kafka 是单条发送还是批量发送消息?
kafka 怎么做到单条发送?
kafka 发送消息是顺序的吗?
生产者什么情况下可能会频繁FullGC?
消息发送的逻辑
上帝视角来看消息发送的流程。

生产者的设计
消费发送机制:
1)序列化器:序列化消息对象转成字节数组,然后通过网络传输。
2)分区器:计算消息发往的具体分区;如果显示指定了partition,便不会走分区器。
3)消息缓冲池:客户端的消息缓冲池,默认大小32M,见参数buffer.memory。
4)批量发送:缓冲池中消息会按batch分批次发送,默认批次大小16KB,见参数batch.size。
负载均衡设计:
由于消息topic 由多个partition 组成,且partition 会均衡分布到不同broker 上。因此,为了有效利用broker 集群的性能,提高消息的吞吐量,producer 可以通过随机或者hash 等方式,将消息平均发送到多个partition 上,以实现负载均衡。
分区策略:
- 轮询策略,默认策略
- 随机策略,实际表现来看,它要逊于轮询策略
- 按消息键保序策略,一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的。
KafkaProducer
源码
- //客户端ID。在创建 KafkaProducer 时可通过 client.id 定义 clientId,如果未指定,则默认 producer- seq,seq 在进程内递增,强烈建议客户端显示指定 clientId。
- private final String clientId;
- //度量的相关存储容器,例如消息体大小、发送耗时等与监控相关的指标。
- final Metrics metrics;
- //分区负载均衡算法,通过参数 partitioner.class 指定。
- private final Partitioner partitioner;
- //调用 send 方法发送的最大请求大小,包括 key、消息体序列化后的消息总大小不能超过该值。通过参数 max.request.size 来设置。
- private final int maxRequestSize;
- //生产者缓存所占内存的总大小,通过参数 buffer.memory 设置。
- private final long totalMemorySize;
- //元数据信息,例如 topic 的路由信息,由 KafkaProducer 自动更新。
- private final Metadata metadata;
- //消息记录累积器
- private final RecordAccumulator accumulator;
- //用于封装消息发送的逻辑,即向 broker 发送消息的处理逻辑。
- private final Sender sender;
- //用于消息发送的后台线程,一个独立的线程,内部使用 Sender 来向 broker 发送消息。
- private final Thread ioThread;
- //压缩类型,默认不启用压缩,可通过参数 compression.type 配置。可选值:none、gzip、snappy、lz4、zstd。
- private final CompressionType compressionType;
- //错误信息收集器,当成一个 metrics,用来做监控的。
- private final Sensor errors;
- //用于获取系统时间或线程睡眠等。
- private final Time time;
- //用于对消息的 key 进行序列化。
- private final ExtendedSerializer<K> keySerializer;
- //Serializer< V> valueSerializer
- private final ExtendedSerializer<V> valueSerializer;
- //生产者的配置信息。
- private final ProducerConfig producerConfig;
- //最大阻塞时间,当生产者使用的缓存已经达到规定值后,此时消息发送会阻塞,通过参数 max.block.ms 来设置最多等待多久。
- private final long maxBlockTimeMs;
- //配置控制客户机等待请求响应的最长时间。如果在超时超时之前没有收到响应,客户端将在需要时重新发送请求,或者在重试耗尽时失败请求。
- private final int requestTimeoutMs;
- //生产者端的拦截器,在消息发送之前进行一些定制化处理。
- private final ProducerInterceptors<K, V> interceptors;
- //维护 api 版本的相关元信息,该类只能在 kafka 内部使用。
