












本文转载自微信公众号「逸言」,作者逸言。转载本文请联系逸言公众号。
在我们的数据平台产品中,为了简化开发,对Flink做了一层封装,定义了Job和Flow的抽象。一个Job其实就是Flink的一个作业,每个Job可以定义多个Flow,一个Flow可以理解为是Flink的一个DataStream,利用Job传递的StreamExecutionEnvironment可以在Flow中添加包括Source与Sink的多个算子。
Job与Flow之间的关系可以利用自定义的@JobFlow注解进行配置,如此就可以在执行抽象的AbstractJob的run()方法时,利用反射获得该Job下的所有Flow,遍历执行每个Flow的run()方法。在Flow的run()方法中,才会真正根据StreamExecutionEnvironment执行多个算子。
Flink为了保证计算的稳定性,提供了不同的重启策略。例如,当我们将重启策略设置为失败率(failure-rate)时,如果执行的任务出错次数达到了失败率配置的要求,Flink的Worker节点的TaskManager就会重启。如果超过重启次数,Task Manager就会停止运行。
失败的原因可能有很多,例如资源不足、网络通信出现故障等Flink集群环境导致的故障,但是也可能是我们编写的作业在处理流式数据时,因为处理数据不当抛出了业务异常,使得Flink将其视为一次失败。
为了减少因为业务原因抛出异常导致Task Manager的不必要重启,需要规定我们编写的Flink程序的异常处理机制。由于封装了Flink的Job,从一开始,我就考虑一劳永逸地解决业务异常的问题,即在AbstractJob的run()方法中,捕获我们自定义的业务异常,在日志记录了错误信息后,把该异常“吃”掉,避免异常的抛出导致执行失败,造成TaskManager的重启,如:
- public abstract class AbstractFlow implements Flow {
- public void run() {
- try {
- runBare();
- } catch (DomainException ex) {
- //...
- }
- }
- protected abstract void runBare();
- }
哪知道这一处理机制压根儿就无法捕获业务异常!为什么呢?这就要从Flink的分布式机制说起了。
