












本文转载自微信公众号「Golang梦工厂」,作者Golang梦工厂。转载本文请联系Golang梦工厂公众号。
前言
哈喽,大家好,我是asong。为什么会有今天这篇文章呢?前天在一个群里看到了一份Go语言面试的八股文,其中有一道题就是"字符串转成byte数组,会发生内存拷贝吗?";这道题挺有意思的,本质就是在问你string和[]byte的转换原理,考验你的基本功底。今天我们就来好好的探讨一下两者之间的转换方式。
byte类型
我们看一下官方对byte的定义:
- // byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
- // used, by convention, to distinguish byte values from 8-bit unsigned
- // integer values.
- type byte = uint8
我们可以看到byte就是uint8的别名,它是用来区分字节值和8位无符号整数值。
其实可以把byte当作一个ASCII码的一个字符。
示例:
- var ch byte = 65
- var ch byte = '\x41'
- var ch byte = 'A'
[]byte类型
[]byte就是一个byte类型的切片,切片本质也是一个结构体,定义如下:
- // src/runtime/slice.go
- type slice struct {
- array unsafe.Pointer
- len int
- cap int
- }
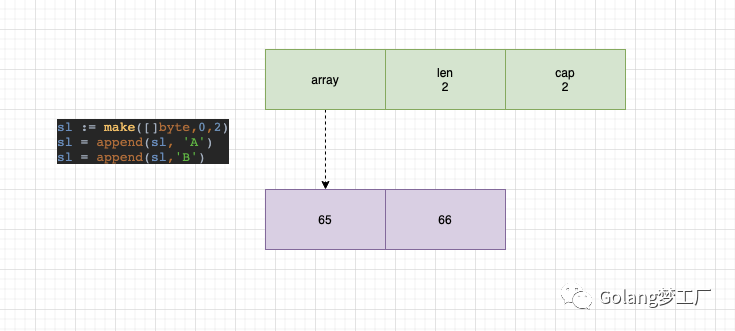
这里简单说明一下这几个字段,array代表底层数组的指针,len代表切片长度,cap代表容量。看一个简单示例:
- func main() {
- sl := make([]byte,0,2)
- sl = append(sl, 'A')
- sl = append(sl,'B')
- fmt.Println(sl)
- }
根据这个例子我们可以画一个图:
string类型
先来看一下string的官方定义:
- // string is the set of all strings of 8-bit bytes, conventionally but not
- // necessarily representing UTF-8-encoded text. A string may be empty, but
- // not nil. Values of string type are immutable.
- type string string
string是一个8位字节的集合,通常但不一定代表UTF-8编码的文本。string可以为空,但是不能为nil。string的值是不能改变的。
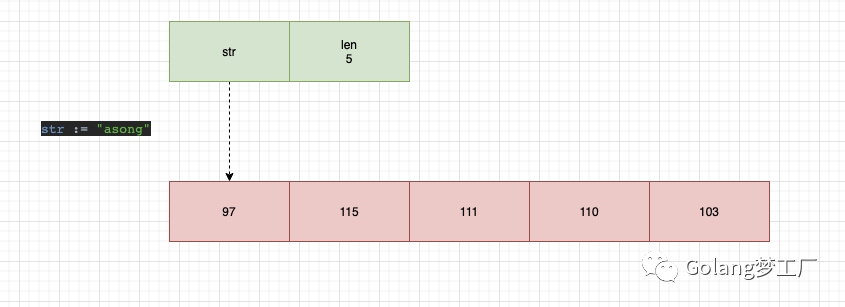
看一个简单的例子:
- func main() {
- str := "asong"
- fmt.Println(str)
- }
string类型本质也是一个结构体,定义如下:
- type stringStruct struct {
- str unsafe.Pointer
- len int
- }
stringStruct和slice还是很相似的,str指针指向的是某个数组的首地址,len代表的就是数组长度。怎么和slice这么相似,底层指向的也是数组,是什么数组呢?我们看看他在实例化时调用的方法:
- //go:nosplit
- func gostringnocopy(str *byte) string {
- ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)}
- s := *(*string)(unsafe.Pointer(&ss))
- return s
- }
入参是一个byte类型的指针,从这我们可以看出string类型底层是一个byte类型的数组,所以我们可以画出这样一个图片:
string和[]byte有什么区别
上面我们一起分析了string类型,其实他底层本质就是一个byte类型的数组,那么问题就来了,string类型为什么还要在数组的基础上再进行一次封装呢?
这是因为在Go语言中string类型被设计为不可变的,不仅是在Go语言,其他语言中string类型也是被设计为不可变的,这样的好处就是:在并发场景下,我们可以在不加锁的控制下,多次使用同一字符串,在保证高效共享的情况下而不用担心安全问题。
string类型虽然是不能更改的,但是可以被替换,因为stringStruct中的str指针是可以改变的,只是指针指向的内容是不可以改变的。看个例子:
- func main() {
- str := "song"
- fmt.Printf("%p\n",[]byte(str))
- str = "asong"
- fmt.Printf("%p\n",[]byte(str))
- }
- // 运行结果
- 0xc00001a090
- 0xc00001a098
我们可以看出来,指针指向的位置发生了变化,也就说每一个更改字符串,就需要重新分配一次内存,之前分配的空间会被gc回收。
string和[]byte标准转换
Go语言中提供了标准方式对string和[]byte进行转换,先看一个例子:
- func main() {
- str := "asong"
- by := []byte(str)
- str1 := string(by)
- fmt.Println(str1)
标准转换用起来还是比较简单的,那你知道他们内部是怎样实现转换的吗?我们来分析一下:
- string类型转换到[]byte类型
我们对上面的代码执行如下指令go tool compile -N -l -S ./string_to_byte/string.go,可以看到调用的是runtime.stringtoslicebyte:
- // runtime/string.go go 1.15.7
- const tmpStringBufSize = 32
- type tmpBuf [tmpStringBufSize]byte
- func stringtoslicebyte(buf *tmpBuf, s string) []byte {
- var b []byte
- if buf != nil && len(s) <= len(buf) {
- *buf = tmpBuf{}
- b = buf[:len(s)]
- } else {
- b = rawbyteslice(len(s))
- }
- copy(b, s)
- return b
- }
- // rawbyteslice allocates a new byte slice. The byte slice is not zeroed.