- private final ApiVersions apiVersions;
- //kafka 消息事务管理器。
- private final TransactionManager transactionManager;
- //kafka 生产者事务上下文环境初始结果。
- private TransactionalRequestResult initTransactionsResult;
KafkaProducer 具有如下特征:
- KafkaProducer 是线程安全的,可以被多个线程交叉使用。
- KafkaProducer 内部包含一个缓存池,存放待发送消息,即 ProducerRecord 队列,与此同时会开启一个IO线程将 ProducerRecord 对象发送到 Kafka 集群。
- KafkaProducer 的消息发送 API send 方法是异步,只负责将待发送消息 ProducerRecord 发送到缓存区中,立即返回,并返回一个结果凭证 Future。
acks 参数的作用
KafkaProducer 提供了一个核心参数 acks 用来定义消息“已提交”的条件(标准),就是 Broker 端向客户端承偌已提交的条件,可选值如下:
- 0:只要调用 KafkaProducer 的 send 方法返回后即认为成功
- all 或 -1:表示消息不仅需要 Leader 节点已存储该消息,并且要求其副本(准确的来说是 ISR 中的节点)全部存储才认为已提交,才向客户端返回提交成功。这是最严格的持久化保障,当然性能也最低。
- 1:表示消息只需要写入 Leader 节点后就可以向客户端返回提交成功。
retries 参数的作用
kafka 在生产端提供的另外一个核心属性,用来控制消息在发送失败后的重试次数,设置为 0 表示不重试,重试就有可能造成消息在发送端的重复。从消息发送接口来看:
- Future<RecordMetadata> send(ProducerRecord<K, V> record);Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
从上面的 API 可以得知,用户在使用 KafkaProducer 发送消息时,首先需要将待发送的消息封装成 ProducerRecord,返回的是一个 Future 对象,典型的 Future 设计模式。
Kafka 消息追加流程
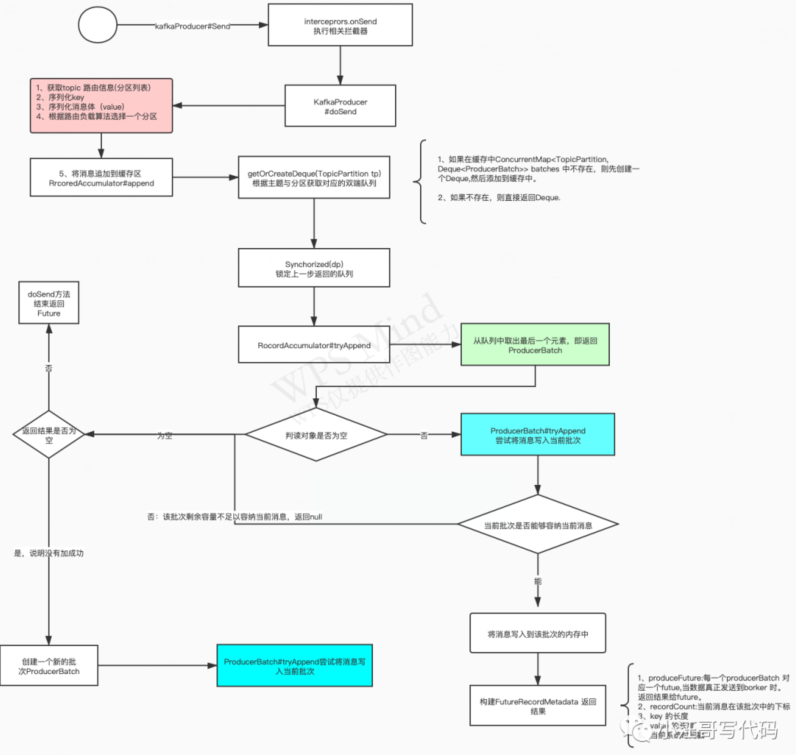
KafkaProducer 的 send 方法,并不会直接向 broker 发送消息,kafka 将消息发送异步化,即分解成两个步骤,send 方法的职责是将消息追加到内存中(分区的缓存队列中),然后会由专门的 Send 线程异步将缓存中的消息批量发送到 Kafka Broker 中。
主要的方法在KafkaProducer#doSend
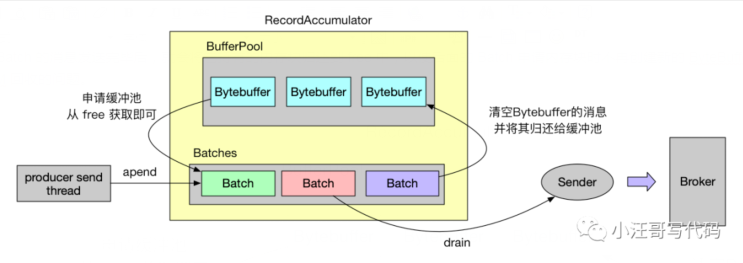
将消息追加到生产者的发送缓存区,其实现类为:RecordAccumulator。我们先来看一下 Kafka 一条消息写到内存的流程图:
Sender线程
到此为止,我们看到,当我们调用send 方法的时候,其实只是发送到了 生产者客户端的服务内存中。还没有到Broker。Kafka producer 客户端后台会启动一个线程不停的轮询消息批次存放的区域,把消息发送给Broker。
消息批次的内存结构和分配
根据上面的源码我们可以了解到,每一个ProducerBatch 是一块 大小为batch.size 字节大小的内存。而且用到了池化技术。
缓冲池的内存持有类是 BufferPool,我们先来看下 BufferPool 都有哪些成员:
- public class BufferPool {
- // 总的内存大小
- private final long totalMemory;
- // 每个内存块大小,即 batch.size
- private final int poolableSize;
- // 申请、归还内存的方法的同步锁
- private final ReentrantLock lock;
- // 空闲的内存块
- private final Deque<ByteBuffer> free;
- // 需要等待空闲内存块的事件
- private final Deque<Condition> waiters;
- /** Total available memory is the sum of nonPooledAvailableMemory and the number of byte buffers in free * poolableSize. */
- // 缓冲池还未分配的空闲内存,新申请的内存块就是从这里获取内存值
- private long nonPooledAvailableMemory;
- // ...
