












本文转载自微信公众号「码上Java」,作者码上Java。转载本文请联系码上Java公众号。
前言
面试中经常被问到索引相关的问题,其实索引这个概念非常好理解,我们在上学的时候都肯定用过字典吧。索引就像字典的那个目录,我们可以借助目录快速检索到我们所需要的字的解释。同样的道理,在数据库中,索引也可以帮助我们快速检索到我们所需要的数据,而且查询的效率非常高。
总的来说,索引就是一种数据结构,我们今天一起来探究一下索引到底什么什么样的?为什么我们常用B+树最为索引的数据结构呢?
为什么有了索引查询就会变快?
我们都知道数据库存储有两种存储介质,一个是内存,另一个是硬盘。内存是一种临时性存储介质,而且容量也非常有限,如果服务器断电的话,会导致数据丢失。硬盘是一种永久性存储介质(如果不损坏的话),所以说我们需要把数据存放在硬盘里面才安全。
但是有个问题?如果我们把数据放在硬盘里面的话,我们对其中数据进行查询的时候,就会产生硬盘的I/O操作。相比于内存存取来说的话,硬盘在存取时I/O消耗的时间要高很多。而索引的作用就是尽量减少硬盘的I/O操作,从而降低花费的时间。你可以对比查字典的操作,目录(索引)可以帮你减少翻页的动作,一个道理。
先聊聊二叉树
二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。
我们先来看下一个最基础的二叉搜索树(Binary Search Tree),搜索某个节点和插入节点的规则一样,我们假设搜索插入的数值为 key:
- 如果 key 大于根节点,则在右子树中进行查找;
- 如果 key 小于根节点,则在左子树中进行查找;
- 如果 key 等于根节点,也就是找到了这个节点,返回根节点即可。
我们举个例子,创建数列{30,25,36,32,40,20,28},同样的数据,不同的插入顺序,树的结果是不一样的,如下图所示:
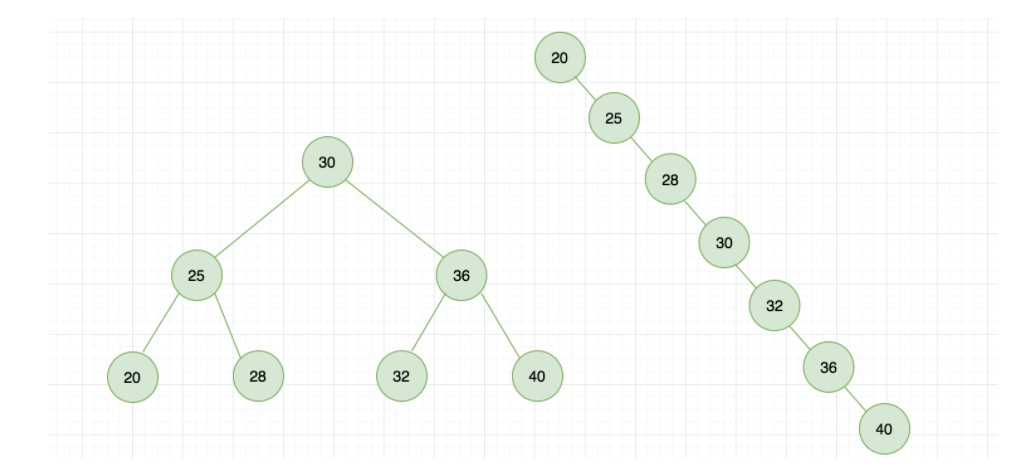
但是存在极端的情况,当二叉树的深度非常大可能会退化成链表。上图中能看出来第一个树的深度是 3,也就是说最多只需 3 次比较,就可以找到节点,而第二个树的深度是 7,最多需要 7 次比较才能找到节点。
图中的右边也属于二分查找树,但是性能方面已经退化成了链表,查找数据的时间复杂度变成了 O(n)。这个问题怎么解决呢?,人们提出了平衡二叉搜索树(AVL 树),它在二分搜索树的基础上增加了约束,保证每个节点的左子树和右子树的高度差不能超过 1,也就是说节点的左子树和右子树仍然为平衡二叉树。
这里说一下,常见的平衡二叉树有很多种,包括了平衡二叉搜索树、红黑树、数堆、伸展树。平衡二叉搜索树是最早提出来的自平衡二叉搜索树,当我们提到平衡二叉树时一般指的就是平衡二叉搜索树。事实上,第一棵树就属于平衡二叉搜索树,搜索时间复杂度就是 O(log2n)。