- func rawbyteslice(size int) (b []byte) {
- cap := roundupsize(uintptr(size))
- p := mallocgc(cap, nil, false)
- if cap != uintptr(size) {
- memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
- }
- *(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
- return
- }
这里分了两种状况,通过字符串长度来决定是否需要重新分配一块内存。也就是说预先定义了一个长度为32的数组,字符串的长度超过了这个数组的长度,就说明[]byte不够用了,需要重新分配一块内存了。这也算是一种优化吧,32是阈值,只有超过32才会进行内存分配。
最后我们会通过调用copy方法实现string到[]byte的拷贝,具体实现在src/runtime/slice.go中的slicestringcopy方法,这里就不贴这段代码了,这段代码的核心思路就是:将string的底层数组从头部复制n个到[]byte对应的底层数组中去
- []byte类型转换到string类型
[]byte类型转换到string类型本质调用的就是runtime.slicebytetostring:
- // 以下无关的代码片段
- func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
- if n == 0 {
- return ""
- }
- if n == 1 {
- p := unsafe.Pointer(&staticuint64s[*ptr])
- if sys.BigEndian {
- p = add(p, 7)
- }
- stringStructOf(&str).str = p
- stringStructOf(&str).len = 1
- return
- }
- var p unsafe.Pointer
- if buf != nil && n <= len(buf) {
- p = unsafe.Pointer(buf)
- } else {
- p = mallocgc(uintptr(n), nil, false)
- }
- stringStructOf(&str).str = p
- stringStructOf(&str).len = n
- memmove(p, unsafe.Pointer(ptr), uintptr(n))
- return
- }
这段代码我们可以看出会根据[]byte的长度来决定是否重新分配内存,最后通过memove可以拷贝数组到字符串。
string和[]byte强转换
标准的转换方法都会发生内存拷贝,所以为了减少内存拷贝和内存申请我们可以使用强转换的方式对两者进行转换。在标准库中有对这两种方法实现:
- // runtime/string.go
- func slicebytetostringtmp(ptr *byte, n int) (str string) {
- stringStructOf(&str).str = unsafe.Pointer(ptr)
- stringStructOf(&str).len = n
- return
- }
- func stringtoslicebytetmp(s string) []byte {
- str := (*stringStruct)(unsafe.Pointer(&s))
- ret := slice{array: unsafe.Pointer(str.str), len: str.len, cap: str.len}
- return *(*[]byte)(unsafe.Pointer(&ret))
- }
通过这两个方法我们可知道,主要使用的就是unsafe.Pointer进行指针替换,为什么这样可以呢?因为string和slice的结构字段是相似的:
- type stringStruct struct {
- str unsafe.Pointer
- len int
- }
- type slice struct {
- array unsafe.Pointer
- len int
- cap int
- }
唯一不同的就是cap字段,array和str是一致的,len是一致的,所以他们的内存布局上是对齐的,这样我们就可以直接通过unsafe.Pointer进行指针替换。
两种转换如何取舍
当然是推荐大家使用标准转换方式了,毕竟标准转换方式是更安全的!但是如果你是在高性能场景下使用,是可以考虑使用强转换的方式的,但是要注意强转换的使用方式,他不是安全的,这里举个例子:
- func stringtoslicebytetmp(s string) []byte {
- str := (*reflect.StringHeader)(unsafe.Pointer(&s))
- ret := reflect.SliceHeader{Data: str.Data, Len: str.Len, Cap: str.Len}
- return *(*[]byte)(unsafe.Pointer(&ret))
- }
- func main() {
- str := "hello"
- by := stringtoslicebytetmp(str)
- by[0] = 'H'
- }
运行结果:
- unexpected fault address 0x109d65f
- fatal error: fault
- [signal SIGBUS: bus error code=0x2 addr=0x109d65f pc=0x107eabc]
我们可以看到程序直接发生严重错误了,即使使用defer+recover也无法捕获。原因是什么呢?
我们前面介绍过,string类型是不能改变的,也就是底层数据是不能更改的,这里因为我们使用的是强转换的方式,那么by指向了str的底层数组,现在对这个数组中的元素进行更改,就会出现这个问题,导致整个程序down掉!
总结
本文我们一起分析byte和string类型的基本定义,也分析了[]byte和string的两种转换方式,应该还差最后一环,也就是大家最关心的性能测试,这个我没有做,我觉得没有很大意义,通过前面的分析就可以得出结论,强转换的方式性能肯定要比标准转换要好。对于这两种方式的使用,大家还是根据实际场景来选择,脱离场景的谈性能就是耍流氓!!!



