- }
从 BufferPool 的成员可看出,缓冲池实际上由一个个 ByteBuffer 组成的,BufferPool 持有这些内存块,并保存在成员 free 中,free 的总大小由 totalMemory 作限制,而 nonPooledAvailableMemory 则表示还剩下缓冲池还剩下多少内存还未被分配。
当 Batch 的消息发送完毕后,就会将它持有的内存块归还到 free 中,以便后面的 Batch 申请内存块时不再创建新的 ByteBuffer,从 free 中取就可以了,从而避免了内存块被 JVM 回收的问题。
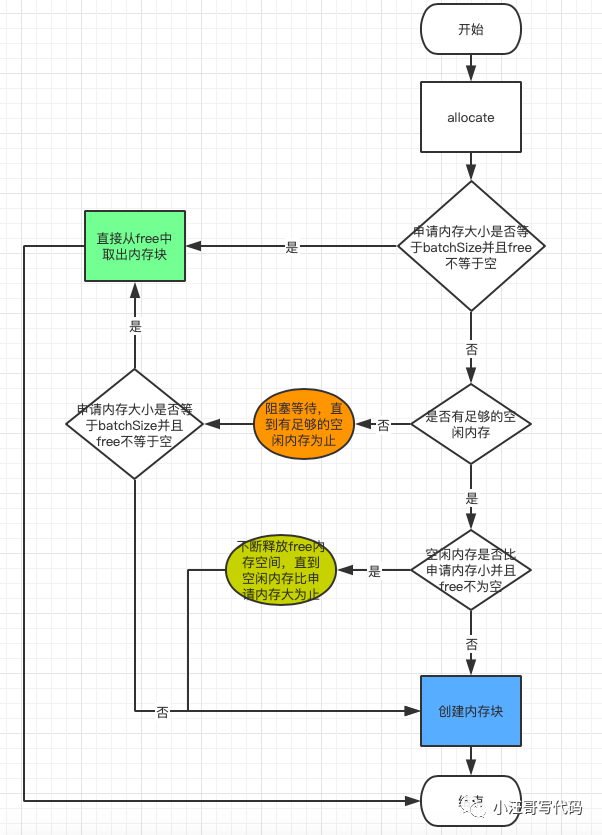
创建内存块的流程如下:
归还内存块的逻辑流程
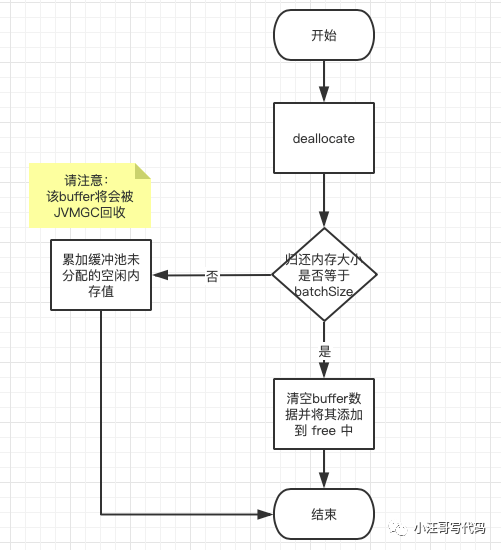
如果归还的内存块大小等于 batchSize,则将其清空后添加到缓冲池的 free 中,即将其归还给缓冲池,避免了 JVM GC 回收该内存块。如果不等于就直接将内存大小累加到未分配并且空闲的内存大小值中即可,内存就无需归还了,等待 JVM GC 回收掉,最后唤醒正在等待空闲内存的线程。
Java生产者是如何管理TCP连接的
为何采用 TCP?