上文中我们提到过查询时间的多少主要取决于硬盘的I/O操作,如果我们采用二叉树的形式,即使通过平衡二叉搜索树进行了改良,树的深度也是 O(log2n),当 n 比较大时,深度也是比较高的,比如下图的情况:
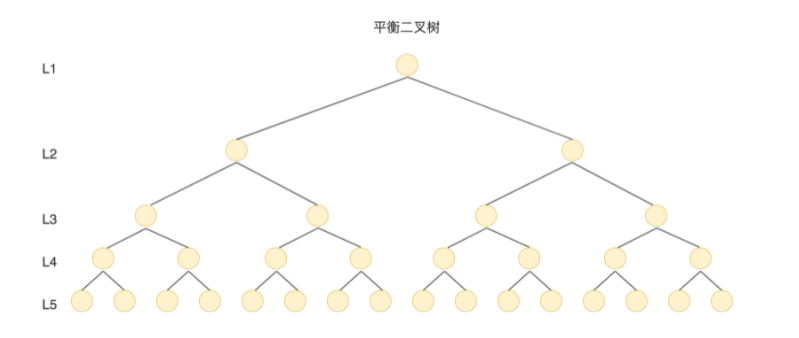
每访问一次节点就需要进行一次磁盘 I/O 操作,对于上面的树来说,我们需要进行 5 次 I/O 操作。虽然平衡二叉树比较的效率高,但是树的深度也同样高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
再看看什么是 B 树
在上文中,我们知道了如果二叉树作为索引会导致树变的很高,增加硬盘的 I/O 次数,影响数据查询的时间。B 树的出现就是为了解决这个问题,B 树的英文是 Balance Tree,也就是平衡的多路搜索树,它的高度远小于平衡二叉树的高度。在文件系统和数据库系统中的索引结构经常采用 B 树来实现。
我们来看看B树结构示意图,如下图所示:
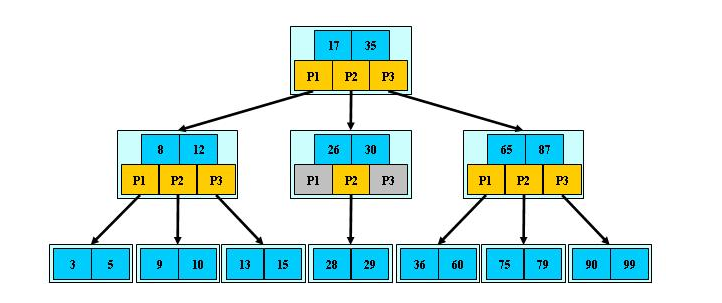
B 树作为平衡的多路搜索树,它的每一个节点最多可以包括 M 个子节点,M 称为 B 树的阶。在图中你可以看到,每个磁盘块中包括了关键字和子节点的指针。如果一个磁盘块中包括了 x 个关键字,那么指针数就是 x+1。对于一个 100 阶的 B 树来说,如果有 3 层的话最多可以存储约 100 万的索引数据。对于大量的索引数据来说,采用 B 树的结构是非常适合的,因为树的高度要远小于二叉树的高度。
结合B树结构示意图,我们来一起看看B树是如何进行搜索的,假设我们想要查找的关键字是 9,那么步骤可以分为以下几步:
- 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
- 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
- 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行比较所需要的时间要多,是数据查找用时的重要因素,B 树相比于平衡二叉树来说磁盘 I/O 操作要少,在数据查询中比平衡二叉树效率要高。
B树Plus(B+ 树)
- B+ 树是基于B 树改良过来的,目前主流的数据库都支持B+ 树作为索引方式,我们以MySQL为例,对比一下B+ 树和B树有哪些区别:
- B+ 树中,有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- B+ 树中,非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中,非叶子节点既保存索引,也保存数据记录。
