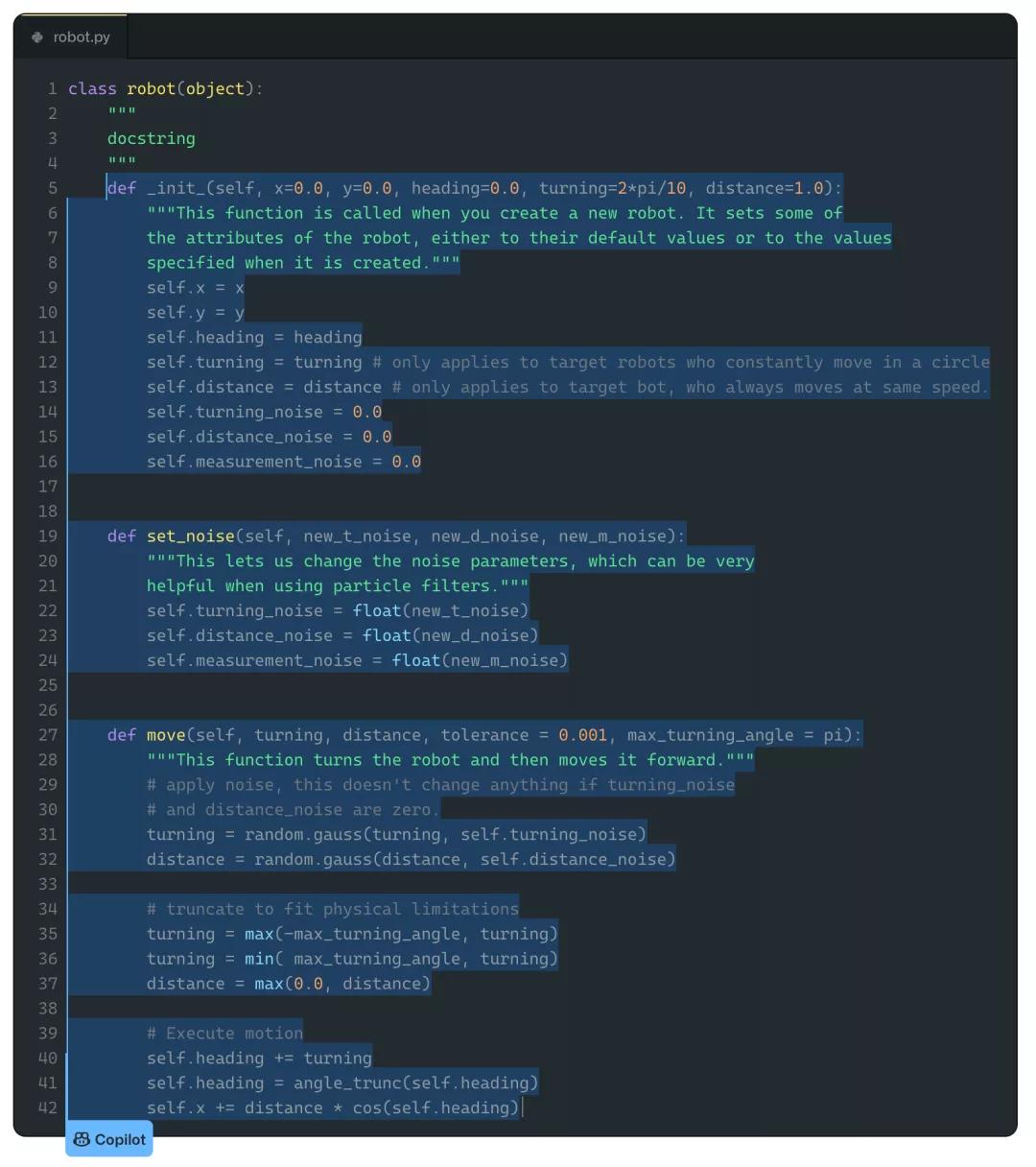
上面这个例子就是直接取自被上传的机器人课的课件。
结论
Albert认为,虽然GitHub Copilot可以逐字逐句地引用一组代码,但它很少这样做,而且当它这样做时,多数也都是所有人都会引用的代码,而且大部分是在文件的开头。
Albert表示,理想状态下,当一个建议包含从训练集复制的片段时,用户界面应该简单地告诉你它是从哪里引用的。然后,你可以包括适当的署名或决定不使用该代码。而他的团队也将努力去做到这一点。
网友评论
虽然网友在看到GitHub团队有在关心「复制粘贴」的问题之后表示了欣慰,然而,这篇「调查」显然很难让人信服。
「这会导致每一个爱好者都面临风险,同时,把『这东西可能会生成GPL的代码?』这种担忧推到任何一个在企业中工作的人的面前。」
「你不能仅仅依据 『嗯,它们略有不同』,从而推断出『所以它们不是真正的相同的东西』, 如果它实质上是相似的,就需要被引用。」

对于Copilot来说,可能还有很长一段路要走。

