Apache Kafka 的所有通信都是基于 TCP 的,而不是基于 HTTP 或其他协议。无论是生产者、消费者,还是 Broker 之间的通信都是如此。
从社区的角度来看,在开发客户端时,人们能够利用 TCP 本身提供的一些高级功能,比如多路复用请求以及同时轮询多个连接的能力。
TCP 的多路复用请求会在一条物理连接上创建若干个虚拟连接,每个虚拟连接负责流转各自对应的数据流。其实严格来说,TCP 并不能多路复用,它只是提供可靠的消息交付语义保证,比如自动重传丢失的报文。
而且目前已知的 HTTP 库在很多编程语言中都略显简陋。
何时创建 TCP 连接?
TCP 连接是在创建 KafkaProducer 实例时建立的 ,在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender 线程开始运行时首先会创建与 Broker 的连接。
- Properties properties = new Properties();
- properties.put("bootstrap.servers", "localhost:9092");
- properties.put("key.serializer", StringSerializer.class.getName());
- properties.put("value.serializer", StringSerializer.class.getName());
- // try-with-resources
- // 创建KafkaProducer实例时,会在后台创建并启动Sender线程,Sender线程开始运行时首先会创建与Broker的TCP连接
- try (Producer<String, String> producer = new KafkaProducer<>(properties)) {
- ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, KEY, VALUE);
- Callback callback = (metadata, exception) -> {
- };
- producer.send(record, callback);
- }
- bootstrap.servers是Producer的核心参数之一,指定了Producer启动时要连接的Broker地址
- 如果bootstrap.servers指定了1000个Broker,那么Producer启动时会首先创建与这1000个Broker的TCP连接
- 因此不建议把集群中所有的Broker信息都配置到bootstrap.servers中,通常配置3~4台足够
- Producer一旦连接到集群中的任意一台Broker,就能拿到整个集群的Broker信息(metadata request)
TCP 连接还可能在两个地方被创建:一个是在更新元数据后,另一个是在消息发送时。
- 当Producer更新了集群的元数据后,如果发现与某些Broker当前没有连接,那么Producer会创建一个TCP连接
【场景1】
当Producer尝试向不存在的主题发送消息时,Broker会告诉Producer这个主题不存在,此时Producer会发送metadata request到Kafka集群,去尝试获取最新的元数据信息,与集群中所有的Broker建立TCP连接。
【场景2】
Producer通过metadata.max.age.ms参数定期地去更新元数据信息,默认值300000,即5分钟。
- 当Producer要发送消息时,Producer发现与目标Broker(依赖负载均衡算法)还没有连接,也会创建一个TCP连接。
何时关闭 TCP 连接?
Producer端关闭TCP连接有两种方式:用户主动关闭、Kafka自动关闭。
【用户主动关闭】
广义的主动关闭,包括用户调用kill -9来杀掉Producer,最推荐的方式:producer.close()
【Kafka自动关闭】
Producer端参数connections.max.idle.ms,默认值540000,即9分钟
如果9分钟内没有任何请求经过某个TCP连接,Kafka会主动把TCP连接关闭
connections.max.idle.ms=-1会禁用这种机制,TCP连接将成为永久长连接
Kafka创建的Socket连接都开启了keepalive。
【注意】
关闭TCP连接的发起方是Kafka客户端,属于被动关闭的场景
被动关闭的后果就是会产生大量的CLOSE_WAIT连接
Producer端或Client端没有机会显式地观测到此TCP连接已被中断
总结
现在我们可以回答开头的3个问题了。
1、kafka 是单条发送还是批量发送消息?
正常情况下都是批量发送的。封装成一个ProducerBatch 发送。
2.kafka 怎么做到单条发送?
只能设置单生产者单线程同步调用send 方法。
3.kafka 发送消息是顺序的吗?
不是的,如果需求顺序必须设置key,并且是生产者是单线程的。
4.生产者什么情况下可能会频繁FullGC?
如果你的消息大小比 batchSize 还要大,则不会从 free 中循环获取已分配好的内存块,而是重新创建一个新的 ByteBuffer,并且该 ByteBuffer 不会被归还到缓冲池中(JVM GC 回收),如果此时 nonPooledAvailableMemory 比消息体还要小,还会将 free 中空闲的内存块销毁(JVM GC 回收),以便缓冲池中有足够的内存空间提供给用户申请,这些动作都会导致频繁 GC 的问题出现。
因此,需要根据业务消息的大小,适当调整 batch.size 的大小,避免频繁 GC。