所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
下图就是一棵 B+ 树,阶数为 3,根节点中的关键字 1、18、35 分别是子节点(1,8,14),(18,24,31)和(35,41,53)中的最小值。每一层父节点的关键字都会出现在下一层的子节点的关键字中,因此在叶子节点中包括了所有的关键字信息,并且每一个叶子节点都有一个指向下一个节点的指针,这样就形成了一个链表。
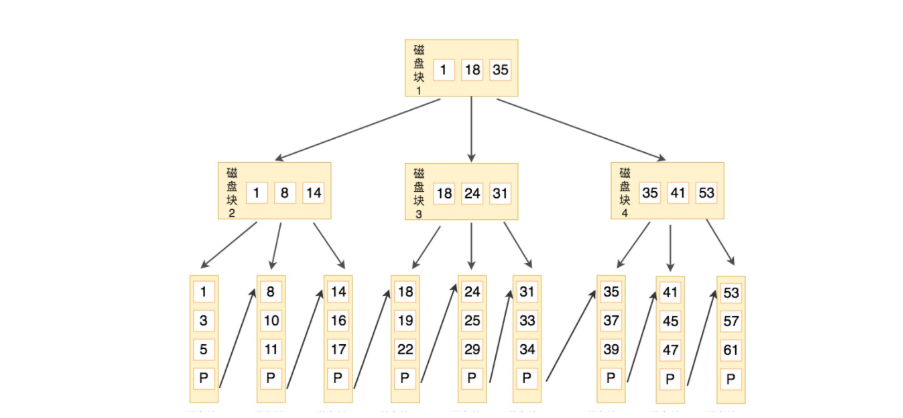
比如,我们想要查找关键字 16,B+ 树会自顶向下逐层进行查找:
- 与根节点的关键字 (1,18,35) 进行比较,16 在 1 和 18 之间,得到指针 P1(指向磁盘块 2)
- 找到磁盘块 2,关键字为(1,8,14),因为 16 大于 14,所以得到指针 P3(指向磁盘块 7)
- 找到磁盘块 7,关键字为(14,16,17),然后我们找到了关键字 16,所以可以找到关键字 16 所对应的数据。
整个过程一共进行了 3 次 I/O 操作,看起来 B+ 树和 B 树的查询过程差不多,但是 B+ 树和 B 树有个根本的差异在于,B+ 树的中间节点并不直接存储数据。这样的好处都有什么呢?
首先,B+ 树查询效率更稳定。因为 B+ 树每次只有访问到叶子节点才能找到对应的数据,而在 B 树中,非叶子节点也会存储数据,这样就会造成查询效率不稳定的情况,有时候访问到了非叶子节点就可以找到关键字,而有时需要访问到叶子节点才能找到关键字。
其次,B+ 树的查询效率更高,这是因为通常 B+ 树比 B 树更矮胖(阶数更大,深度更低),查询所需要的磁盘 I/O 也会更少。同样的磁盘页大小,B+ 树可以存储更多的节点关键字。
不仅是对单个关键字的查询上,在查询范围上,B+ 树的效率也比 B 树高。这是因为所有关键字都出现在 B+ 树的叶子节点中,并通过有序链表进行了链接。而在 B 树中则需要通过中序遍历才能完成查询范围的查找,效率要低很多。
总结
磁盘的 I/O 操作次数对索引的使用效率至关重要。虽然传统的二叉树数据结构查找数据的效率高,但很容易增加磁盘 I/O 操作的次数,影响索引使用的效率。因此在构造索引的时候,我们更倾向于采用“矮胖”的数据结构。
B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树,B+ 树在查询性能上更稳定,在磁盘页大小相同的情况下,树的构造更加矮胖,所需要进行的磁盘 I/O 次数更少,更适合进行关键字的范围查询。



