在Flink集群上执行任务,需要Client将作业提交给Flink集群的Master节点。Master的Dispatcher接收到Job并启动JobManager,通过解析Job的逻辑视图,了解Job对资源的要求,然后向ResourceManager(Standalone模式,如果是YARN,则由YARN管理和调度资源)申请本次Job需要的资源。JobManager将Job的逻辑视图转换为物理视图,并将计算任务分发部署到Flink集群的TaskManager上。整个执行过程如下图所示:
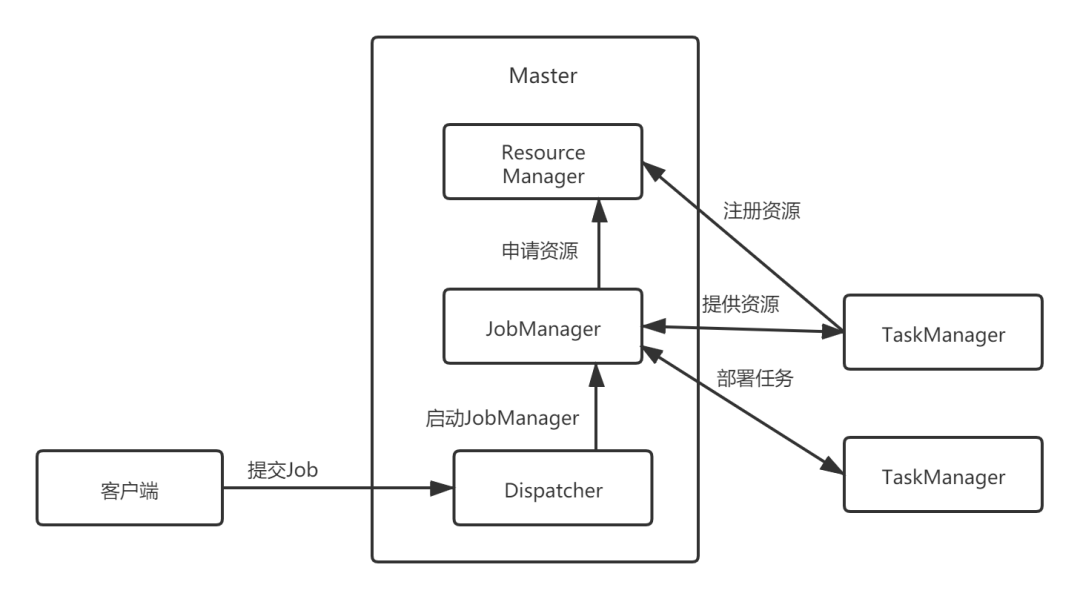
我们封装的一个Flow,在物理视图中,其实就是一个作业,即前面所说的计算任务。一个作业可以包含多个算子。如果相邻算子之间不存在数据Shuffle、并行度相同,则会合并为算子链(Operator Chain)。每个算子或算子链组成一个JobVertex,在执行时作为一个任务(Task)。根据并行度的设置,每个任务包含并行度数目的子任务(SubTask),这些子任务就是作业调度的最小逻辑单元,对应于进程资源中的一个线程,在Flink中,就是一个Slot(如果不考虑Slot共享的话)。
假定Flink环境的并行度设置为1,作业的前面两个算子满足合并算子链的要求,且并行度设置为2;之后,通过keyBy()之类的算子完成了数据的Shuffle,然后再合并到同一个Sink中。那么它们的关系如下图所示:
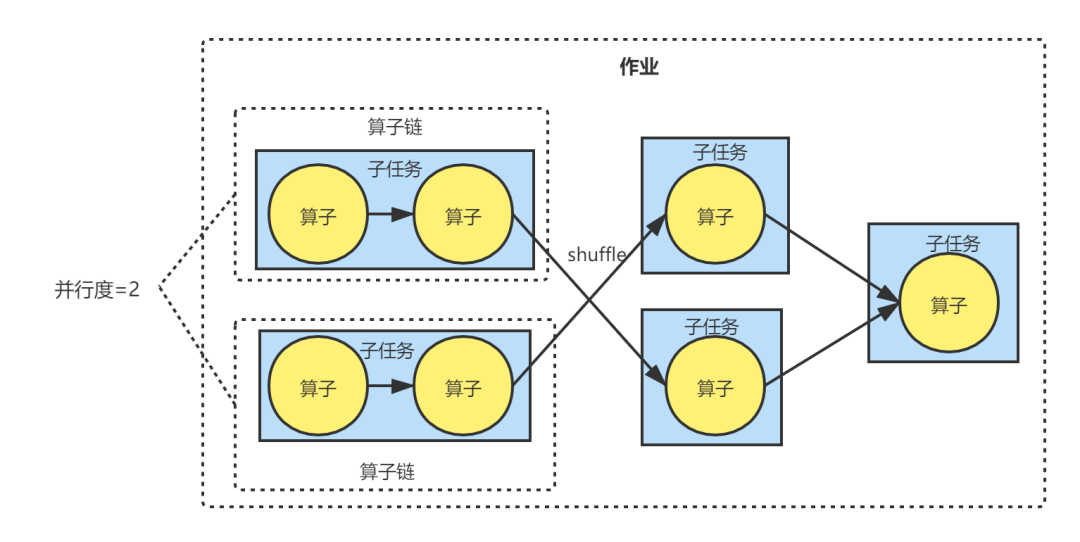
显然,Flink集群在执行作业时,会对作业进行划分,并将划分后的各个子任务分发到TaskManager中的每个Slot。一个TaskManager就是一个JVM,Slot则是进程中的一个线程。
答案不言而喻。AbstractFlow之所以无法捕获到各个算子执行任务时抛出的业务异常,是因为它们根本就没有执行在一个JVM上,也没有运行在同一个线程中。这正是分布式开发与本地开发的本质区别。如果不了解Flink的执行原理,可能就会困惑Java的异常处理机制为何不生效。在进行分布式开发时,如果还是照搬本地开发的经验,可能真的会撞得头碰血流才会看清真相。因此,正确的做法是在每个算子的实现中捕获各自的异常,也就是要保证每个算子自身都是健壮的,如此才能保证作业尽可能健壮。
当然,分布式开发与本地开发的本质区别不只限于此,例如分布式开发跨进程调用对序列化的要求,对数据一致性的不同要求,对异步通信机制以及阻塞调用的认识,都可能给程序员带来不同的体验。归根结底,了解分布式开发或分布式系统的底层原理,可以让我们尽早看到真相,避免调到坑里而不自知。



















